1. 什么是计算机视觉?
计算机视觉(Computer Vision,简称 CV)并不是一个新兴概念。早在 1960 年,Robert Fischell 就提出了“计算机视觉”这一术语,但其实际应用早在更早之前就已经出现。例如,世界上第一台相机于 1826 年发明,而科学家早在 1930 年就开始使用相机来分析图像数据。
如今,计算机视觉的应用场景越来越多,从帮助机器人导航到识别屏幕内容,计算机视觉正在帮助我们更高效地完成各种任务。
本篇文章将介绍计算机视觉的基本概念及其主要应用领域。
2. 计算机视觉的核心概念
计算机视觉(CV)是一门研究如何让计算机“理解”图像和视频的学科。
CV 的研究方法多种多样,但大多数研究集中在以下几个方向:
- 图像识别:系统能否区分猫和狗?
- 目标检测:系统能否在图像中找出所有人?
- 视频理解:系统能否判断一个人是朝摄像头走来还是远离?
CV 的三大主要应用方向:
- 视觉感知:逐帧分析图像或视频以识别场景中的对象,常用于自动驾驶和增强现实系统。
- 机器学习:通过大量数据训练模型,使其具备决策能力,例如 Apple 的 Face ID。
- 机器人技术:开发能够自主移动的机器,比如工厂机器人或灾后搜救无人机。
3. 常见计算机视觉技术
计算机视觉涉及多种技术,用于完成诸如目标检测、人脸识别、图像修复、姿态估计等任务。下面介绍几种常见技术。
3.1 目标检测(Object Detection)
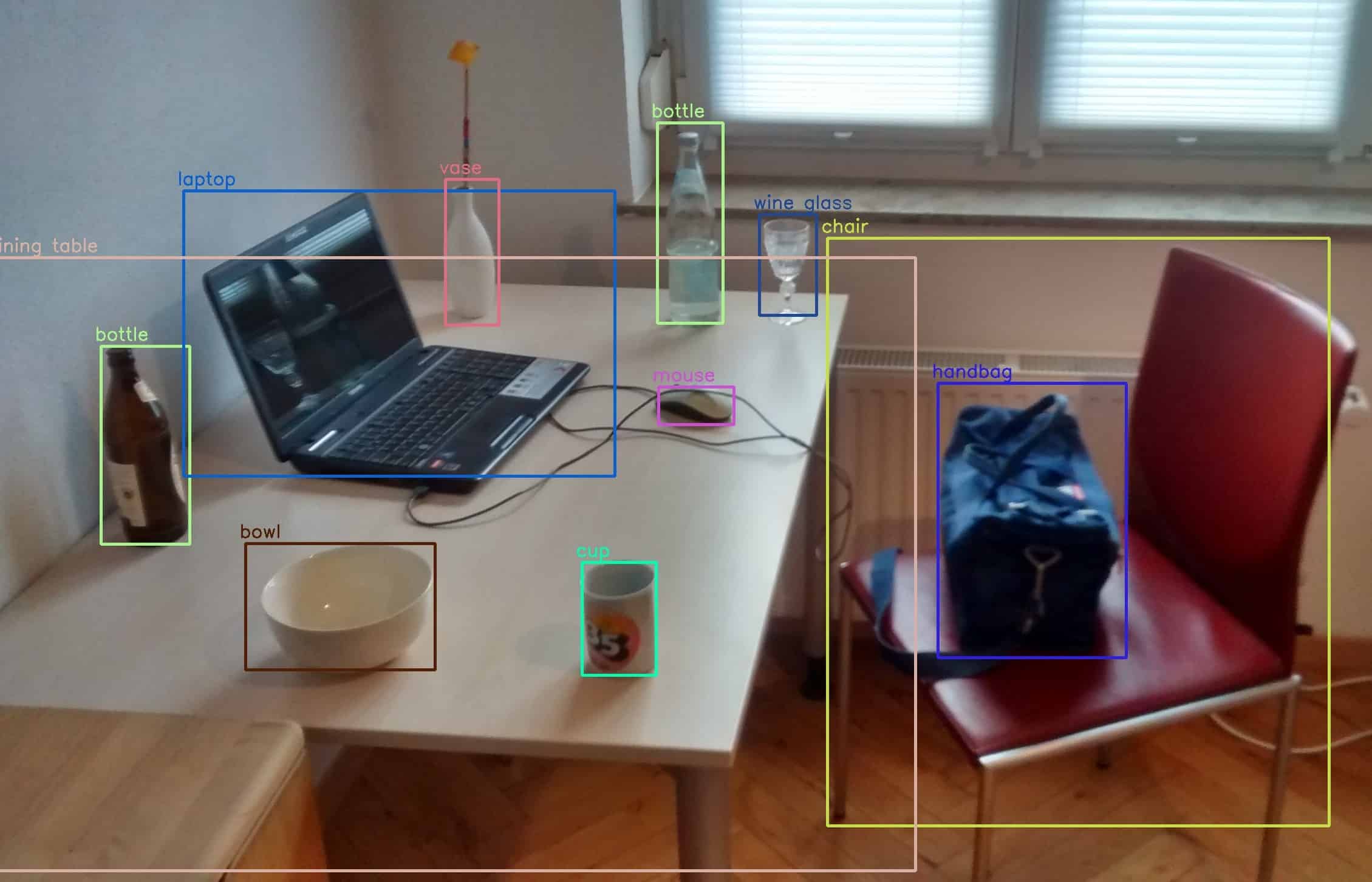
目标检测是 CV 领域的研究重点之一。近年来,越来越多的研究使用深度学习模型来识别图像或视频中的对象。其中最常见的是实例分割模型。
✅ 目标检测的作用:识别图像或视频中的特定对象。
✅ 实现方式:使用预训练模型或训练自定义模型,结合深度学习技术实现。
✅ 典型应用:自动驾驶系统中识别交通灯、行人、车辆等。
常用目标检测技术:
- Object Proposal Networks (OPNs)
- Mask R-CNNs
- Faster R-CNNs
- 实例分割(Instance Segmentation)
- 全卷积网络(Fully Convolutional Networks, FCNs)
示例:使用 OpenCV 的 DNN 模块结合 YOLOv3 模型进行目标检测:
3.2 语义分割(Semantic Segmentation)
语义分割是将图像划分为多个语义区域的过程。
与传统的像素分类不同,语义分割关注的是图像整体结构,例如识别图像中哪些区域是道路、行人或车辆。
✅ 典型用途:用于自动驾驶中的场景理解、人像抠图等。
⚠️ 挑战:光照变化、遮挡、物体形状差异等都会影响分割精度。
示例图像:

3.3 人脸检测与识别(Face Detection & Recognition)
人脸检测:识别图像中是否存在人脸。
人脸识别:进一步判断这些人脸属于谁。
✅ 应用场景:安防系统、社交媒体、手机解锁等。
⚠️ 踩坑提示:不同光照、角度、遮挡会显著影响识别效果,建议使用鲁棒性更强的模型如 MTCNN 或 FaceNet。
示例图像:

4. 图像处理 vs. 计算机视觉
图像处理(Image Processing)
图像处理是对图像进行变换、增强、滤波等操作,以提升图像质量或提取某些信息。例如:
- 拍照后进行美颜处理
- 医疗图像中的异常检测
✅ 特点:重在图像本身的处理,不强调“理解”。
计算机视觉(Computer Vision)
CV 更进一步,不仅处理图像,还要“理解”图像内容,比如:
- 识别图像中的物体
- 判断物体位置变化(运动追踪)
- 判断两个物体是否相同(目标识别)
✅ 特点:依赖大量数据训练模型,才能实现对新图像的准确理解。
5. 应用场景与行业应用
计算机视觉已被广泛应用于多个行业,以下是一些典型应用场景:
医疗行业
- 医学影像分析(如 X 光、CT、MRI)
- 自动诊断辅助系统
制造业
- 产品质量检测(如颜色、形状是否合格)
- 工业机器人视觉导航
零售行业
- 智能试衣镜分析顾客表情
- 无人商店的商品识别
游戏行业
- 检测玩家是否使用外挂
- 增强现实游戏中的环境识别
安防行业
- 视频监控中的人脸识别
- 人员进出管理
✅ 商业价值:通过 CV 技术提升用户体验、优化运营效率、增强安全性。
6. 总结
计算机视觉是一门复杂但极具前景的技术领域。它不仅帮助我们识别图像内容,还推动了自动驾驶、医疗诊断、安防监控等多个行业的进步。
本文介绍了 CV 的基本概念、关键技术及其在不同行业的应用。希望你对计算机视觉有了一个更清晰的认识,并能结合实际项目加以应用。