1. 引言
在本篇文章中,我们将探讨缓存中常见的写操作实现方式。我们会分析每种策略的优缺点,并讨论在实际应用中如何选择合适的写策略。
不过在深入之前,我们先来回顾一下缓存的基本概念,确保大家对缓存的作用和相关术语有统一的理解。
2. 缓存基础
缓存是一种用于提供对底层存储快速访问的中间层组件。通常来说,缓存的存储介质更快但也更昂贵,因此容量有限。在某些场景下,缓存可能是我们系统的一部分,而原始数据存储(backing store)则可能由外部系统管理。
✅ 缓存的核心目标是提升操作的延迟(latency)和吞吐量(throughput)。
缓存命中(cache hit)是指请求的数据在缓存中存在;反之则称为缓存未命中(cache miss)。
缓存中的数据可能会因为以下原因被移除(eviction):
- 数据未被使用
- 数据体积过大
- 系统认为继续保留不划算
这与缓存失效(invalidation)不同。缓存失效是指我们主动将缓存标记为无效,可能是直接删除缓存条目,或者在下次请求时重新从原始存储加载数据。
3. 写策略概述
缓存的写策略(write policy)决定了在执行写操作时缓存的行为方式。写策略直接影响缓存的一致性、性能和可靠性等关键特性。
常见的写策略包括:
- Write-through(直写)
- Write-around(绕写)
- Write-back(回写)
接下来我们逐一介绍这些策略。
4. Write-through(直写)
如果你的应用优先考虑数据一致性,通常会选择 Write-through 策略。在这种模式下,写操作会同步更新缓存和底层存储,只有当两者都成功时,才向客户端返回响应。
如果当前写入的数据不在缓存中,我们会先将它加载到缓存中再执行写操作:
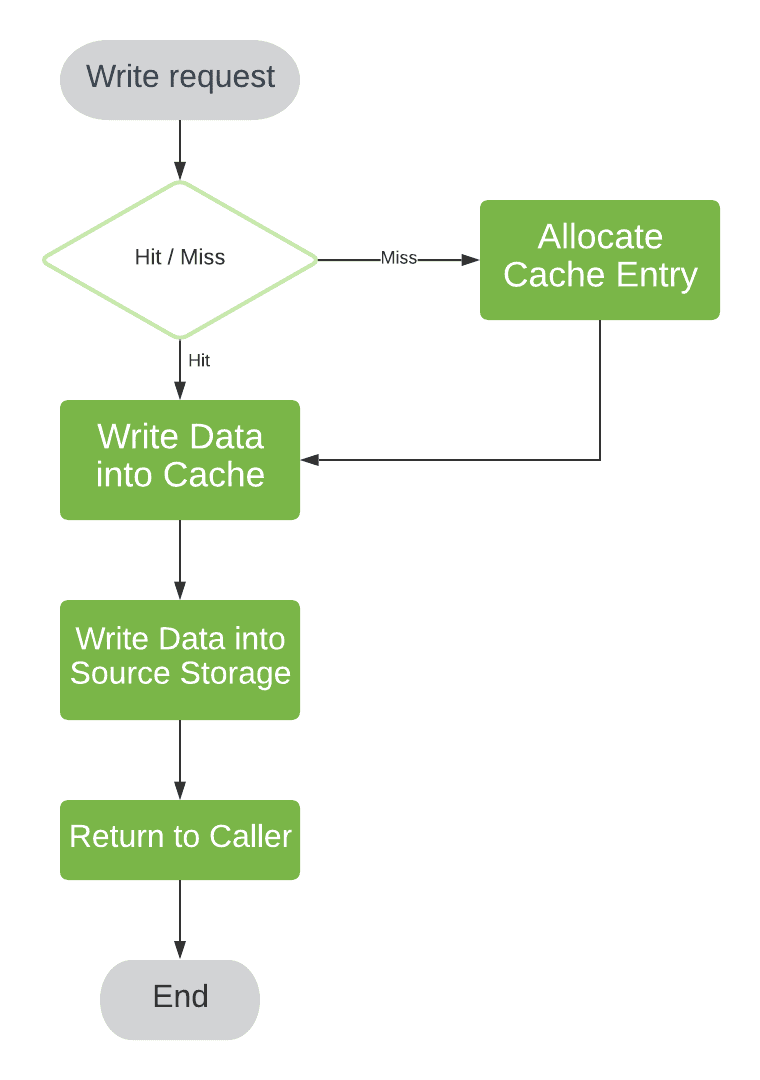
✅ 优点:
- 数据一致性高
- 实现简单
❌ 缺点:
- 写操作延迟较高(需要等待底层存储完成)
5. Write-around(绕写)
Write-through 策略的一个问题是:如果写入的数据短期内不会被读取,那么就会“污染”缓存,造成缓存空间浪费。
为了避免这种缓存污染(cache pollution),我们可以采用 Write-around 策略。它在缓存未命中时不将数据写入缓存,而是直接写到底层存储。
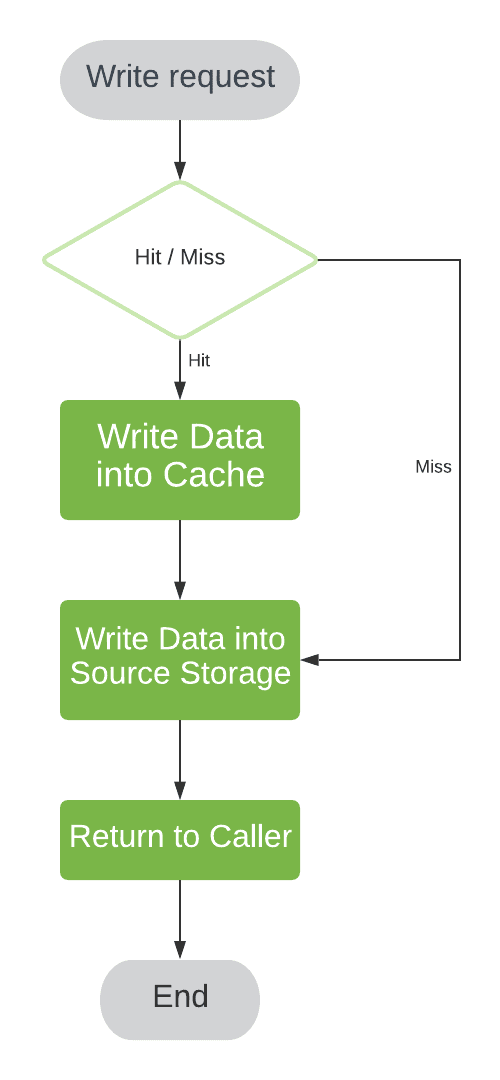
此外,还有一种变种叫做 Write-invalidate,它在缓存命中时写入底层存储的同时,将缓存中的条目标记为无效。
✅ 优点:
- 避免缓存污染
- 适合写多读少的场景
❌ 缺点:
- 缓存命中率可能降低
- 可能导致后续读操作延迟增加
6. Write-back(回写)
Write-back 是三种策略中性能最好的一种。它先将数据写入缓存并立即返回响应,然后在后台异步地将数据刷新到底层存储。
这种异步刷新可以有多种触发方式:
- 在写入响应前触发
- 定期触发
- 基于缓存条目的“脏状态”(dirty state)触发
在 CPU 缓存中,我们使用“脏位”(dirty bit)来标识缓存是否被修改。在软件缓存中,通常更倾向于在写入响应前触发异步刷新。
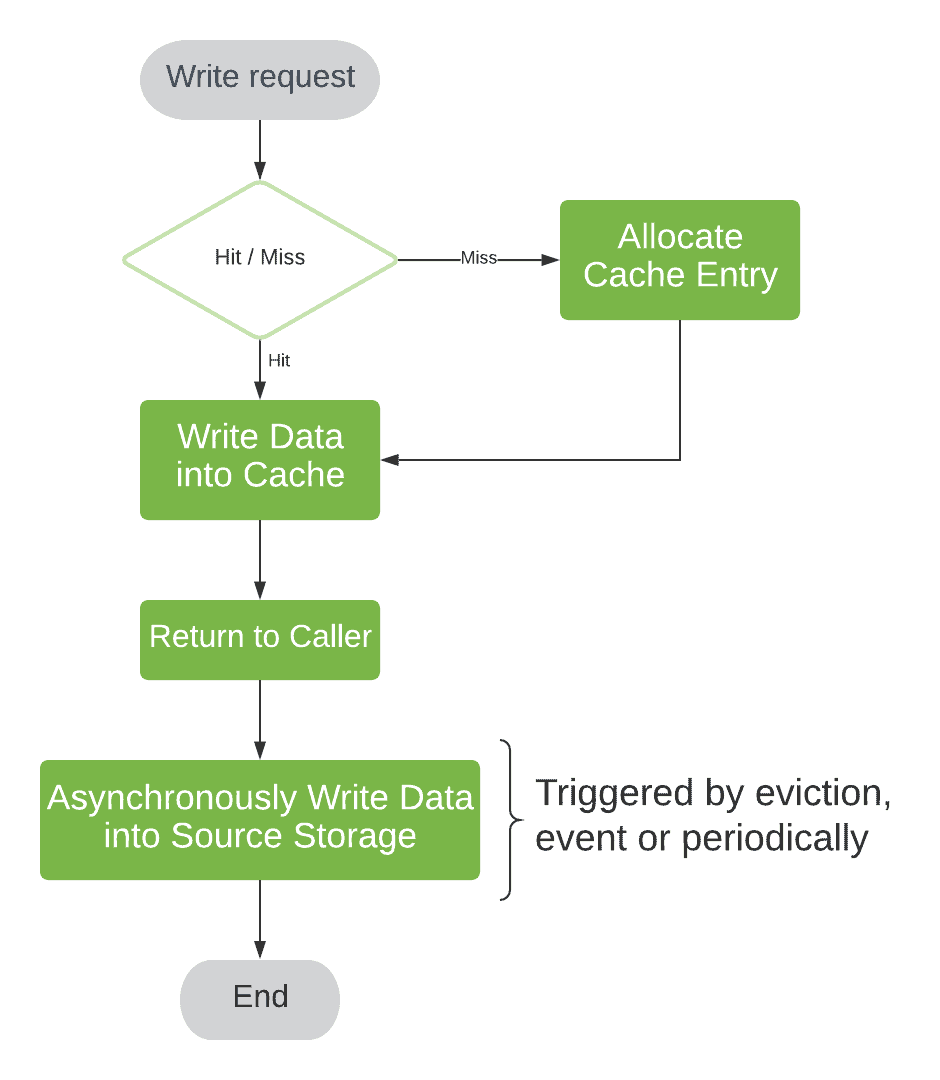
✅ 优点:
- 写操作延迟低
- 支持批量写入,提升吞吐量
❌ 缺点:
- 存在一致性风险
- 缓存数据丢失可能导致数据丢失(如断电)
⚠️ 踩坑提示:Write-back 策略下,如果系统崩溃或断电,未刷新到底层存储的“脏”数据将丢失。因此,必须配合持久化机制或冗余设计使用。
此外,如果存在多个缓存实例或绕过缓存的写操作,可能出现数据顺序混乱的问题。为了解决这个问题,我们需要实现所谓的 事务序列化(transaction serialization),以保证操作顺序的一致性。
这类问题和解决机制统称为 缓存一致性(cache coherence)。
7. 写分配策略(Write Allocation)
前面我们提到,在 Write-through 策略中,即使缓存未命中,也可以选择是否将数据写入缓存。这个选择被称为“写分配(write allocation)”。
写分配策略主要有两种:
- Write allocate(写分配):在写入前将数据加载到缓存中
- No-write allocate(不写分配):绕过缓存,直接写入底层存储
在 Write-back 策略中,一般推荐使用 Write allocate,因为它可以利用缓存的优势进行异步刷新。而 No-write allocate 更适合 Write-through 场景,尤其是写多读少的场景。
8. 权衡与选择
在选择缓存写策略时,我们需要综合考虑以下几个因素:
| 策略 | 一致性 | 性能 | 数据安全性 | 适用场景 |
|---|---|---|---|---|
| Write-through | ✅ | ❌ | ✅ | 对一致性要求高 |
| Write-around | ❌ | ✅ | ✅ | 写多读少,避免缓存污染 |
| Write-back | ❌ | ✅✅ | ❌ | 对性能要求高,能容忍短暂不一致 |
此外,还要考虑:
- 数据访问模式(读多写少 / 写多读少)
- 数据局部性(是否频繁访问)
- 是否有多个缓存实例或并发写入路径
9. 总结
本文我们详细介绍了三种常见的缓存写策略:Write-through、Write-around 和 Write-back。
每种策略都有其适用场景和潜在风险。没有一种写策略是万能的,选择时应根据以下因素综合判断:
- 系统对数据一致性的要求
- 对性能(延迟/吞吐)的关注程度
- 数据访问模式
- 系统架构是否支持并发写入或多缓存实例
- 是否具备数据持久化或冗余机制
✅ 最终建议:
- 如果你追求强一致性,用 Write-through;
- 如果你追求写性能,用 Write-back,但要做好数据持久化和缓存一致性保障;
- 如果写操作不频繁被读取,考虑 Write-around 来避免缓存污染。