1. 概述
在本篇文章中,我们将探讨一个非常流行的机器学习算法——随机森林(Random Forest),并深入理解其一个重要概念:袋外误差(Out-of-Bag Error)。
同时,我们也会简要介绍与随机森林相关的几个术语,例如决策树(Decision Tree)、装袋(Bagging)和自助法(Bootstrapping)。
2. 随机森林简介
随机森林是一种用于分类和回归任务的集成学习方法。它通过构建多个决策树来形成一个综合预测模型,具有良好的准确性、快速的训练速度以及良好的可解释性,是当前最受欢迎的机器学习算法之一。
首先,随机森林使用了一种叫做装袋(Bagging)的集成技术。
Bagging 是一种用于降低模型在噪声数据上训练时方差的技术。它通过创建多个模型,每个模型都能补偿其他模型的错误。简而言之,随机森林由许多决策树组成,最终的预测结果是这些树的多数投票(分类)或平均预测(回归):
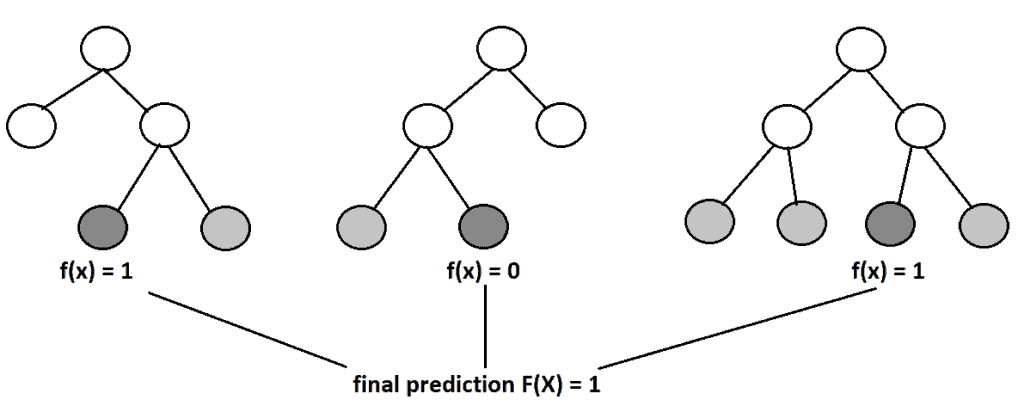
其次,随机森林还使用了一种叫做自助法(Bootstrapping)的技术。
这是统计学中常用的一种方法,用于减少机器学习模型的方差。简单来说,它会从原始数据集中随机采样一个子集用于构建每棵决策树,且采样是有放回的(with replacement),这意味着同一个样本可能被多次选中。
最后,为了进一步提高模型的泛化能力,随机森林还限制了用于节点分裂的特征数量。在构建决策树时,每次分裂只考虑一个随机选择的特征子集。在 Python 的 scikit-learn 库中,这个超参数被称为 max_features,通常推荐设置为:
- 分类任务:
max_features = sqrt(n) - 回归任务:
max_features = n / 3
其中 n 表示特征总数。
3. 袋外误差(Out-of-Bag Error)
在机器学习和数据科学中,我们希望构建一个在新数据上表现良好的模型。为了评估模型的泛化能力,有很多方法可以使用,袋外误差(OOB Error) 就是其中一种。
3.1. 定义
OOB Error 利用了随机森林中 Bootstrapping 的特性。由于 Bootstrapping 是有放回采样,因此每棵树训练时只使用了原始数据集中的一部分样本,剩下的未被选中的样本就被称为“袋外样本”(Out-of-Bag Samples)。
我们可以利用这些未被使用的样本来评估每棵树的预测性能。最终,将所有树在各自袋外样本上的预测结果进行汇总,就可以得到整个随机森林模型的 OOB 误差。
这种评估方式相比传统的训练集/测试集划分或交叉验证更为高效,而且结果也具有较高的可信度。
3.2. 袋外样本出现的概率
理论上,在数据集足够大的情况下,大约有 36.8% 的样本不会被选中用于某棵树的训练,这些就是袋外样本。
我们可以通过概率公式来解释:
- 从一个大小为
n的训练集中选择一个样本的概率是1/n - 不选中该样本的概率是
1 - 1/n - 经过
n次有放回的采样后,该样本未被选中的概率是(1 - 1/n)^n
当 n 很大时,极限值为:
(1) $$ \lim_{n \to \infty}\left(1-\frac{1}{n}\right)^{n} = e^{-1} \approx 0.36 $$
因此,大约 36% 的样本会被保留用于 OOB 误差的计算。
3.3. 伪代码实现
下面是一个用于计算 OOB 误差的伪代码示例:
algorithm OutOfBagError(S, k):
// INPUT
// S = 用于训练的数据集
// k = 随机森林中树的数量
// OUTPUT
// 使用 OOB 预测计算出的平均性能或误差
初始化训练数据集 S
构建一个包含 k 棵树的随机森林
使用数据集 S 训练随机森林
for 每棵决策树 Ti in 随机森林:
Si = 用于训练 Ti 的自助采样数据集
Sc = S \ Si (即 Ti 的 OOB 样本)
Pi = 使用 Ti 对 Sc 的预测结果
使用预测结果 P = {P1, P2, ..., Pk} 计算平均性能或误差
return 平均性能或误差
更直观地展示整个过程如下图所示:
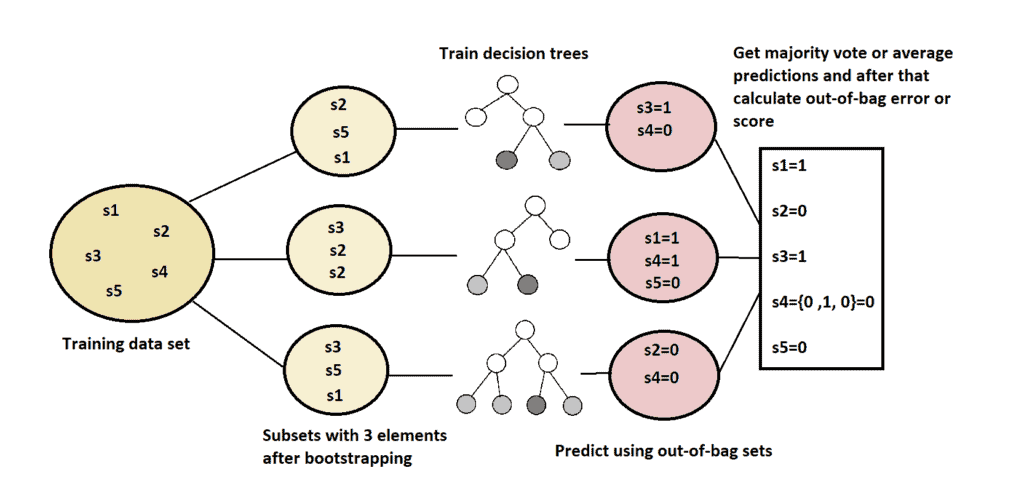
4. 总结
本文我们介绍了如何使用袋外误差(OOB Error)来评估随机森林模型的性能。
OOB Error 是一种高效的模型验证方法,其效果在很多论文中被实验证明与使用测试集相当。而且,它不需要单独划分训练集和测试集,因此在小数据集上尤其有用,可以让模型在更多数据上进行训练,提升模型的泛化能力。
✅ 优点总结:
- 不需要额外划分测试集
- 实现简单,计算开销小
- 在小数据集上表现良好
❌ 注意事项:
- OOB 误差的估计可能略高于交叉验证的结果
- 对于高维稀疏数据,OOB 误差可能不够准确
💡 踩坑提醒:
如果你在使用随机森林时忽略了 OOB 误差,那你可能错失了一个非常方便且有效的模型评估工具。建议在训练模型时始终启用 OOB 误差计算,特别是在数据量较小的情况下。