1. 概述
在数据科学中,探索数据的第一步通常是理解数据中包含的内容。我们对数据了解得越少,就越需要一些能够帮助我们发现数据结构的算法。如果我们能通过可视化看到清晰的聚类结构,就可以使用那些需要我们预先指定聚类数量的算法。
但如果我们面对的是高维数据,或者聚类结构并不明显,那么使用需要提前指定聚类数量的算法就变得困难。幸运的是,有一些聚类算法并不依赖于我们对聚类数量的先验知识。在本文中,我们将介绍这些算法的基本原理和适用场景。
2. 聚类概念
聚类类似于分类,但又不完全相同。 分类需要我们事先知道有哪些类别,而聚类则是在我们对类别一无所知的情况下,让算法自行发现数据中的结构和模式。不同的聚类算法会生成不同的聚类结果,因此我们通常会尝试多个算法,以发现不同的潜在模式。
“聚类”这个词来源于我们在图上观察数据点时的直观感受: 一个聚类就是一组彼此“靠近”的数据点。
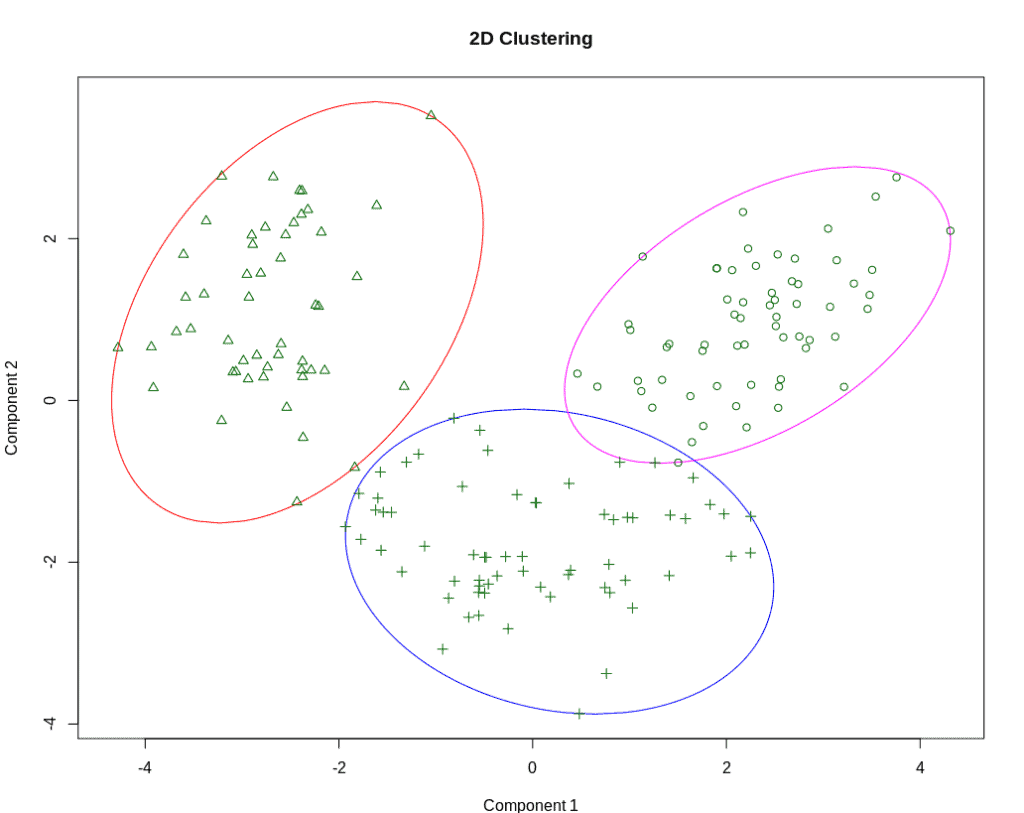
那么,我们如何判断“靠近”?这就涉及到如何衡量点与点之间的距离或相似性。
3. 距离与相似性计算
判断一个点是否属于某个聚类,通常有以下几种方式来衡量“接近”程度:
✅ 最近邻法:看该点与聚类中最近的点之间的距离
✅ 最远邻法:看该点与聚类中最远的点之间的距离
✅ 平均距离法:计算该点与聚类中所有点的平均距离
✅ 质心法:计算该点与聚类质心(centroid)之间的距离
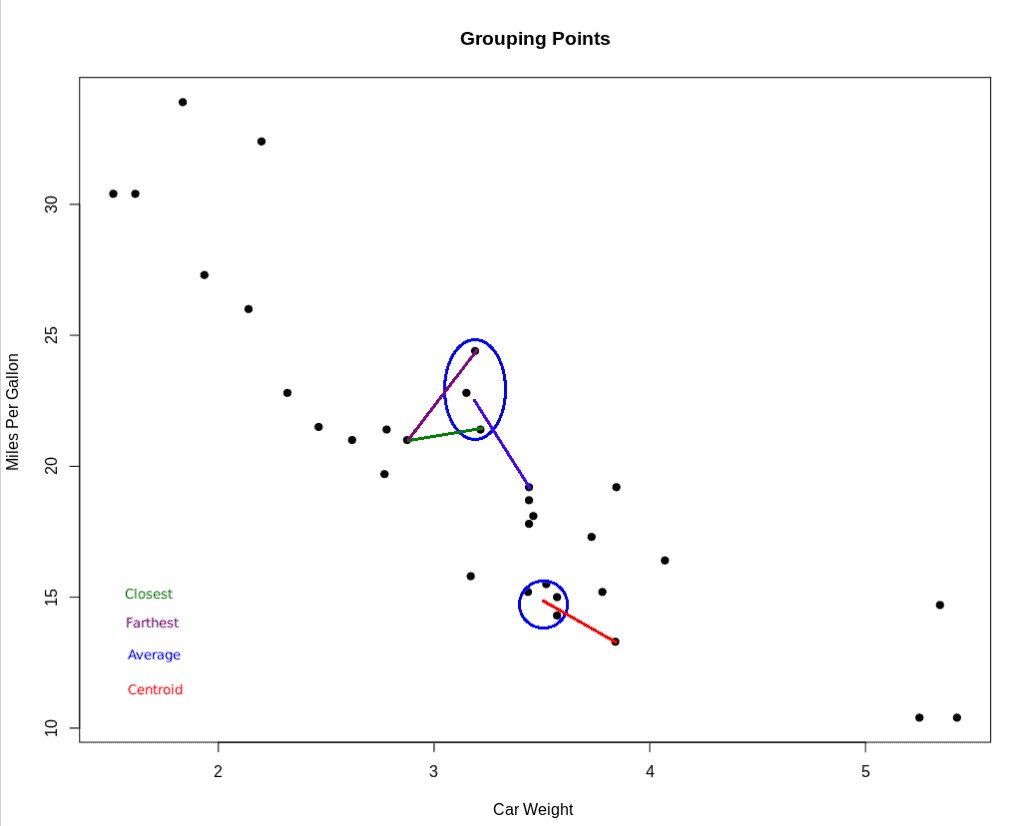
这些方法各有优劣,具体使用哪种方法取决于数据特性和聚类目标。
常用距离公式
最常见的距离计算方式是欧几里得距离(Euclidean Distance):
$$ \sqrt{x^2 - y^2} $$
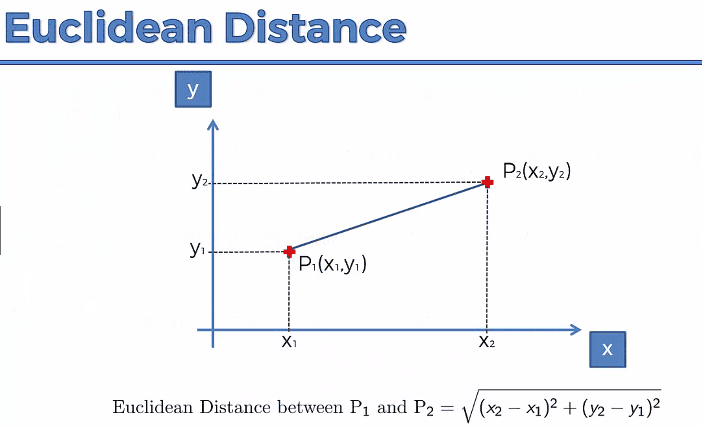
当然,也有其他距离度量方式,比如曼哈顿距离、余弦相似度等,具体选择要根据数据分布和业务场景来定。
4. 常见聚类算法(无需预设聚类数)
以下是一些不需要提前指定聚类数量的主流算法。
4.1 层次聚类(Hierarchical Clustering)
层次聚类是一种基于连接性的聚类方法,分为两种实现方式:
- ✅ Agglomerative(自底向上):每个点最开始是一个聚类,逐步合并最近的两个聚类。
- ✅ Divisive(自顶向下):最开始是一个大聚类,逐步分裂成更小的聚类。
层次聚类会记录聚类合并或分裂的过程,并通过 树状图(dendrogram) 来可视化:
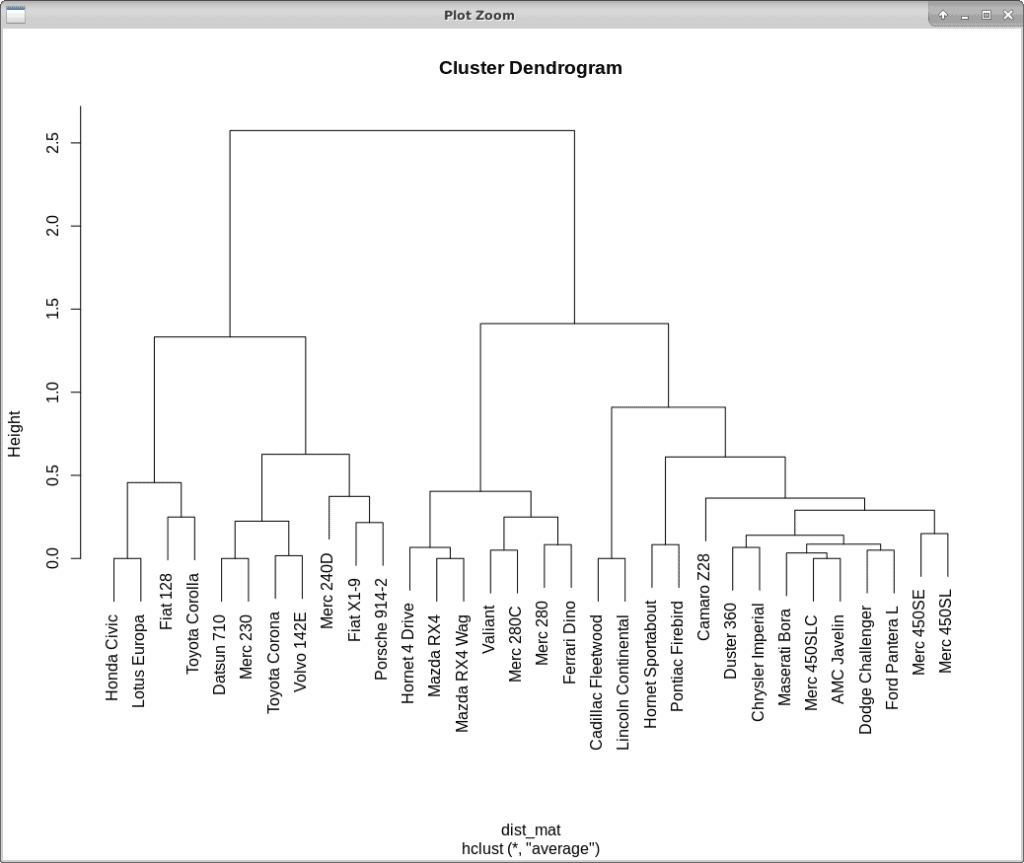
如何确定最佳聚类数?
找到树状图中最长的无断线段,画一条垂直线,穿过该线的分支数即为最佳聚类数。上图中可看出应分为 2 个聚类。
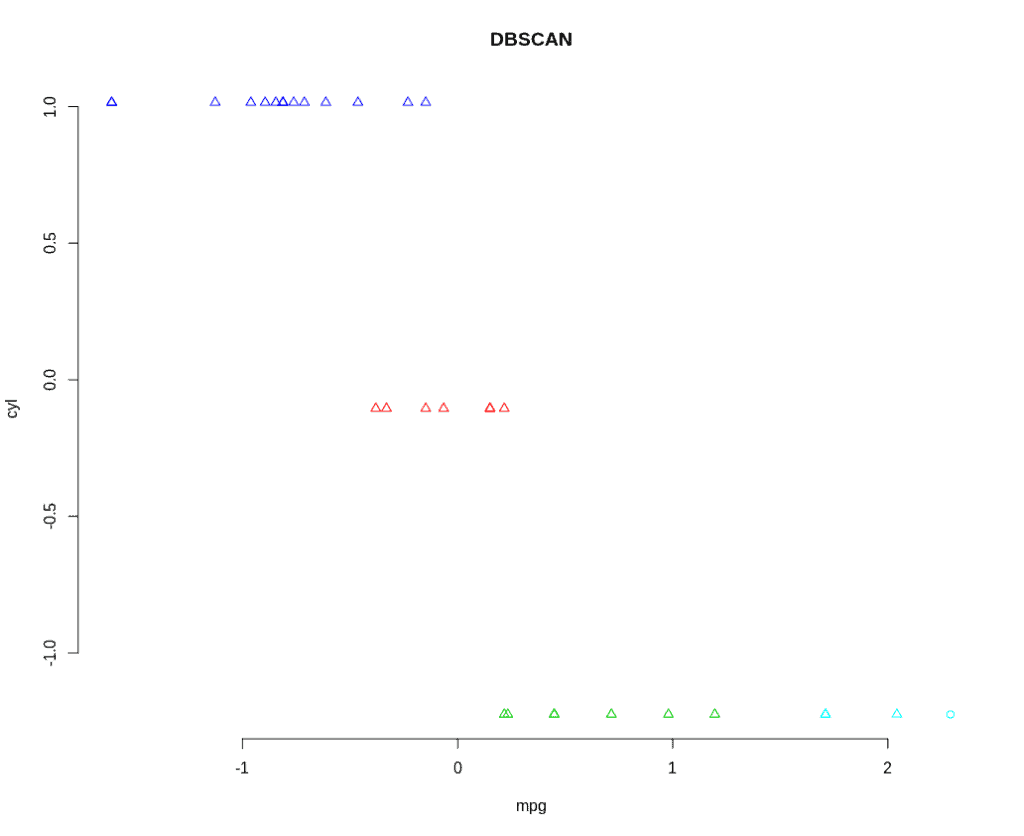
4.2 DBSCAN(基于密度的空间聚类)
DBSCAN 是一种基于密度的聚类算法,适用于噪声较多、聚类形状不规则的数据。
主要参数:
- ✅ EPS(epsilon):邻域的最大半径,控制“邻近”的定义
- ✅ MinPts:形成一个聚类所需的最小点数
参数选择建议:
- EPS 不宜过小,否则难以形成聚类
- EPS 过大会导致大部分点被归为一个聚类
- MinPts 通常建议为数据维度 + 1,最小值为 3
DBSCAN 可以很好地识别噪声点,适用于非球形聚类结构。
4.3 均值漂移(Mean-Shift)
均值漂移是一种基于质心的聚类算法。其核心思想是通过不断将窗口中心移动到窗口内点的均值位置,最终找到数据点的密度峰值。
算法流程简述:
- 初始化一个窗口 W
- 计算窗口内点的平均位置(质心)
- 将窗口移动到新的质心位置
- 重复上述步骤,直到窗口不再移动
该算法无需指定聚类数量,适用于图像处理、物体识别等场景。
4.4 谱聚类(Spectral Clustering)
谱聚类将数据点视为图上的节点,并通过图的谱分析将数据映射到低维空间进行聚类。
与其他聚类算法不同,谱聚类不要求聚类具有特定形状,适用于复杂结构的数据。
主要步骤如下:
- 构建图的邻接矩阵
- 计算拉普拉斯矩阵
- 对矩阵进行特征分解
- 在低维空间中进行聚类
谱聚类常用于社交网络分析、图像分割等领域。
5. 总结
本文介绍了几种无需预先指定聚类数量的聚类算法,包括:
- 层次聚类
- DBSCAN
- 均值漂移
- 谱聚类
这些算法各有特点,适用于不同数据结构和业务场景。在实际应用中,可以根据数据分布和目标选择合适的算法。如果后续我们对数据结构有了更清晰的认识,也可以使用 K-Means 等传统聚类算法进行进一步分析。
聚类是数据探索的重要工具,但只是数据科学流程中的一个环节。如果你对整个数据科学流程感兴趣,可以进一步了解 Spark MLlib 这样的综合性机器学习框架。