1. 引言
在自然语言处理(NLP)领域,解析(Parsing) 是理解句子结构的重要手段。成分解析(Constituency Parsing)和依存句法解析(Dependency Parsing)是两种主流的解析方法,它们分别基于不同的语法体系,适用于不同的任务场景。
本文将通过一个简单句子的解析示例,说明这两种方法的区别,并探讨它们的挑战与应用场景。
2. 解析的基本概念
解析的目标是从给定句子中构建一棵解析树(Parse Tree),以揭示其语法结构。解析树通常由词和语法成分构成,展示词语之间的结构关系。
2.1 成分解析(Constituency Parsing)
✅ 成分解析基于上下文无关文法(CFG),将句子划分为多个“成分”(constituents),每个成分代表一个语法单位,如名词短语(NP)、动词短语(VP)、介词短语(PP)等。
例如句子 “I saw a fox”,其成分解析树如下图所示:
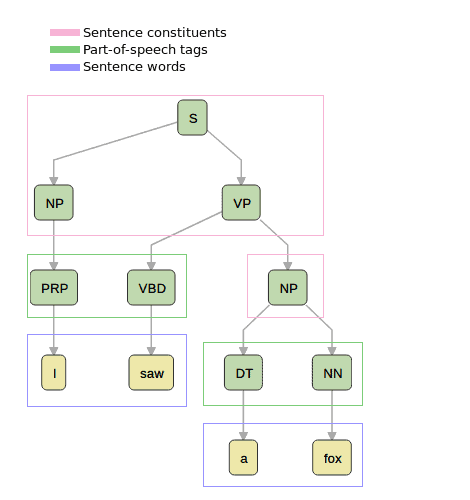
树中:
- 叶子节点是句子中的实际单词
- 非叶子节点代表语法成分(如 NP、VP、S 等)
- 根节点是整个句子(S)
这个解析树说明了句子的结构:主语是名词短语“NP”(即“I”),谓语是动词短语“VP”(即“saw a fox”),动词短语又由动词“saw”和宾语“NP”组成。
2.2 依存句法解析(Dependency Parsing)
✅ 依存句法解析不使用短语结构,而是通过词之间的依赖关系来表示句子结构。
依存句法树是一个有向图 G = (V, E),其中:
- V 是句子中的单词集合
- E 是有向边,表示两个词之间的语法依赖关系
- 每条边都有一个类型,表示语法关系(如 nsubj、dobj、prep 等)
例如,句子 “I saw a fox”的依存句法树如下:
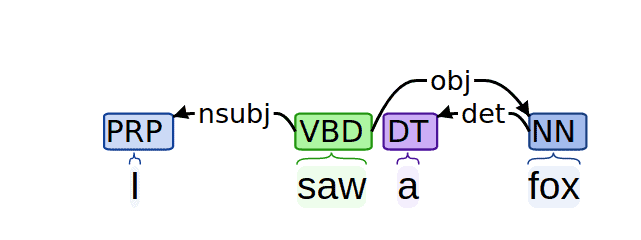
在这棵树中:
- 动词“saw”是根节点
- “I”通过 nsubj 边依赖于“saw”,表示“I”是“saw”的主语
- “fox”通过 dobj 边依赖于“saw”,表示“fox”是“saw”的宾语
⚠️ 与成分解析不同,依存句法解析更关注词之间的直接关系,而不是短语结构。
3. 自然语言解析的挑战
解析自然语言远比解析编程语言复杂,主要原因如下:
- ✅ 歧义性:一个句子可能有多个合法的解析结构,例如 “I shot an elephant in my pajamas” 有两种合理理解
- ✅ 语义模糊性:虽然语法上合法,但某些解析结构在语义上不合理
- ✅ 上下文依赖性:人类能根据上下文快速判断正确结构,但算法难以做到
为了解决这些问题,现代解析器通常使用监督学习模型,训练时使用人工标注的解析树数据。这样模型能学习到常见的结构偏好,提高解析准确率。
4. 应用场景对比
| 场景 | 推荐使用 | 原因 |
|---|---|---|
| 提取主谓宾三元组 | ✅ 依存句法解析 | 直接提供 subject、object 等信息 |
| 多语言自由语序处理 | ✅ 依存句法解析 | 更适应语序灵活的语言结构 |
| 子短语提取 | ✅ 成分解析 | 直接提供短语边界信息 |
| 语义角色标注(SRL) | 可选 | 两者均可,依任务而定 |
| 问答系统 | 可选 | 依存句法解析更适合提取结构化信息 |
5. 总结
- ✅ 成分解析和依存句法解析是两种主流的句子结构分析方法
- ✅ 成分解析基于上下文无关文法,关注短语结构;依存句法解析则关注词之间的依赖关系
- ✅ 成分解析适合提取短语结构信息,依存句法则更适合提取主谓宾等结构化信息
- ✅ 实际应用中应根据任务需求选择合适的解析方法
无论你是在做信息抽取、语义分析还是问答系统,理解这两种解析方法的差异和适用场景,将有助于你更好地设计和实现 NLP 流程。