1. 概述
在本文中,我们将探讨两个在机器学习领域经常被混淆的概念:大数据(Big Data) 和 数据挖掘(Data Mining)。我们将分别解释这两个术语的含义,并分析它们之间的联系与区别。
通过本文,你将掌握以下内容:
✅ 什么是大数据?
✅ 什么是数据挖掘?
✅ 两者之间的核心差异
✅ 为什么媒体经常混淆这两个术语?
我们还将探讨一个核心观点:“大数据”这一术语之所以重新流行,是因为计算能力的增长速度跟不上数据量的增长速度。
2. 大数据(Big Data)
2.1. 多大才算“大数据”?
“大数据”这个词近年来变得非常流行,但并没有一个严格的定义。它并不是指某个特定大小的数据集,而是一种描述数据规模增长趋势的模糊说法。

比如,一个表有多少行才算是“大数据”?这个问题没有标准答案。因此,大数据更多是一个趋势性描述,而不是技术性定义。
2.2. 术语的起源
最早在科学文献中提到“Big Data”是在1970年代的一篇论文中。当时的研究主要关注如何自动化矩阵分解,而不是手动分析。随后在处理地理数据、大型词典等任务时也频繁出现这一术语。
这些早期用法都传达了一个核心思想:随着数据量的增长,数据管理和处理变得越来越困难。
2.3. 现代语境下的复兴
从2010年代开始,“大数据”重新流行起来,成为大众媒体和科技圈的常用词:
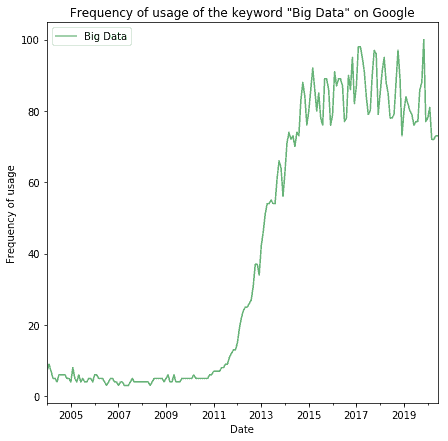
这种复兴背后的原因可以归结为三点:
- 数据集的平均规模在持续增长
- 数据增长速度超过了计算能力的增长
- 数据规模的变化与计算能力的变化无直接因果关系
2.4. 数据集的增长趋势
虽然我们无法统计所有数据集的增长情况,但通过观察大型公司持有的数据,我们可以推测出一个趋势:数据集的平均规模正在呈指数级增长。
2.5. 数据增长的代理指标
互联网普及率和物联网设备数量是衡量数据增长的两个重要代理指标:
- 互联网普及率:从2015年的45%上升到2020年的60%
- 物联网设备数量:在同一时期翻倍增长
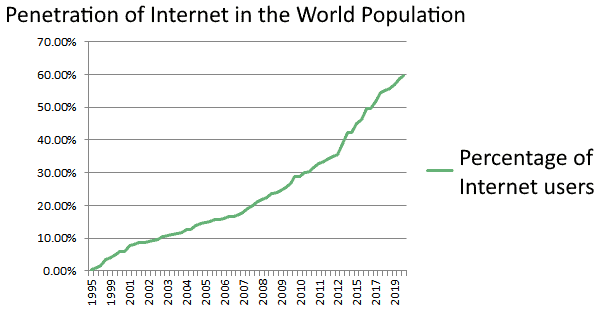
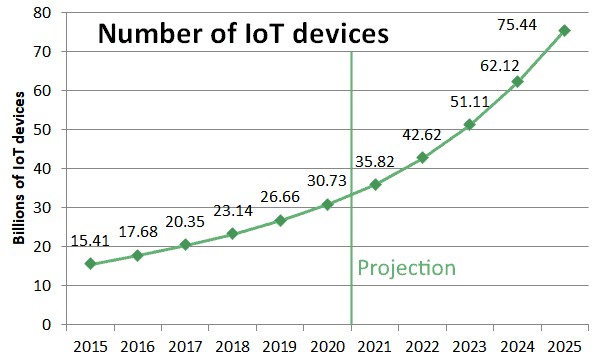
这两个因素共同推动了数据量的快速增长。
2.6. 计算能力的增长
计算能力的增长虽然依然在进行,但增速已放缓。根据摩尔定律(Moore’s Law),计算能力每两年翻倍一次,但近年来这一规律已不再适用。
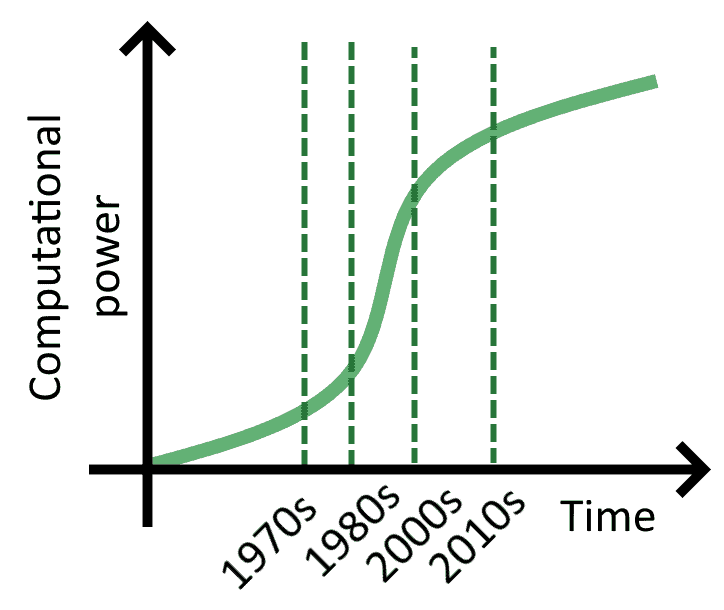
这意味着,计算能力的增长速度已经跟不上数据量的增长速度。
2.7. 数据与计算的差距
总结如下:
- 数据集的增长速度远快于计算能力的增长
- 数据处理所需的计算资源增长速度快于线性(例如矩阵乘法复杂度为 $O(n^3)$)
- 部分新增计算资源用于生成数据,而非处理数据
因此,我们正面临一个“数据多、计算慢”的时代,这也是“大数据”一词重新流行的根本原因。
3. 数据挖掘(Data Mining)
3.1. 数据挖掘的含义
“数据挖掘”一词来源于这样一个比喻:像在矿场中挖掘宝藏一样,从数据中提取有价值的知识。

它强调的是从原始数据中发现隐藏的模式、趋势和知识,而不是数据的规模。
3.2. 数据挖掘与知识发现
“知识发现(Knowledge Discovery)”是数据挖掘的另一个说法,最早在1989年的人工智能研讨会上提出。
一个典型例子是路径规划:如果我们仅依靠“卡车不能在水上行驶”的常识,可能会忽略“冬季结冰的河流”这一可行路径。而数据挖掘可以发现这种人类常识无法识别的模式。
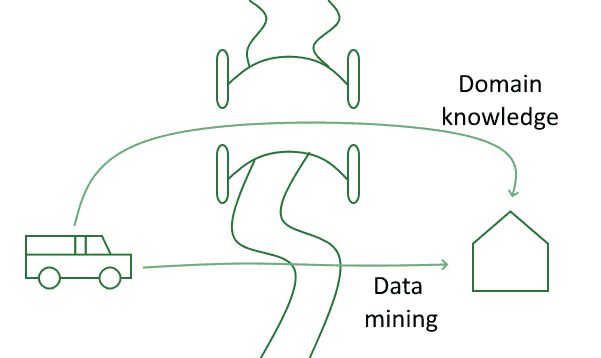
3.3. 数据挖掘与数据存储的关系
数据挖掘常与数据存储技术一起使用,但它们不是同一概念。例如:
- Hadoop 是一个分布式存储框架
- Apache Spark + MLib 是更适合进行数据挖掘的工具
虽然两者常一起出现,但数据挖掘并不依赖于特定的存储技术。
4. 术语混淆的原因
4.1. 数据挖掘常用于大数据
简单任务可以手动分析,但复杂任务往往需要借助数据挖掘技术。例如广告效果分析:
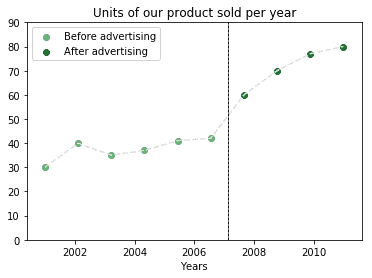
而当数据更复杂时,就需要数据挖掘:
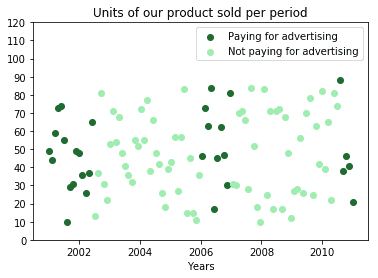
因此,数据挖掘天然地与大数据联系在一起。
4.2. 拥有大数据的组织也做数据挖掘
大型科技公司如 Google、CERN 等,既拥有大量数据,又拥有专门的数据挖掘团队。
例如:
- Google 的 Graph Mining 团队专注于知识图谱挖掘
- CERN 开发了 ROOT 工具,用于大规模数据挖掘
这些组织推动了大数据和数据挖掘的关联。
4.3. 大数据通常包含大量噪声
随着数据规模的增长,噪声增长速度往往超过有用信息的增长速度。这需要使用数据挖掘技术进行噪声过滤,从而进一步加深了两者之间的联系。
5. 总结
| 维度 | 大数据(Big Data) | 数据挖掘(Data Mining) |
|---|---|---|
| 核心 | 数据规模的增长趋势 | 从数据中提取知识的技术 |
| 关键点 | 数据量大、增长快 | 算法提取隐藏信息 |
| 依赖关系 | 不依赖计算能力 | 可在任何数据集上进行 |
| 术语模糊性 | ✅ 高 | ❌ 低 |
| 常见场景 | 数据存储、传输、管理 | 模式识别、预测分析 |
踩坑提醒:
在实际工作中,不要把“大数据”和“数据挖掘”混为一谈。前者描述的是数据规模和处理挑战,后者则是技术手段。混淆这两个术语,容易导致项目方向错误或资源分配不当。
✅ 关键结论:
- “大数据”是一个趋势性术语,反映的是数据增长快于计算能力的现实
- “数据挖掘”是一组技术,用于从数据中提取知识
- 两者常被混淆,是因为它们经常一起出现,但本质上是两个不同的概念
如果你正在处理一个大型数据集,首先要明确:你是在解决“大数据”的存储和处理问题,还是在做“数据挖掘”的建模和分析。