1. Introduction
“Software architecture is the art of drawing lines that I call boundaries. Those boundaries separate software elements from one another, and restrict those on one side from knowing about those on the other.” – Robert C. Martin. This quote, extracted from Uncle Bob’s Clean Architecture book, perfectly illustrates the essence of boundaries in software development.
In this tutorial, we’ll explore the concept of boundaries and their importance at various levels of software architecture.
2. Importance of Boundaries
Boundaries between different parts of our system enable each part to operate independently. This separation facilitates easier development, deployment, and testing of the system. By creating clear boundaries, we gain flexibility, allowing us to maintain the system more effectively and avoid the pitfalls of a “big ball of mud” — a system with tangled, unmanageable code.
Next, let’s explore a fundamental concept in software engineering: “Low Coupling, High Cohesion“.
2.1. Low Coupling, High Cohesion
Coupling and cohesion are two related concepts, developed by Larry Constantine in the late 1960s. We generally aim to have low coupling and high cohesion between our modules. The size of the module can vary greatly, ranging from the size of a class to an entire service in the context of a distributed architecture. Next, we’ll describe each concept and see how having low coupling and high cohesion helps us.
2.2. Coupling
Coupling is the degree of interdependence between software modules. Two modules are highly coupled if they are closely connected. In other words, if a change in one module triggers a change in the other module, we can say those two modules are highly coupled. Conversely, modules with low coupling are quite independent from each other.
Loosely coupled modules are easier to develop and maintain, offering more flexibility. Due to the independence between them, we can build, test, and deploy one module without affecting others. They can also be modified and updated independently, which is crucial in complex architectures.
These advantages are lost if we have a high degree of coupling between the parts of our system. Updating one module becomes difficult because it triggers chained updates in other modules. Additionally, testing becomes very challenging because we need to mock many calls or test modules together.
Therefore, having loosely coupled modules reflects the higher quality of our system. We should aim to design modules that are as independent as possible. However, a low degree of coupling is generally accepted, because it’s very difficult to have all modules completely decoupled.
It’s also important to note that tightly coupled modules are not always bad. We can tolerate a higher degree of coupling between highly cohesive elements, which we’ll explore in the next subsection.
2.3. Cohesion
Cohesion is the degree to which elements inside a module belong together. Simply put, “the code that changes together, stays together”. A highly cohesive module contains only elements that are tightly related to each other. Conversely, a module with low cohesion contains unrelated elements. The concept of cohesion is related to the Single Responsibility Principle, which states that a module should have only one responsibility and, consequently, only one reason to change.
Modules with high cohesion contribute significantly to maintainability. These modules are easier to understand and update because all related code is encapsulated within the module. High cohesion simplifies development, testing, and deployment processes, as changes are limited to a single, self-contained module.
Just as with low coupling, high cohesion is an indicator of high-quality system design. When modules are well-defined and cohesive, the overall system architecture becomes more robust, flexible, and easier to manage.
3. Types of Boundaries
The concept of boundaries is very broad in software development. Boundaries can exist at various levels, from the source code level to independent services in distributed architectures. Each type of boundary serves a different purpose and helps manage complexity in its own way.
Today, we will focus on boundaries at the source code level. Understanding these boundaries is crucial for building modular and maintainable applications.
4. Source Code Boundaries
Now that we are focusing on boundaries at the source code level, we can explore several key types. Furthermore, we’ll describe them from an object-oriented programming language perspective.
4.1. Encapsulation
Encapsulation is the practice of hiding the internal details and exposing only what is necessary through a well-defined interface. While commonly associated with hiding the members of a class from other classes, encapsulation can also apply to entire packages or modules by selectively exposing certain functionalities.
This principle simplifies the usage of the target by concealing its internal complexity. Additionally, encapsulation allows internal changes without affecting external code that depends on the target, which is a crucial advantage for maintainability. By limiting access to certain components, encapsulation also enhances security and reduces the risk of unintended interference with the internal workings of a class or module.
4.2. Layering
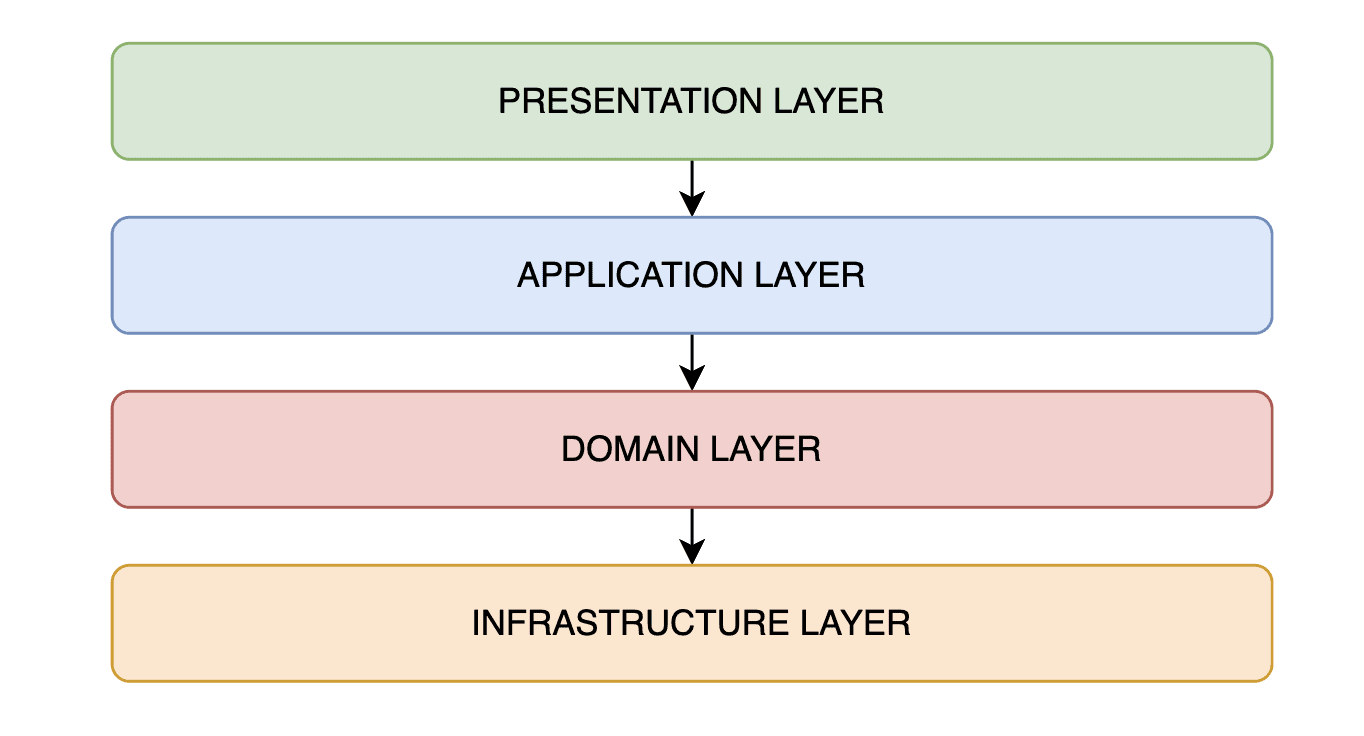
Layered architecture is a design approach where the application is divided into separate horizontal layers that function together as a single unit. Common layers include:
- Presentation Layer
- Application/Business Layer
- Domain Layer
- Infrastructure/Persistence/Database Layer
Each layer in this architecture has a specific role, creating boundaries based on technical functionalities. This separation enhances modularity, promotes code organization, and improves readability.
However, while each layer is designed to be independent in terms of its role, there is an inherent dependency between layers. For example, each layer depends on the layer above it. This dependency means that while layers are logically separated, they are not completely decoupled:
4.3. Vertical Slicing
Vertical slicing is an approach that organizes the system based on business capabilities rather than technical layers. In this approach, each vertical slice crosses all necessary horizontal layers to deliver a specific business function or use case:
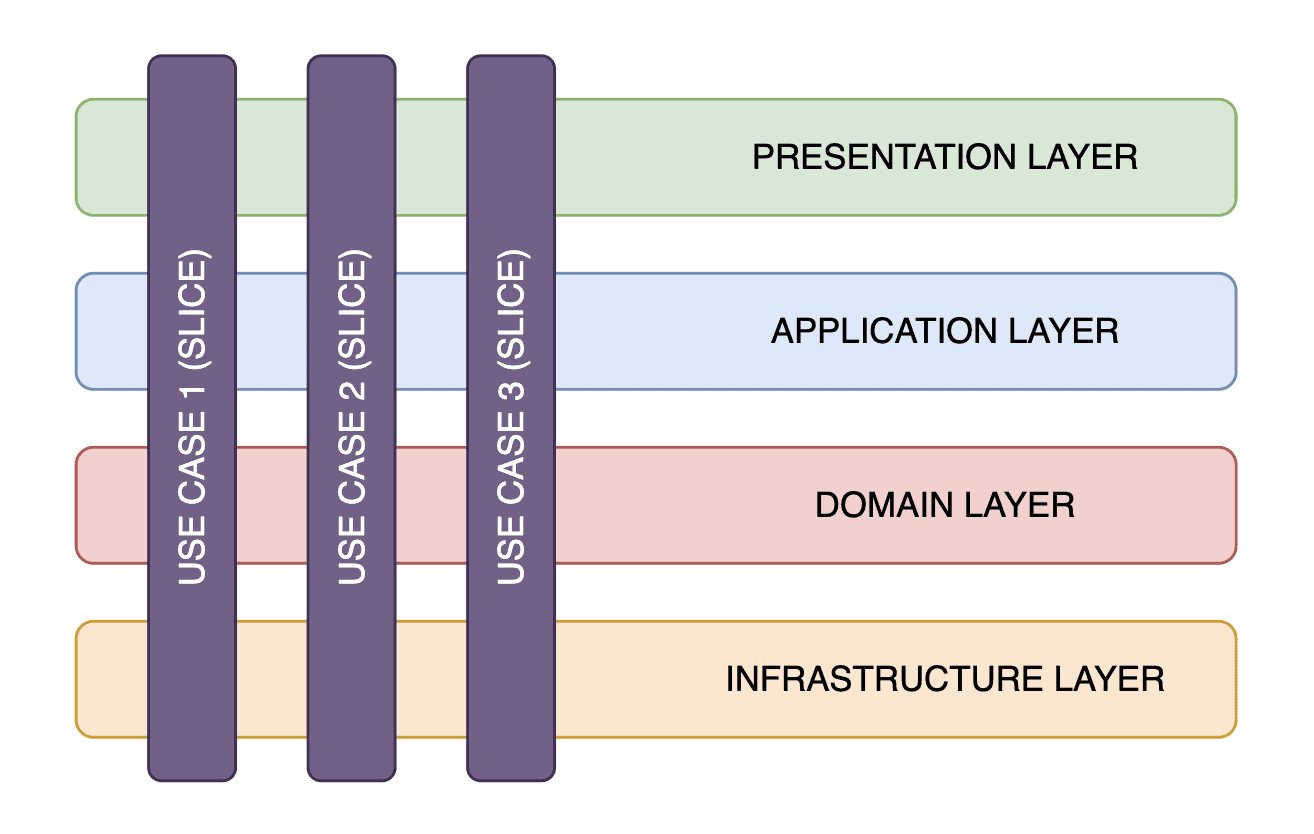
This approach offers several advantages. Each slice operates independently, which facilitates easier changes and updates to specific business functionalities without impacting other parts of the system. Additionally, by grouping all code related to a particular feature or capability together, vertical slicing enhances cohesion within each slice, making the business logic easier to manage and understand.
Vertical slicing also aligns well with Domain-Driven Design (DDD) principles and bounded contexts. Each slice can correspond to a distinct bounded context or domain within the system, helping to maintain clear boundaries. Moreover, vertical slices complement Command Query Responsibility Segregation (CQRS) by clearly separating commands and queries for each slice.
4.4. Domain-Driven Design and Bounded Contexts
Domain-Driven Design (DDD) is a strategic approach to designing software systems that emphasizes focusing on the business domain and its complexities. A key concept within DDD is the pattern of Bounded Context, which helps in dividing an application domain into distinct, manageable parts.
A Bounded Context can be defined as a logical boundary within the application domain, encompassing its own set of rules, language, and models.
For example, the following image may highlight two Bounded Contexts with an e-commerce application:
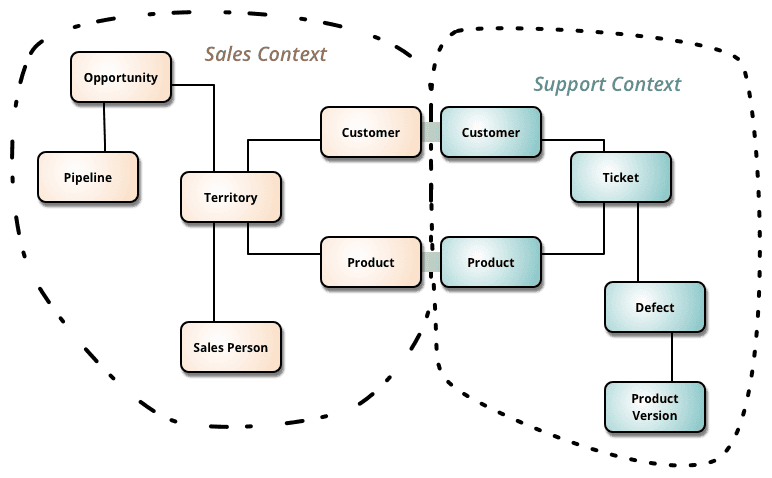 This image was extracted from the article Bounded Context (source).
This image was extracted from the article Bounded Context (source).
{kind=link}
Moreover, this approach reduces coupling between different parts of the system. Each Bounded Context is self-contained, allowing changes to be made within one context without affecting others. By establishing clear contexts, developers can gain a better understanding of the domain within each context, leading to more effective design and implementation. Bounded Contexts also offer the flexibility to use different data models, technologies, and processes tailored to the specific needs of each context, enhancing the overall adaptability of the system.
4.5. Modular Monoliths
The concept of a modular monolith presents a hybrid architectural approach that blends the characteristics of both monolithic and modular designs. Unlike a traditional monolithic application, where all components are tightly integrated into a single unit, a modular monolith introduces a more organized structure by dividing the application into distinct, well-defined modules:
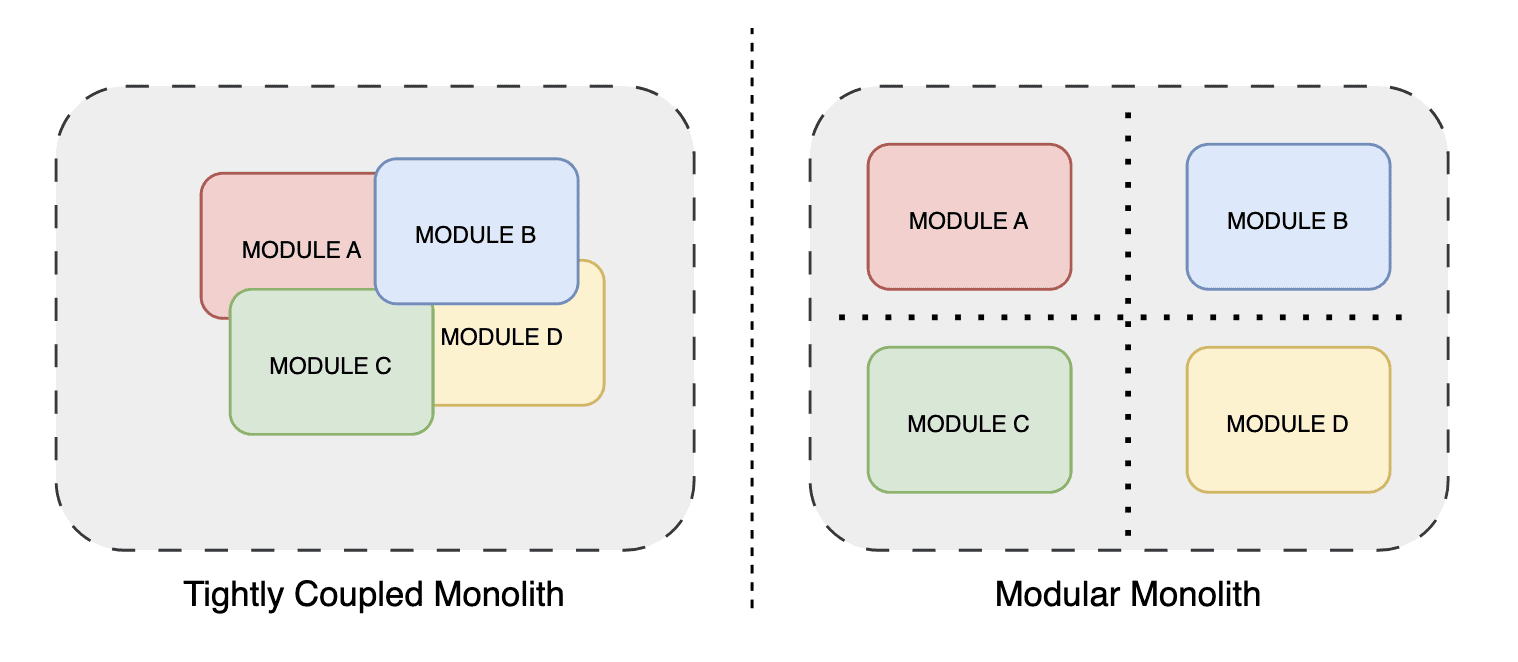
These modules are typically centered around specific business capabilities, creating clear boundaries within the application. This organization facilitates a more manageable and maintainable codebase by encapsulating functionality within each module, which leads to improved separation of concerns. Changes made to one module are less likely to impact others, thus simplifying maintenance and updates.
4.6. Domain-Concentric Architectures
Next, we’ll delve into the realm of domain-concentric architectures: hexagonal architecture, onion architecture, and clean architecture. Although each approach has its unique characteristics, they all share a common core principle: decoupling the domain from external concerns to create a self-contained, independent unit.
At the heart of these architectures is the idea of isolating the domain logic from other layers, such as infrastructure or presentation layers. This separation provides significant advantages, including the flexibility to switch technologies with minimal impact on the core business logic. For instance, if the domain logic is abstracted from the database layer, transitioning from a relational database to a non-relational database becomes a straightforward process. The core business rules are not affected by changes in data storage technology, allowing for more agile adaptations to evolving requirements.
These architectures also leverage principles like Dependency Inversion and patterns such as the Adapter Pattern to shield the domain from external dependencies. This protection is crucial when integrating with third-party services or libraries. By depending on abstractions rather than concrete implementations, these architectures ensure that the domain layer remains isolated from external changes.
5. Conclusion
As we’ve discovered throughout this article, creating boundaries in software development can be achieved through various approaches, each offering distinct advantages. Regardless of the method chosen, the core goal remains the same: to enhance maintainability and ensure that the application remains adaptable and manageable as it evolves.