1. 概述
本教程将深入探讨垂直切片架构(Vertical Slice Architecture),以及它如何解决分层架构(Layered Architecture)中的常见问题。我们将学习如何按业务能力组织代码,从而构建出松耦合、高内聚的模块化代码库。最后,从领域驱动设计(DDD)的角度分析这种架构的灵活性。
2. 分层架构
在研究垂直切片架构前,我们先回顾其主要对手——分层架构的核心特征。分层架构及其变体(如六边形架构、洋葱架构、端口适配器架构、整洁架构)被广泛使用。
分层架构通过一系列堆叠或同心层保护领域逻辑免受外部组件影响。这些架构的关键特征是所有依赖都指向内部领域层: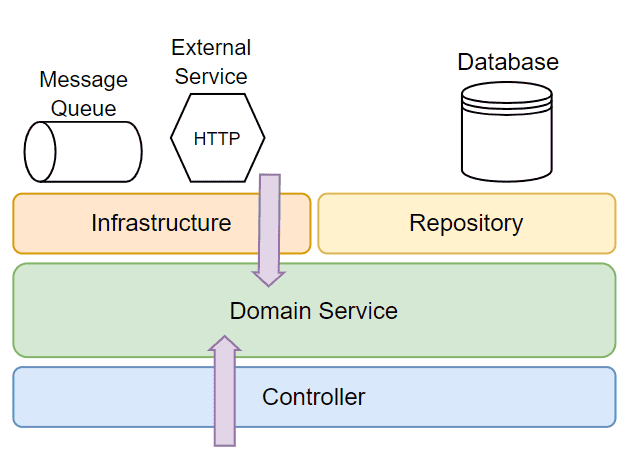
2.1. 按技术职责分组组件
分层架构仅关注按技术职责(而非业务能力)分组组件。假设我们正在开发博客网站后端,需支持以下用例:
- 作者发布和编辑文章
- 作者查看文章统计仪表盘
- 读者阅读、点赞和评论文章
- 读者接收文章推荐通知
但我们的包名仅反映技术分层,无法体现项目真实业务目的: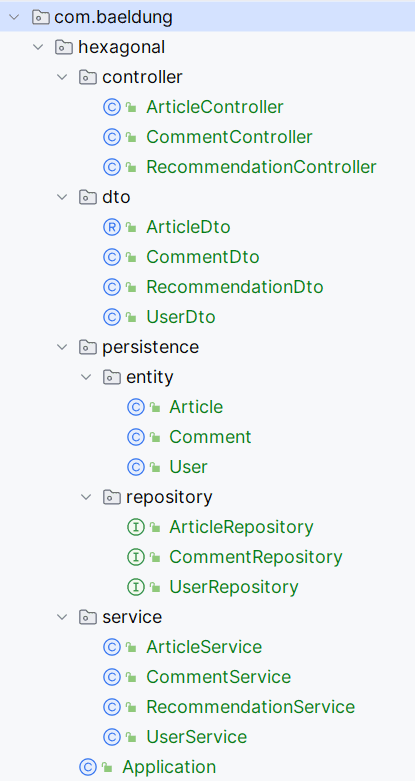
2.2. 高耦合问题
复用同一领域服务处理无关业务用例会导致紧耦合。例如ArticleService当前依赖:
ArticleRepository– 数据库查询UserService– 获取作者数据RecommendationService– 发布文章时更新读者推荐CommentService– 管理文章评论
添加或修改用例时,我们可能意外影响无关流程。这种高度耦合的架构还会导致测试中充满模拟对象(mock),难以维护。
2.3. 低内聚问题
这种代码结构通常导致组件内聚性低。单个业务用例的代码分散在项目各包中,任何小改动都需要修改多个层的文件。
以给Article实体添加slug字段为例。若允许客户端通过新字段查询数据库,需要修改各层多个文件: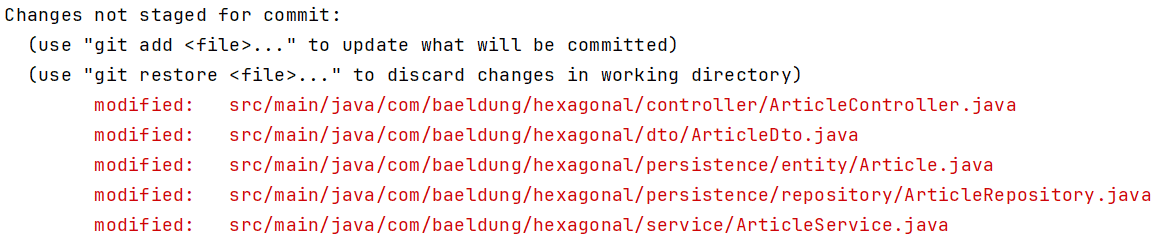
简单修改几乎影响所有包——一起变化的类却分散在不同位置,这正是低内聚的典型表现。
3. 垂直切片架构
垂直切片架构通过按业务能力组织代码来解决分层架构的问题。组件直接对应业务用例,并跨越多个技术层。
结果就是:控制器不再集中在一个包,而是移到各自对应的切片包中: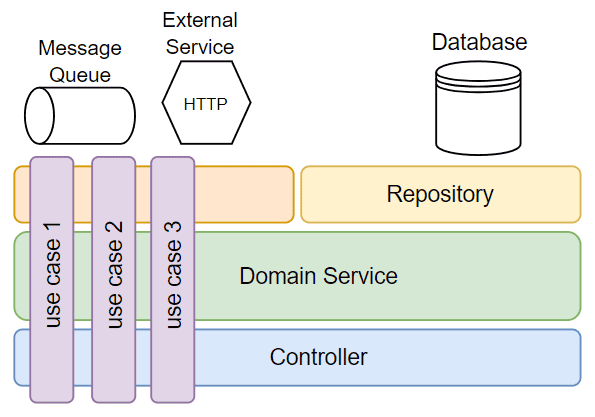
我们还能将相关用例组合成与业务领域对齐的内聚切片。以作者(author)、读者(reader)和推荐(recommendation)领域重组项目: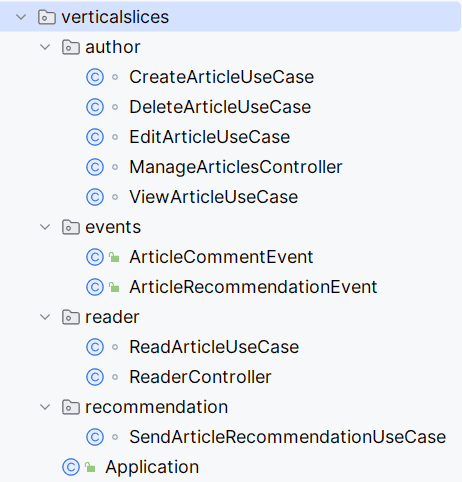
将项目划分为垂直切片后,大多数类可使用默认的包私有访问修饰符。这确保了意外依赖不会跨越领域边界。
最后,这种结构让新人通过文件结构就能理解应用功能。Robert C. Martin(《代码整洁之道》作者)称之为“尖叫架构”——软件设计应像建筑蓝图一样清晰传达其目的。
4. 耦合与内聚
相比洋葱架构,垂直切片架构能更好地管理耦合与内聚。
4.1. 通过应用事件实现松耦合
与其完全消除切片间耦合,不如专注于定义合适的跨边界通信接口。使用应用事件是维持松耦合同时实现跨边界交互的强大技术。
在分层架构中,无关服务相互依赖完成业务功能。例如ArticleService依赖RecommendationService通知新文章发布。而在垂直切片中,推荐流程可异步执行,通过监听应用事件响应主流程。
以Spring框架为例,创建文章时发布Spring事件:
@Component
class CreateArticleUseCase {
private final ApplicationEventPublisher eventPublisher;
// 构造函数
void createArticle(CreateArticleRequest article) {
saveToDatabase(article);
var event = new ArticleCreatedEvent(article.slug(), article.name(), article.category());
eventPublisher.publishEvent(event);
}
private void saveToDatabase(CreateArticleRequest aticle) { /* ... */ }
// ...
}
}
现在SendArticleRecommendationUseCase可用@EventListener响应ArticleCreatedEvent:
@Component
class SendArticleRecommendationUseCase {
@EventListener
void onArticleRecommendation(ArticleCreatedEvent article) {
findTopicFollowers(article.name(), article.category())
.forEach(follower -> sendArticleViaEmail(article.slug(), article.name(), follower));
}
private void sendArticleViaEmail(String slug, String name, TopicFollower follower) {
// ...
}
private List<TopicFollower> findTopicFollowers(String articleName, String topic) {
// ...
}
record TopicFollower(Long userId, String email, String name) {}
}
模块独立运行且不直接依赖。任何关注新文章的组件只需监听ArticleCreatedEvent即可。
4.2. 高内聚性
合理划分边界能产生内聚的切片和用例。**用例类通常只有一个公共方法和单一变更原因,符合单一职责原则**。
在垂直切片架构中给Article类添加slug字段,并创建按slug查询文章的接口。这次改动范围仅限单个包。我们创建使用JdbcClient查询数据库并返回文章投影的SearchArticleUseCase,只需修改一个包中的两个文件:
创建了一个用例并修改ReaderController暴露新接口。两个文件位于同一包,体现了更高的内聚性。
5. 设计灵活性
垂直切片架构允许为每个组件定制方案,为每个用例选择最有效的代码组织方式。换言之,我们可以在整个应用中使用不同工具、模式或范式,而不必强制统一编码风格或依赖。
这种灵活性特别适合领域驱动设计(DDD)和CQRS等模式。
5.1. 使用DDD建模领域
领域驱动设计强调基于核心业务领域和逻辑建模软件。在DDD中,代码必须使用业务人员熟悉的术语,统一技术与业务视角。
垂直切片架构中可能遇到用例间代码重复问题。对于扩展的切片,可提取通用业务规则,用DDD创建特定领域模型: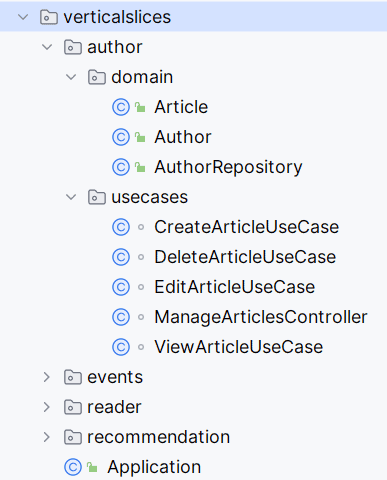
DDD通过限界上下文(Bounded Contexts)定义明确边界,确保系统各部分清晰区分。
在分层架构项目中,我们通过UserService、UserRepository和User实体与用户交互。而在垂直切片项目中,用户概念在不同限界上下文中各不相同——每个切片有独立的用户表示:读者、作者或主题关注者,反映其在特定上下文中的角色。
5.2. 简单用例绕过领域层
严格遵循分层架构的另一个缺陷是产生无价值的“中间人”方法(仅传递调用),导致层间紧耦合。
例如按slug查找文章时,控制器调用服务,服务再调用仓库。即使服务未添加任何价值,分层架构规则也禁止绕过领域层直接访问持久层。
垂直切片应用则允许为每个用例选择所需层。对简单用例可绕过领域层,直接查询数据库获取投影: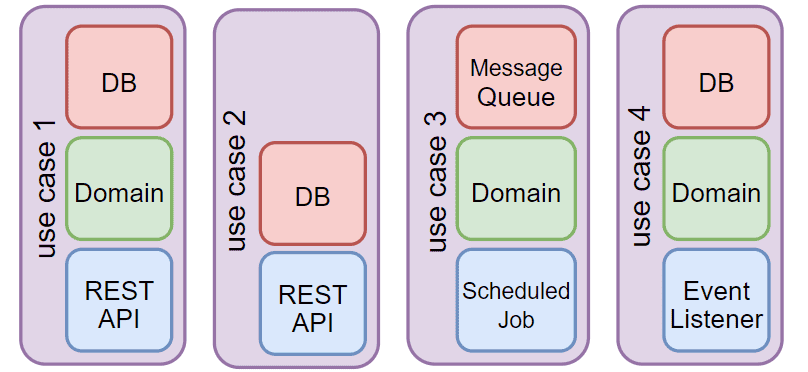
用垂直切片架构简化按slug查看文章的用例:
@Component
class ViewArticleUseCase {
private static final String FIND_BY_SLUG_SQL = """
SELECT id, name, slug, content, authorid
FROM articles
WHERE slug = ?
""";
private final JdbcClient jdbcClient;
// 构造函数
public Optional<ViewArticleProjection> view(String slug) {
return jdbcClient.sql(FIND_BY_SLUG_SQL)
.param(slug)
.query(this::mapArticleProjection)
.optional();
}
record ViewArticleProjection(String name, String slug, String content, Long authorId) {
}
private ViewArticleProjection mapArticleProjection(ResultSet rs, int rowNum) throws SQLException {
// ...
}
}
ViewArticleUseCase直接使用JdbcClient查询数据库,并定义自己的文章投影(而非复用通用DTO),避免与其他组件耦合。无关用例不会被强制统一结构,消除了不必要的依赖。
6. 总结
本文深入探讨了垂直切片架构,并与分层架构进行了对比。我们学习了如何创建内聚组件,避免无关业务用例间的耦合。
讨论了限界上下文如何帮助定义系统各部分的特定投影,最后发现这种架构在设计每个垂直切片时提供了更大的灵活性。
完整源代码可在GitHub获取。该仓库提供了展示应用结构和组件关系的项目“骨架”,但非完整功能应用。