1. 概述
在机器学习中,分类任务的目标是预测某个样本所属的类别标签。本文将重点介绍如何评估分类器在二分类和多分类问题上的表现,涵盖一些最常用的评估指标,包括:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F-1 分数(F-1 Score)
- ROC 曲线(ROC Curve)
- AUC(Area Under the Curve)
我们还会对比精确率与召回率这两个常被混淆的指标,帮助你理解它们各自适用的场景。
2. 二分类问题
二分类是分类任务中最常见的一种形式,只有两个可能的类别标签。例如,判断一封邮件是否为垃圾邮件(是/否)、判断一个交易是否为欺诈(是/否)等。
我们可以将这两个类别分别称为正类(Positive)和负类(Negative)。例如,在垃圾邮件检测中,“垃圾邮件”是正类,“非垃圾邮件”是负类。
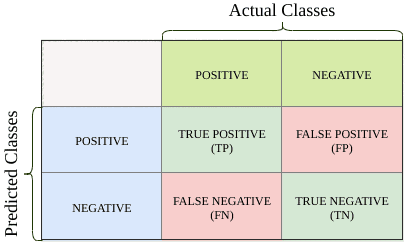
我们可以使用一个叫做混淆矩阵(Confusion Matrix)的表格来总结模型预测结果与实际标签之间的关系:
| 实际\预测 | 正类(Positive) | 负类(Negative) |
|---|---|---|
| 正类 | TP(真正例) | FN(假负例) |
| 负类 | FP(假正例) | TN(真负例) |
- ✅ TP(True Positive):预测为正类,实际也为正类
- ❌ FP(False Positive):预测为正类,实际为负类(Type I 错误)
- ✅ TN(True Negative):预测为负类,实际也为负类
- ❌ FN(False Negative):预测为负类,实际为正类(Type II 错误)
混淆矩阵的对角线代表正确预测的数量。我们希望这个值尽可能大。
3. 二分类常用评估指标
3.1. 准确率(Accuracy)
准确率是最直观的评估指标,表示所有预测正确的样本数占总样本数的比例。
公式如下:
$$ \textrm{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} $$
✅ 优点:计算简单,适合类别分布均衡的场景
❌ 缺点:在类别不平衡时容易误导判断
举个例子:假设你收到的 100 封邮件中,有 90 封是垃圾邮件。如果你的模型把所有邮件都预测为“垃圾邮件”,那准确率就是 90%。但显然,这个模型对非垃圾邮件毫无识别能力。
所以,在数据不平衡的场景下,准确率不是一个好的评估指标。
3.2. 精确率(Precision)与召回率(Recall)
精确率(Precision)
精确率衡量的是:模型预测为正类的样本中,有多少是真正的正类。
$$ \textrm{Precision} = \frac{TP}{TP + FP} $$
✅ 适用于:我们希望尽量避免“假阳性”(FP)的场景,例如垃圾邮件检测。我们不希望把正常邮件误判为垃圾邮件。
召回率(Recall)
召回率衡量的是:实际正类样本中,有多少被模型正确识别出来。
$$ \textrm{Recall} = \frac{TP}{TP + FN} $$
✅ 适用于:我们希望尽量避免“假阴性”(FN)的场景,例如癌症检测。漏诊比误诊更危险。
精确率 vs 召回率
- 精确率高:模型预测的正类样本更可靠(少误报)
- 召回率高:模型识别出的正类样本更全面(少漏报)
⚠️ 二者之间存在权衡关系(Trade-off)。提高一个指标,通常会导致另一个指标下降。
3.3. F-1 分数(F-1 Score)
F-1 分数是精确率和召回率的调和平均数,适用于需要平衡两者重要性的场景。
$$ \textrm{F-1 Score} = \frac{2 \times Precision \times Recall}{Precision + Recall} $$
✅ 适用于:类别不平衡且我们希望精确率和召回率都表现良好的场景
⚠️ 注意:F-1 分数无法反映 TN 的贡献
3.4. ROC 曲线与 AUC 值
ROC 曲线(Receiver Operating Characteristic Curve)
ROC 曲线通过不同阈值下的 TPR(真正例率)和 FPR(假正例率)来评估模型的分类性能。
- TPR(真正例率)= Recall = $ \frac{TP}{TP + FN} $
- FPR(假正例率)= $ \frac{FP}{FP + TN} $
ROC 曲线的横轴是 FPR,纵轴是 TPR。随着阈值的变化,模型的预测结果也随之变化,从而得到一系列点,连接这些点就构成了 ROC 曲线。
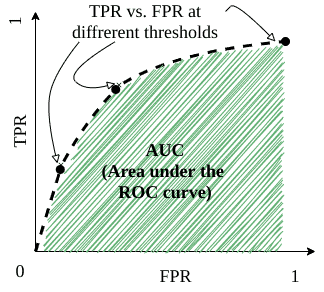
AUC(Area Under the Curve)
AUC 表示 ROC 曲线下方的面积,取值范围在 0 到 1 之间。
- AUC = 1:完美分类器
- AUC = 0.5:随机猜测
- AUC > 0.5:模型有一定预测能力
✅ 优点:不受类别分布影响,适用于二分类问题
⚠️ 缺点:无法直接反映模型在特定阈值下的性能
4. 多分类问题
当分类任务有超过两个类别时,称为多分类(Multiclass Classification)。
例如,图像识别中识别动物类别(猫、狗、鸟等)、文本分类中识别文章主题(科技、体育、娱乐等)等。
多分类的评估方式与二分类类似,但有一些关键区别:
- 准确率依然可以使用(对角线总和 / 总样本数)
- 精确率和召回率需要为每个类别单独计算
4.1. 多分类中的准确率
准确率依然表示正确预测的比例:
$$ \textrm{Accuracy} = \frac{# \text{correctly classified}}{# \text{samples}} $$
例如:
$$ \textrm{Accuracy} = \frac{50 + 8 + 4 + 1}{127} = \frac{63}{127} = 49.6% $$
4.2. 多分类中的精确率与召回率
每个类别都可以单独计算其精确率和召回率:
精确率(Precision for class a): $$ \textrm{Precision}(class=a) = \frac{TP_a}{TP_a + FP_a} $$
召回率(Recall for class a): $$ \textrm{Recall}(class=a) = \frac{TP_a}{TP_a + FN_a} $$
例如,对于类别 a:
$$ \textrm{Precision}(class=a) = \frac{50}{53} = 94.3% \ \textrm{Recall}(class=a) = \frac{50}{108} = 46.3% $$
对于其他类别:
$$ \begin{aligned} \textrm{Precision}(class=b) & = \frac{8}{35} & \textrm{Recall}(class=b) & = \frac{8}{13} \ \textrm{Precision}(class=c) & = \frac{4}{26} & \textrm{Recall}(class=c) & = \frac{4}{4} \ \textrm{Precision}(class=d) & = \frac{1}{13} & \textrm{Recall}(class=d) & = \frac{1}{2} \end{aligned} $$
5. 总结
分类模型的评估不能只看一个指标,而应根据具体业务需求和数据分布选择合适的评估方式:
| 指标 | 适用场景 | 特点说明 |
|---|---|---|
| Accuracy | 类别分布均衡时 | 简单直观,但在类别不平衡时容易误导判断 |
| Precision | 希望减少假阳性(FP) | 适用于误报代价高的场景 |
| Recall | 希望减少假阴性(FN) | 适用于漏报代价高的场景 |
| F-1 Score | 需要平衡精确率和召回率 | 适用于类别不平衡且需综合考虑 FP 和 FN 的场景 |
| ROC & AUC | 二分类问题,需比较模型整体性能 | 不依赖具体阈值,适用于类别不平衡 |