1. Introduction
In this tutorial, we’ll analyze two common processing techniques used by the operating system (OS). We usually need these two concepts when we have multiple processes waiting to be executed.
2. Key Definitions
Before getting into too much detail about concurrency and parallelism, let’s have a look at the key definitions used in the descriptions of these two processing methods:
- Multiprocessing: The employment of two or more central processing units (CPUs) within a single computer system is known as multiprocessing.
- Multithreading: This technique allows a single process to have multiple code segments, like threads. These segments run concurrently within the context of that process.
- Distributed Computing: A distributed computing system consists of multiple computer systems that are run as a single system. The computers in a system can be physically close to each other and connected by a local network, or they can be distant and connected by a wide area network.
- Multicore processor: It’s a single integrated processor that includes multiple core processing units. It’s also known as chip multiprocessor (CMP).
- Pipelining: It’s a technique where multiple instructions are overlapped during execution.
3. Concurrency
Concurrency actually means that multiple tasks can be executed in an overlapping time period. One of the tasks can begin before the preceding one is completed; however, they won’t be running at the same time. The CPU will adjust time slices per task and appropriately switch contexts. That’s why this concept is quite complicated to implement and especially debug.
3.1. How Does Concurrency Works?
The main aim of concurrency is to maximize the CPU by minimizing its idle time. While the current thread or process is waiting for input-output operations, database transactions, or launching an external program, another process or thread receives the CPU allocation. On the kernel side, the OS sends an interrupt to the active task to stop it:
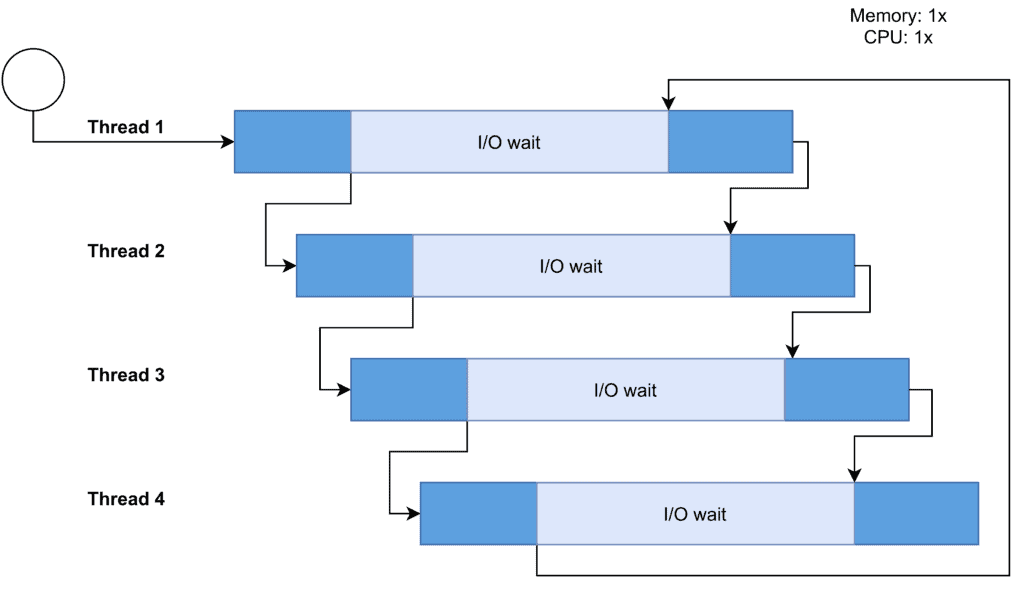
If two or more jobs are running on the same core of a single-core or multi-core CPU, they can access the same resources at the same time. Even though data read operations are performed in parallel and are safe, during write accesses, programmers must maintain data integrity.
Efficient process scheduling has a crucial role in a concurrent system. First-in, first-out (FIFO), shortest-job-first (SJF), and round-robin (RR) are popular task scheduling algorithms.
As we mentioned, it can be complicated to implement and debug concurrency, especially at the kernel level, so there can be starvation between processes when one of the tasks gets the CPU for too long. In order to prevent this situation, interrupts are designed, and they help the CPU allocate other processes. This is also called preemptive scheduling. The OS, like any other application, requires CPU time to adjust concurrent tasks.
4. Parallelism
Parallelism is the ability to execute independent tasks of a program in the same instant of time. Contrary to concurrent tasks, these tasks can run simultaneously on another processor core, another processor, or an entirely different computer that can be a distributed system. As the demand for computing speed from real-world applications increases, parallelism becomes more common and affordable.
4.1. How the Parallelism Works?
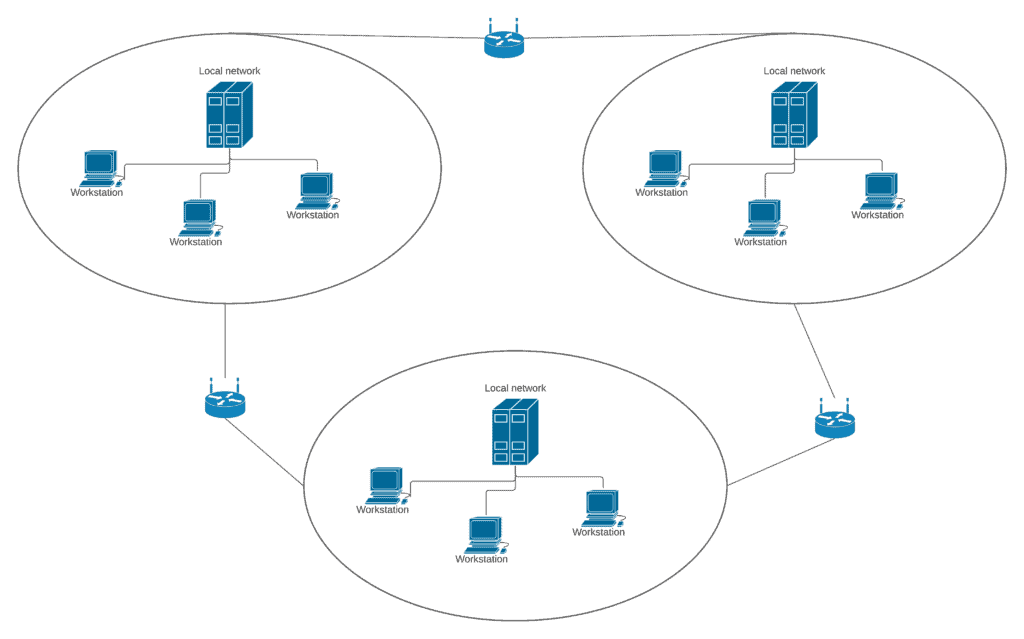
The figure below represents an example of distributed systems. As we previously mentioned, a distributed computing system consists of multiple computer systems, but it’s run as a single system. The computers that are in a system can be physically close to each other and connected by a local network, or they can be distant and connected by a wide area network:
Parallelism is a must for performance gain. There’s more than one benefit of parallelism, and we can implement it on different levels of abstractions:
- As we can see in the figure above, distributed systems are one of the most important examples of parallel systems. They’re basically independent computers with their own memory and IO.
- For example, we can have multiple functional units, like several adders and multipliers, managed by one instruction set.
- Process pipelining is another example of parallelism.
- Even at chip level, parallelism can increase concurrency in operations.
- We can also take advantage of parallelism by using multiple cores on the same computer. This makes various edge devices, like mobile phones, possible.
5. Concurrency vs Parallelism
Let’s take a look at how concurrency and parallelism work with the below example. As we can see, there are two cores and two tasks. In a concurrent approach, each core is executing both tasks by switching among them over time. In contrast, the parallel approach doesn’t switch among tasks, but instead executes them in parallel over time:
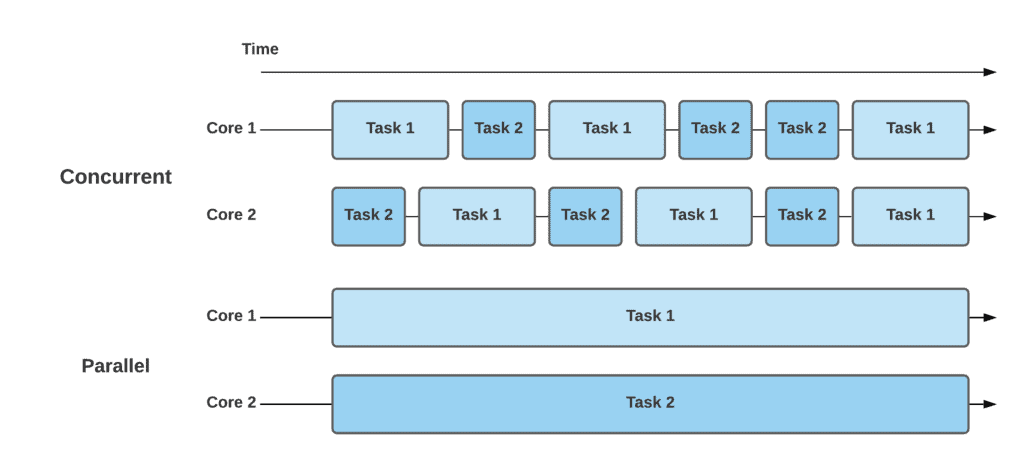
This simple example for concurrent processing can be any user-interactive program, like a text editor. In such a program, there can be some IO operations that waste CPU cycles. When we save a file or print it, the user can concurrently type. The main thread launches many threads for typing, saving, and similar activities concurrently. They may run in the same time period; however, they aren’t actually running in parallel.
In contrast, we can give an example of Hadoop-based distributed data processing for a parallel system. It entails large-scale data processing on many clusters and it uses parallel processors. Programmers see the entire system as a single database.
5.1. Potential Pitfalls in Concurrency and Parallelism
As we noted earlier in this tutorial, concurrency and parallelism are complex ideas and require advanced development skills. Otherwise, there could be some potential risks that jeopardize the system’s reliability.
For example, if we don’t carefully design the concurrent environment, there can be deadlocks, race conditions, or starvation.
Similarly, we should also be careful when we’re doing parallel programming. We need to know where to stop and what to share. Otherwise, we could face memory corruption, leaks, or errors.
5.2. Programming Languages That Support Concurrency and Parallelism
Simultaneously executing processes and threads is the main idea that concurrent programming languages use. On the other hand, languages that support parallelism make programming constructs able to be executed on more than one machine. Instruction and data stream are key terms for the parallelism taxonomy.
These languages include some important concepts. Instead of learning the language itself, it would be better to understand the fundamentals of these subjects:
- Systems programming: It’s basic OS and hardware management that can include system call implementation and writing a new scheduler for an OS.
- Distributed computing: As we mentioned earlier, it’s a must for parallel CPUs to be utilized.
- Performance computing: This concept is necessary for CPU resource optimization.
Now let’s categorize the different languages, frameworks, and APIs:
- Shared memory languages: Orca, Java, C (with some additional libraries)
- Object-oriented parallelism: Java, C++, Nexus
- Distributed memory: MPI, Concurrent C, Ada
- Message passing: Go, Rust
- Parallel functional languages: LISP
- Frameworks and APIs: Spark, Hadoop
These are just some of the different languages which we can use for concurrency and parallelism. Instead of the whole language itself, there are library extensions, such as POSIX thread library for C programming language. With this library, we can implement almost all of the concurrent programming concepts, such as semaphores, multi-threads, and condition variables.
6. Conclusion
In this article, we discussed how concurrency and parallelism work, and the differences between them. We shared some examples related to these two concepts and explained why we need them in the first place. Lastly, we gave a brief summary of the potential pitfalls in concurrency and parallelism and listed the programming languages that support these two important concepts.