1. 概述
本文将深入讲解 CPU 调度机制,包括调度的基本概念、调度状态、调度准则以及常见调度算法。对于 Java 开发者来说,理解底层调度机制有助于更好地掌握线程调度、并发编程等高级主题,也能更有效地分析和优化系统性能。
2. 基本概念与进程状态
2.1 什么是进程?
进程(Process)是一个程序的执行实例。它不仅仅是一段代码,更是操作系统中一个动态的执行单位。虽然代码存储在磁盘上,但只有在被加载到内存并由操作系统调度执行时,才真正“活”了起来。
在多任务操作系统中,我们常常可以一边写文档,一边听音乐,还能开着几十个浏览器标签页。这背后其实是操作系统在多个进程之间快速切换,营造出“同时运行”的假象。
这种机制被称为 CPU 时间共享(Time-Sharing),其核心在于 上下文切换(Context Switch):操作系统暂停当前进程,保存其状态,然后加载另一个进程的状态并继续执行。
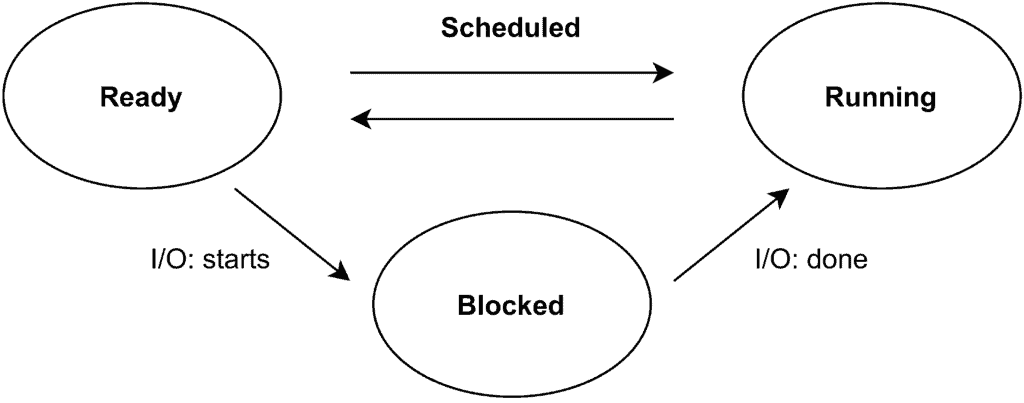
2.2 进程的三种基本状态
每个进程在其生命周期中会经历以下三种状态:
- ✅ 运行(Running):正在 CPU 上执行的进程。
- ✅ 就绪(Ready):已经准备好可以运行,但尚未被调度器选中。
- ✅ 阻塞(Blocked):等待某个事件完成(如 I/O 操作)才能继续执行。
进程状态之间可以相互转换,如下图所示:
3. 调度准则与调度算法
3.1 调度指标
为了评估调度算法的优劣,我们通常关注以下几个指标:
- ✅ 周转时间(Turnaround Time):从进程提交到执行完成的总时间。计算方式为:完成时间 - 到达时间。
- ✅ 响应时间(Response Time):从进程提交到第一次被调度执行的时间。
- ✅ 等待时间(Waiting Time):进程在就绪队列中等待 CPU 的总时间。
- ✅ 吞吐量(Throughput):单位时间内完成的进程数量。
- ✅ CPU 利用率(CPU Utilization):CPU 用于执行进程的时间比例。
在本文中,我们将主要围绕 周转时间 和 响应时间 来比较不同调度算法的表现。
3.2 先来先服务(FIFO / FCFS)
先来先服务(First In, First Out,FIFO) 是最简单的调度算法之一,也称为 先到先服务(First-Come, First-Served,FCFS)。
特点:
- ✅ 实现简单
- ❌ 平均等待时间高
- ❌ 易引发“车队效应(Convoy Effect)”
示例
假设有三个进程 X、Y、Z,分别运行 80s、10s、10s,且按顺序到达:
平均周转时间 = (80 + 100 + 120) / 3 = 100s
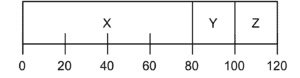
可以看到,Y 和 Z 需要等待 X 完成后才能执行,造成资源浪费。
3.3 最短作业优先(SJF)
最短作业优先(Shortest Job First,SJF) 优先调度运行时间最短的进程。
特点:
- ✅ 平均周转时间最小
- ❌ 实现复杂(需预知运行时间)
- ❌ 对响应时间优化有限
示例
假设 X 运行 80s,Y 和 Z 各运行 10s,但 Y 和 Z 在 20s 时到达:
平均周转时间 = (80 + 80 + 100) / 3 = 86.6s
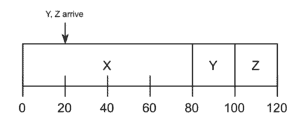
虽然比 FIFO 更优,但如果进程不是同时到达,SJF 仍可能造成等待。
3.4 轮转调度(Round Robin,RR)
轮转调度(Round Robin) 将 CPU 时间划分为固定长度的“时间片(Time Slice)”,每个进程执行一个时间片后被挂起,进入就绪队列末尾。
特点:
- ✅ 响应时间好
- ✅ 公平性强
- ✅ 实现较复杂
- ⚠️ 时间片大小需权衡
示例
假设时间片为 1s,三个进程 X、Y、Z 同时到达:
平均响应时间 = (0 + 1 + 2) / 3 = 1s
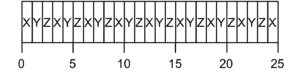
RR 能有效减少响应时间,适合交互式系统,但频繁上下文切换可能带来性能开销。
4. 总结
本文介绍了 CPU 调度的核心概念和常见调度算法,包括:
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| FIFO | 简单直观 | 易造成等待 | 教学、简单系统 |
| SJF | 周转时间最小 | 需预知运行时间 | 批处理系统 |
| RR | 响应时间好 | 切换开销大 | 交互式系统 |
理解这些调度机制不仅有助于我们更好地分析操作系统行为,也能帮助我们在开发多线程应用时做出更合理的调度策略选择。比如在 Java 中使用线程池时,调度策略的选取也应参考这些底层原理。
在实际开发中,操作系统通常结合多种调度策略进行优化,例如 Linux 的 CFS(完全公平调度器)就是一种基于时间片和权重的混合调度算法。