1. 简介
在本篇文章中,我们将深入探讨静态链接与动态链接的机制,了解它们如何帮助我们从汇编后的代码生成最终的可执行文件。
2. 可执行文件的生成过程
在深入链接方式之前,我们先快速回顾一下程序从源码到可执行文件的整个流程:
- 编写源代码
- 编译器将源码转换为中间表示(IR)
- 汇编器将其进一步转换为汇编语言代码
- 汇编器生成目标文件(Object File),其中包含机器码和符号表
- 链接器将目标文件与外部库进行链接,生成最终的可执行文件
最终的可执行文件结构如下图所示:
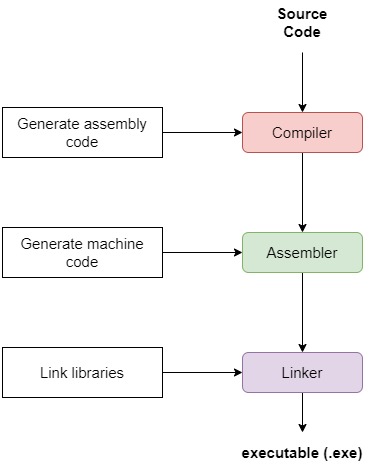
2.1 链接的作用
汇编器会将代码翻译成机器码,并为每个对象和指令分配一个内存地址。有些地址是虚拟的,比如相对于程序起始地址的偏移量。
当我们的程序引用了外部库中的函数(如 printf()),汇编器无法立即解析这些引用。这时就需要链接器来处理这些未解析的符号。
链接器的主要职责是:
- 将目标文件与所需库文件合并
- 解析所有未解析的外部引用
- 生成最终的可执行文件
常见的链接方式有两种:
- 静态链接(Static Linking)
- 动态链接(Dynamic Linking)
3. 静态链接
静态链接是指在编译时,链接器将依赖库的代码直接复制到最终的可执行文件中。这意味着生成的可执行文件是“自包含”的,包含了所有依赖的函数和数据。
例如,假设我们的程序调用了外部库 Library 中的 print() 函数:
// main.c
#include <stdio.h>
int main() {
printf("Hello, world!\n");
return 0;
}
在编译过程中,printf 的实现会被从标准库中复制到最终的可执行文件中。
静态链接过程如下图所示:
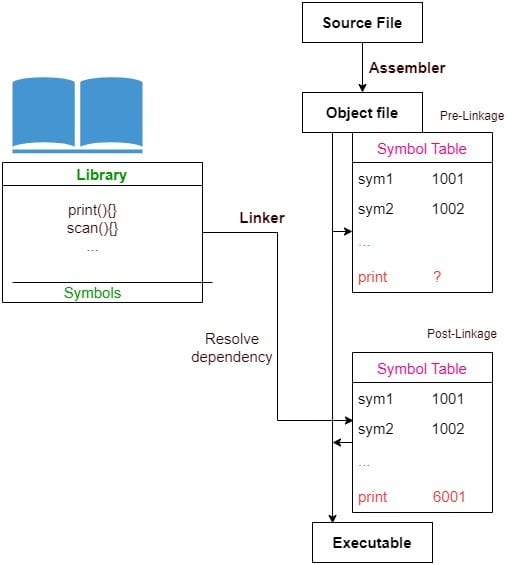
3.1 静态链接的优势
✅ 独立性强:生成的可执行文件不依赖外部库,便于部署
✅ 执行速度快:无需运行时动态加载和符号解析
✅ 安全性高:每个进程拥有独立的副本,互不干扰
✅ 版本一致性:不会因为系统库升级而导致兼容性问题
3.2 适用场景
- 对安全性要求高的场景(如金融交易系统)
- 嵌入式设备或资源受限环境(如路由器、IoT设备)
- 需要独立部署的命令行工具(如
busybox)
4. 动态链接
动态链接不会在编译时将依赖库的代码复制到可执行文件中,而是将这些依赖标记为“未解析符号”,在程序运行时才进行链接。
动态链接的核心机制如下:
- 可执行文件中仅保留外部函数的名称和库名
- 程序启动时,操作系统加载器会查找这些库并进行链接
- 多个程序可以共享同一个库的内存副本
例如,我们依然使用上面的 main.c 程序:
gcc -o hello main.c
默认情况下,GCC 会使用动态链接,printf 不会被复制到可执行文件中,而是运行时加载 libc。
4.1 动态链接的优势
✅ 节省磁盘和内存空间:多个程序共享同一份库
✅ 加载速度快(平均):首次加载后缓存命中率高
✅ 易于维护和升级:只需更新共享库即可影响所有使用它的程序
✅ 支持模块化设计:适合大型系统按需加载功能模块
4.2 适用场景
- 多个服务共享相同库的场景(如微服务架构中使用统一 SDK)
- 插件系统(如浏览器插件、IDE 插件)
- 桌面应用(如 Adobe 系列软件共享库)
4.3 动态链接的缺点:DLL Hell 问题
⚠️ DLL Hell 是动态链接中一个经典的版本冲突问题。
当多个程序依赖同一个共享库的不同版本,而系统中仅存在一个版本时,就可能导致程序崩溃。
例如:
- 应用 A 和 B 原本都使用
libxyz.so v1.0 - 升级系统后,
libxyz.so被更新为 v1.1 - v1.1 中某些 API 被修改或删除
- A 和 B 在运行时尝试调用旧版 API,导致崩溃
如下图所示:
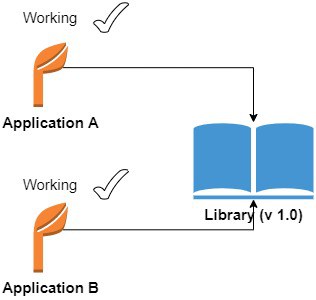
升级后:
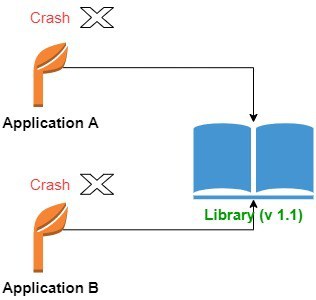
解决方法包括:
- 使用符号版本化(Symbol Versioning)
- 使用命名空间隔离不同版本
- 强化版本兼容性管理
5. 静态链接 vs 动态链接对比
| 特性 | 静态链接 | 动态链接 |
|---|---|---|
| 链接时机 | 编译时 | 运行时 |
| 库是否包含在可执行文件中 | ✅ | ❌ |
| 可执行文件大小 | 较大 | 较小 |
| 加载速度 | 较慢 | 较快 |
| 维护难度 | 高 | 低 |
| 安全性 | 高 | 低 |
| 兼容性风险 | 无 | 有(DLL Hell) |
6. 总结
静态链接和动态链接各有优劣,选择时应根据实际场景权衡:
- 静态链接适合对安全性、独立性和稳定性要求高的场景
- 动态链接适合资源受限、需要共享库、模块化设计的系统
✅ 建议:
- 嵌入式系统优先使用静态链接
- 服务端程序可结合动态链接提升资源利用率
- 开发插件或模块化系统时使用动态链接更灵活
合理使用链接方式,可以显著提升程序的性能、安全性和可维护性。