1. 概述
在机器学习中,大多数算法只关注输入数据的数值,而不会考虑单位或量纲。
如果没有特别处理,算法会默认数值更大的特征更重要。
为了避免这种误解,我们需要使用 特征缩放(Feature Scaling) 来对特征进行标准化或归一化处理。
2. 什么是特征缩放?
特征缩放是一种数据预处理技术,主要用于统一不同特征的数值范围或分布。常用的两种方法是:
- 归一化(Normalization):将数据缩放到 [0,1] 区间
- 标准化(Standardization):将数据转换为均值为 0、标准差为 1 的分布
这两种方法各有适用场景,我们会在后面详细讨论。
3. 为什么需要特征缩放?
3.1 避免特征权重误判
不同特征的取值范围差异很大。例如:
- 汽车的发动机排量可能在几百范围内
- 百公里油耗通常在几十以内
如果不对这些特征进行处理,算法可能会认为发动机排量比油耗更重要,从而影响模型训练效果。
3.2 加快模型收敛速度
像神经网络这类依赖梯度下降的算法,特征缩放能显著加快收敛速度。
✅ 小贴士:特征缩放不是万能的,有些模型(如决策树)对特征缩放不敏感。
4. 何时使用特征缩放?
一般来说,只要算法涉及距离计算,就应该使用特征缩放。
以下算法对特征缩放敏感:
- 主成分分析(PCA)
- 支持向量机(SVM)
- K近邻(KNN)
- 逻辑回归(Logistic Regression)
- K均值聚类(K-Means)
4.1 示例:SVM 模型对比
我们以 R 语言中的尿液数据集为例:
svmfit.poly.noscale = svm(r ~ ., data = urine, kernel = "polynomial", cost = 7, scale = FALSE)
运行后会出现警告:
WARNING: reaching max number of iterations
并且分类效果较差:
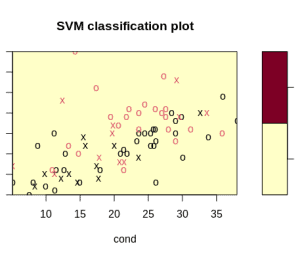
加上特征缩放后:
svmfit.poly.scale = svm(r ~ ., data = urine, kernel = "polynomial", cost = 7, scale = TRUE)
不再出现警告,并且分类更清晰:
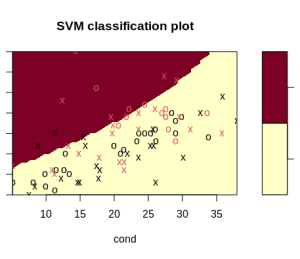
4.2 什么时候不需要特征缩放?
- 序数型特征(Ordinal Features):如评分等级,缩放后反而会改变其顺序含义
- 树模型(Tree-based Models):如决策树、随机森林,缩放对其影响不大
5. 常见的特征缩放方法
5.1 归一化(Min-Max)
将数据缩放到 [0, 1] 范围,适用于分布不呈正态、标准差较小的情况。
公式:

⚠️ 缺点:对异常值敏感。
5.2 标准化(Standardization)
假设数据服从正态分布,将其转换为均值为 0、标准差为 1 的形式。
公式:

其中:
均值
 计算公式:
计算公式:
标准差
 计算公式:
计算公式:
⚠️ 缺点:要求数据近似正态分布,否则效果不佳。
5.3 最大绝对值缩放(Max Abs)
将最大绝对值缩放为 1,适用于稀疏数据。
特点:
- 不改变数据的稀疏性
- 对异常值敏感(如果数据全为正)
5.4 鲁棒缩放(Robust)
基于四分位数(IQR)进行缩放,能有效抵抗异常值影响。
公式:
X_scaled = (X - median) / IQR
✅ 优点:抗异常值能力强
5.5 分位数变换(Quantile Transformer)
将数据映射为接近正态分布,常用于处理异常值较多的情况。
5.6 幂变换(Power Transformer)
适用于数据分布偏斜或方差不稳定的情况,常用方法包括 Box-Cox 和 Yeo-Johnson。
5.7 单位向量缩放(Unit Vector)
将特征向量缩放为单位长度,常用于图像处理(如 RGB 像素值在 0~255 之间)。
6. 总结
特征缩放是机器学习预处理中的关键步骤,它可以帮助我们:
- 避免特征权重误判
- 加快模型收敛速度
- 提高模型性能
但也要注意:
- 并非所有模型都需要特征缩放(如树模型)
- 不同缩放方法适合不同数据分布
- 可以尝试多种缩放方式比较效果
✅ 建议实践:在训练模型前,尝试使用原始数据、标准化数据和归一化数据分别建模,观察哪种方式效果最好。
相关文章: