1. 概述
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种基于 7 位二进制数的标准编码系统,用于表示 128 个字符,包括图形字符和控制字符。
具体来说,ASCII 表中包含 95 个图形字符,包括大小写拉丁字母、常用标点符号、数学符号和阿拉伯数字;
此外,还有 33 个控制字符,这些字符用于控制信息的处理和提供元数据。
在本文中,我们会先回顾 ASCII 的历史背景和文档规范,接着深入 ASCII 表的结构,了解字符是如何被编码的。然后,我们会演示如何将字符从可读形式转换为十进制 ASCII 编码,再进一步转换为二进制形式,反之亦然。最后,我们还会介绍一些常见的 ASCII 变体及其应用场景。
2. 历史背景
ASCII 的设计灵感来源于早期电报传输中使用的编码方式。它最初是为 7 位电传打字机设计的,但开发者也考虑了其他设备的兼容性。
1963 年,美国标准协会(即现在的 ANSI)首次提出 ASCII 标准,并在后续多次修订中不断完善。
ASCII 的优势在于其编码结构清晰有序,不仅包含电报通信所需字符,还扩展了其他用途的代码。这使得它在 1968 年成为美国联邦政府的计算机通信标准。
随着互联网的发展,ASCII 被广泛应用于电子邮件和 HTML 页面的字符编码中。
但从 2008 年起,UTF-8 编码逐渐取代了 ASCII 成为互联网上最常用的编码方式。不过,UTF-8 是 ASCII 的超集,前 128 个字符与 ASCII 完全一致,只是在此基础上扩展了更多字符。
3. ASCII 编码详解
ASCII 是一种 7 位编码系统,共包含 128 个字符,其中:
- 图形字符(95 个):包括字母、数字、标点符号等;
- 控制字符(33 个):用于控制设备行为或信息处理。
这些字符通常以 ASCII 表的形式展示,表中每个字符都有对应的十进制和二进制编码:
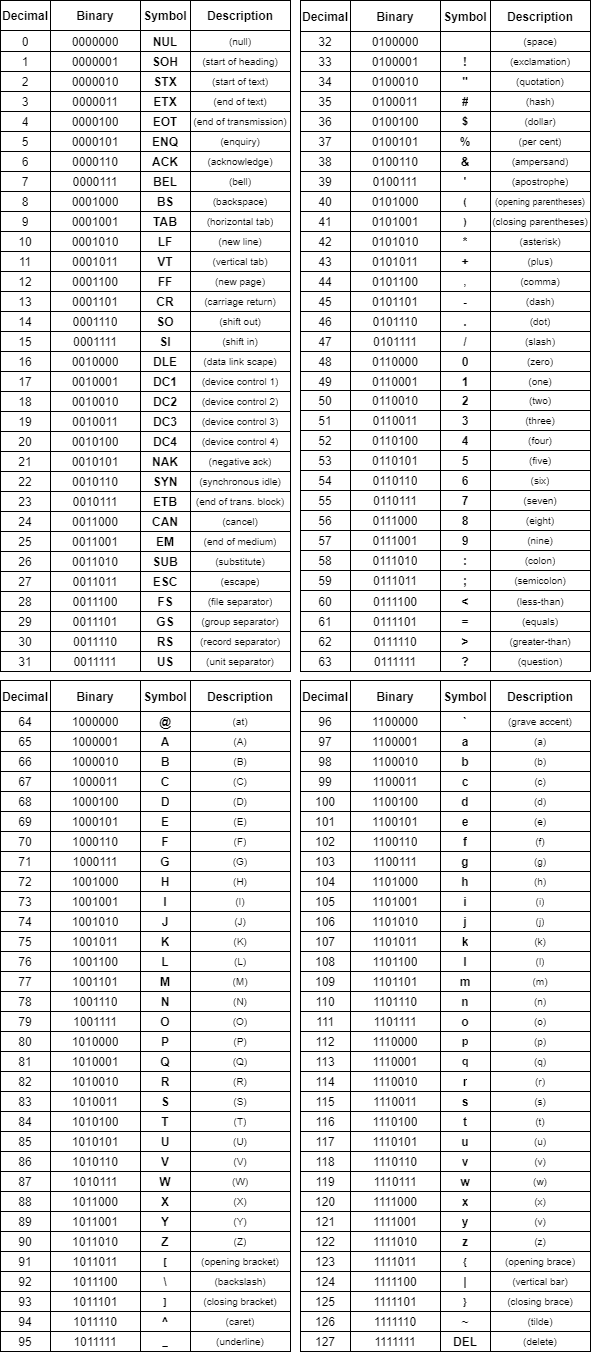
ASCII 表中,控制字符主要分布在 0 到 31 的范围内,唯一例外是 DEL(127),它用于表示删除操作。这与早期打字机的工作方式有关:打字错误无法回退,只能通过在错误位置打上全孔(即 DEL 码)来标记忽略。
图形字符则分布在 32 到 126 的范围内,其中空格字符(32)虽然不可见,但被归类为图形字符。
值得一提的是,ASCII 字符的排序方式称为 ASCIIbetical,其规则如下:
- 数字在前;
- 大写字母在小写字母之前(例如 'Z' 在 'a' 之前);
- 其他符号分布在字母和数字之间。
4. ASCII 编码与解码过程
ASCII 的编码过程就是将可读字符转换为对应的二进制或十进制代码;而解码则是反过来,将代码还原为可读字符。
4.1 将字符串编码为二进制 ASCII
以字符串 “Baeldung” 为例,演示如何将其逐字符转换为二进制 ASCII 编码:
- 查找 ASCII 表,获取每个字符对应的十进制编码:
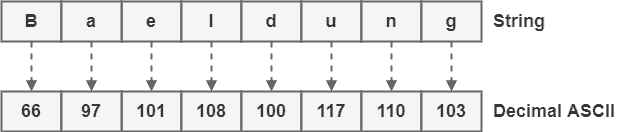
注意:ASCII 是区分大小写的,例如 “B”(66)和 “b”(98)是不同的字符。
- 将十进制转换为 7 位二进制编码:
每个二进制位表示一个 2 的幂次方值,从右到左依次为 2⁰ 到 2⁶。例如:

转换结果如下:
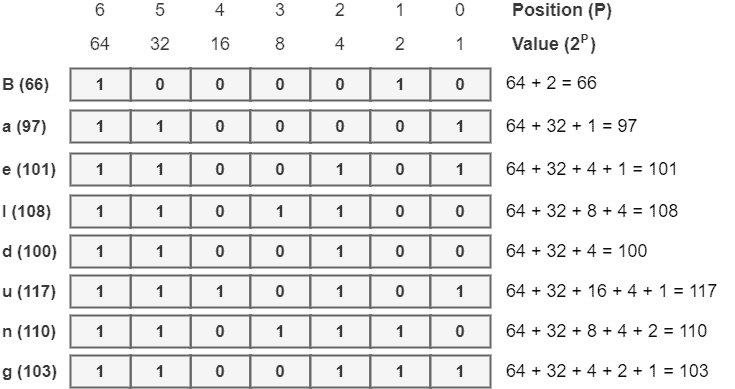
最终,“Baeldung” 的二进制 ASCII 编码为:
1000010 1100001 1100101 1101100 1100100 1110101 1101110 1100111
4.2 将二进制 ASCII 解码为字符串
以如下二进制 ASCII 编码为例:
1010011 1100011 1101001 1100101 1101110 1100011 1100101
解码步骤如下:
- 将每个 7 位二进制数转换为十进制:
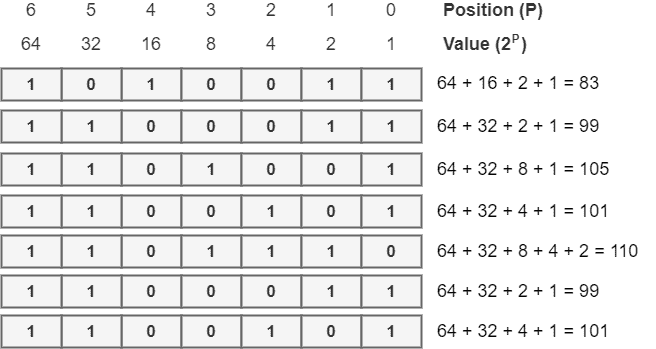
- 根据 ASCII 表查找对应字符:
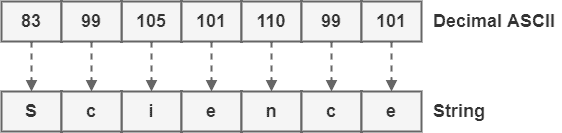
最终结果为字符串:
Science
5. ASCII 的变体
随着计算机技术的发展,为了支持更多语言和字符集,不同标准化组织对 ASCII 进行了扩展,形成了多种变体。
常见的变体包括:
✅ Windows-1252:
- 单字节编码;
- 在 ASCII 基础上扩展 123 个字符;
- 支持西欧语言字符(如带变音符号的字母);
- 当前仅有 5 个代码未使用。
✅ UTF-8:
- 单字节编码;
- 扩展 128 个字符;
- 与 Windows-1252 类似,但扩展字符和编码方式不同;
- 是 Unicode 标准的一部分;
- 可使用 1~4 字节表示字符(ASCII 兼容部分为单字节)。
这些扩展编码保留了 ASCII 的前 128 个字符不变,仅对后续部分进行了扩展。
6. 总结
ASCII 是计算机编码系统的基础之一,尽管如今已被更广泛的 UTF-8 所取代,但它仍然构成了现代编码体系的核心部分。
本文内容回顾如下:
- ASCII 是 7 位编码系统,包含 128 个字符;
- 图形字符和控制字符各占一部分;
- 编码和解码过程清晰明确;
- ASCII 表结构有序,便于查找;
- 常见变体如 Windows-1252 和 UTF-8 都基于 ASCII 扩展而来。
✅ 总结一句话:ASCII 是现代编码标准的基石,即使在 UTF-8 广泛使用的今天,它仍然不可或缺。