1. 概述
在本篇文章中,我们将深入探讨三个在系统性能优化中非常关键但容易混淆的概念:cache miss(缓存未命中)、TLB miss(页表缓存未命中) 和 page fault(缺页异常)。
这些机制虽然各自独立,但在现代操作系统和硬件架构中紧密协作,共同构成了内存访问的高效流程。理解它们之间的关系,有助于我们更深入地掌握系统性能调优的关键点。
2. 基本概念
2.1 缓存(Cache)
缓存是位于 CPU 和主存(RAM)之间的一种高速存储单元。它的作用是加速对频繁访问数据的读取。
✅ 优点:访问速度快
❌ 缺点:容量有限,一旦所需数据不在缓存中,就会发生 cache miss
当发生 cache miss 时,CPU 必须从更慢的 RAM 中读取数据,这会显著影响性能。
2.2 TLB(Translation Lookaside Buffer)
TLB 是一种专门用于加速虚拟地址到物理地址转换的缓存。它本质上是页表的高速缓存。
✅ 优点:加快地址翻译速度
❌ 缺点:容量小,当所需页表项不在 TLB 中时,就会发生 TLB miss
当 TLB miss 发生时,系统需要访问内存中的页表来完成地址翻译。
2.3 页表(Page Table)
页表是操作系统用于管理虚拟内存到物理内存映射的核心数据结构。
✅ 优点:实现虚拟内存机制
❌ 缺点:页表项不在内存中时,就会触发 page fault
触发 page fault 后,操作系统会从磁盘加载所需页面到内存中,并更新页表和 TLB。
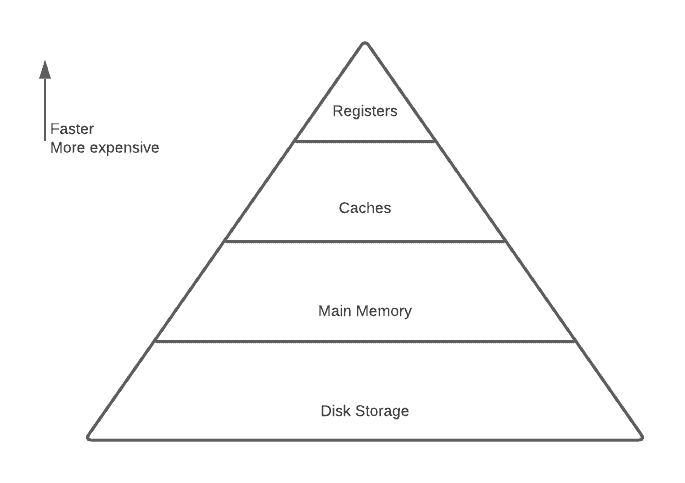
3. 内存层次结构
现代计算机系统采用内存层次结构(Memory Hierarchy) 来平衡速度、容量和成本之间的矛盾。
3.1 为什么需要缓存、TLB 和虚拟内存?
简要总结如下:
- ✅ 缓存:提升 CPU 访问速度
- ✅ TLB:加速地址翻译
- ✅ 虚拟内存:让程序员看到“无限”的内存空间
这些机制共同构成了一个从 CPU 寄存器到硬盘的多级存储体系,每一层都服务于上一层的缓存角色。
下图展示了内存层次结构的典型布局:
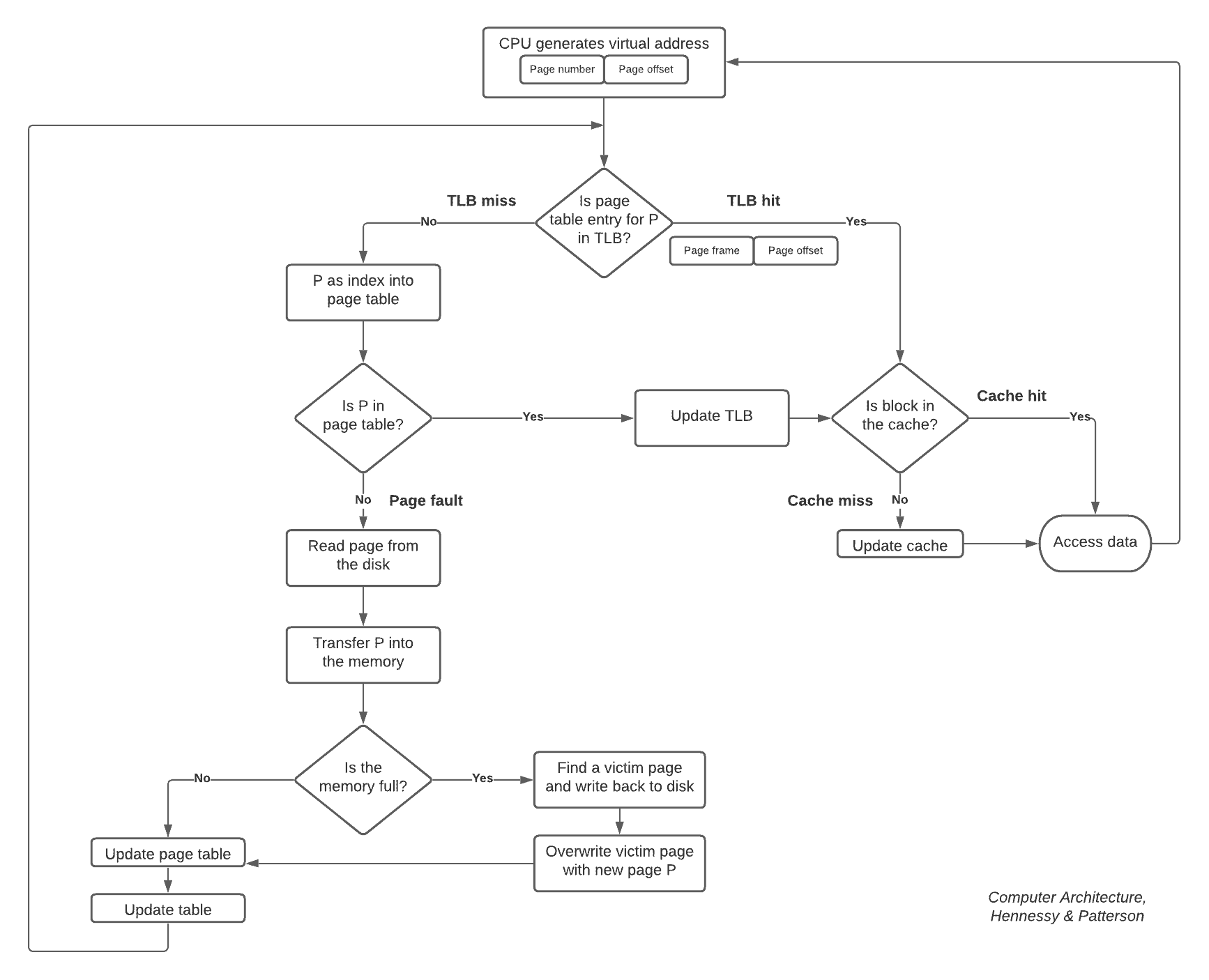
4. Cache Miss、TLB Miss 与 Page Fault 的协同工作
在内存访问流程中,这三个机制是串联工作的:
- CPU 发出虚拟地址
- 使用 TLB 查找对应的物理页号
- ✅ TLB hit:继续访问缓存
- ❌ TLB miss:查找页表
- ✅ 页表有映射:更新 TLB
- ❌ 页表无映射:触发 page fault
- 使用物理地址访问缓存
- ✅ Cache hit:直接返回数据
- ❌ Cache miss:从主存加载数据到缓存
下图展示了这一流程:
4.1 举例说明
假设 CPU 想访问某个虚拟地址的数据:
- TLB 中找不到对应的页表项 → TLB miss
- 查页表发现该页不在内存中 → page fault
- 操作系统从磁盘加载页面到内存
- 更新页表和 TLB
- 重新执行指令
5. 缓存与虚拟内存的区别
虽然两者都涉及“缓存”思想,但它们在实现机制和职责上有明显不同:
| 特性 | 缓存(Cache) | 虚拟内存(Virtual Memory) |
|---|---|---|
| 数据单位 | 缓存行(Cache Line) | 页(Page) |
| 管理方式 | 硬件自动管理 | 操作系统管理 |
| 容量大小 | 小(KB~MB) | 大(GB 级) |
| 替换策略 | LRU、FIFO 等 | LRU、Clock 等 |
| 异常处理 | 无 | 缺页异常(Page Fault) |
| 存储介质 | 主存 | 磁盘(Swap) |
⚠️ 注意:缓存 miss 通常由硬件自动处理,而 page fault 则必须由操作系统介入处理。
6. 总结
本文介绍了 cache miss、TLB miss 和 page fault 三个关键机制的原理与协同工作流程。它们分别位于 CPU、页表和磁盘的不同层次,构成了现代内存系统的高效访问路径。
- ✅ cache miss 影响 CPU 性能
- ✅ TLB miss 增加地址翻译开销
- ✅ page fault 触发磁盘 I/O,代价最大
理解这些机制之间的关系,有助于我们在性能调优、系统监控和故障排查中快速定位瓶颈。尤其是在高并发或大规模数据处理场景下,这些底层机制的优化往往能带来显著的性能提升。