1. Introduction
In this tutorial, we’ll show a matrix approach to do 2D convolution.
2. Convolution
Convolution is fundamental in signal processing, computer vision, and machine learning. It applies a filter or kernel to an input image or signal and extracts relevant features.
Typical implementations use a sliding-window operation where the kernel moves across the input image. For each placement of the kernel  on the input image
on the input image  , we compute the dot product of the kernel and the overlapping image pixels:
, we compute the dot product of the kernel and the overlapping image pixels:
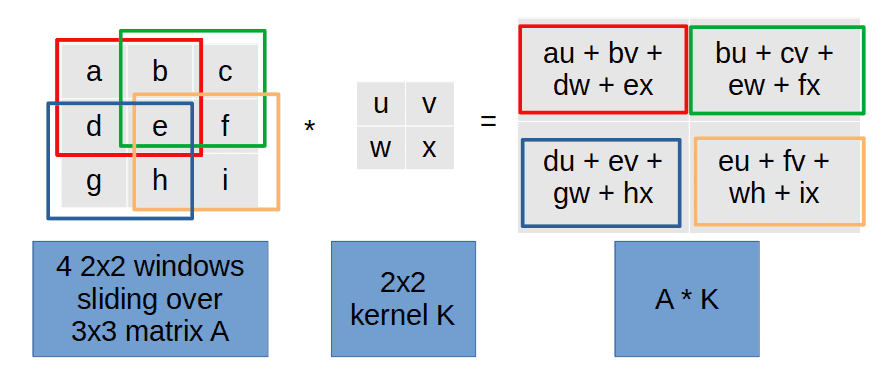
However, the kernel approach can be computationally expensive, especially for large images and kernels. An alternative is to compute convolution as matrix multiplication, which can be a more efficient approach.
3. Matrix Construction of a 2D Convolution
Let be a matrix of size  and a
and a  kernel. For convenience, let
kernel. For convenience, let  .
.
To calculate the convolution  , we need to calculate the matrix-vector multiplication
, we need to calculate the matrix-vector multiplication  where:
where:
-
 is a
is a  block matrix we get from the kernel
block matrix we get from the kernel -
 is a row vector with the
is a row vector with the  elements of concatenated row by row
elements of concatenated row by row -
 is a row vector of
is a row vector of  elements which can be reshaped into a
elements which can be reshaped into a  matrix by splitting the row vector into
matrix by splitting the row vector into  rows of elements
rows of elements
3.1. How to Compute the Block Matrix?
It’s a three-step process.
First, we define the  matrixes, which represent all the horizontal sliding windows for kernel row
matrixes, which represent all the horizontal sliding windows for kernel row  :
:
![[K_i = \begin{bmatrix}0_{0} & K_{i,1} & \hdots & K_{i, k} & 0_{t - 1} \\ 0_{1} & K_{i,1}& \hdots & K_{i, k} & 0_{t - 2} \\ \hdots & \hdots & \hdots & \hdots & \hdots \\ 0_{t-1} & K_{i,1} & \hdots & K_{i, k}& 0_{0}\end{bmatrix}]](/wp-content/ql-cache/quicklatex.com-6f7f068daacdac2ceaf57dfdc63c7209_l3.svg "Rendered by QuickLaTeX.com")
with  a zero row vector of size
a zero row vector of size  and
and  the
the  -th element of row , i.e. the element at row and column in matrix .
-th element of row , i.e. the element at row and column in matrix .  stands for an empty vector.
stands for an empty vector.
In the second step, we complete horizontal sliding by constructing a  matrix
matrix  . We define as the horizontal concatenation of matrix blocks :
. We define as the horizontal concatenation of matrix blocks :
![[\hat{K} = (K_1 K_2 \hdots K_k)]](/wp-content/ql-cache/quicklatex.com-6fa1401a5d8dadf5d6770febf24a0df1_l3.svg "Rendered by QuickLaTeX.com")
The final step is to represent vertical window sliding. We do that by padding with zero matrices (denoted  ):
):
![[M = \begin{bmatrix}0_{t\times 0} & \hat{K} & 0_{t\times n(t-1)} \\ 0_{t\times n} & \hat{K} & 0_{t\times n(t-2)} \\ \hdots & \hdots & \hdots \\ 0_{t\times n(t-1)} & \hat{K} & 0_{t\times 0} \end{bmatrix}]](/wp-content/ql-cache/quicklatex.com-88f8dbdc3fc9bfad50067d01c2cb5bd6_l3.svg "Rendered by QuickLaTeX.com")
All that is now left to do is compute  , where
, where  is a row-vector form of the input matrix .
is a row-vector form of the input matrix .
4. Example
Let’s construct the matrix for a  matrix convolved with a
matrix convolved with a  kernel :
kernel :
![[A = \begin{bmatrix}a_{1,1} & a_{1,2} & a_{1,3} \\ a_{2,1} & a_{2,2} & a_{2,3} \\ a_{3,1} & a_{3,2} & a_{3,3}\end{bmatrix}\qquad K = \begin{bmatrix}k_{1,1} & k_{1,2} \\ k_{2,1} & k_{2,2} \end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-3d3347457202f68f3f2476e704ae03df_l3.svg "Rendered by QuickLaTeX.com")
In this example, we have  . First, we build the blocks
. First, we build the blocks  and
and  :
:
![[ K_1 = \begin{bmatrix}k_{1,1} & k_{1,2} & 0 \\ 0 & k_{1,1} & k_{1,2}\end{bmatrix}, K_2 = \begin{bmatrix}k_{2,1} & k_{2,2} & 0 \\ 0 & k_{2,1} & k_{2,2}\end{bmatrix}, ]](/wp-content/ql-cache/quicklatex.com-cb30dbefff2c53dc8b10d3a59cfa8b76_l3.svg "Rendered by QuickLaTeX.com")
and get after concatenation:
![[ \hat{K} = \begin{bmatrix}k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2} & 0 \\ 0 & k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2}\end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-2f944020b98e816eab74351c12f1e011_l3.svg "Rendered by QuickLaTeX.com")
The final step is to pad the matrix with blocks of zeros:
![[\setcounter{MaxMatrixCols}{20} M = \begin{bmatrix}k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2} & 0 & 0 & 0 & 0 \\ 0 & k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2} & 0 & 0 & 0 \\ 0 & 0 & 0 & k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2} & 0 \\ 0 & 0 & 0 & 0 & k_{1,1} & k_{1,2} & 0 & k_{2,1} & k_{2,2}\end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-95afe32e7e95e78b72471d5162fee24c_l3.svg "Rendered by QuickLaTeX.com")
The zeros in the  matrix blocks are highlighted in red, and is exactly of the size
matrix blocks are highlighted in red, and is exactly of the size  .
.
Now, let’s rewrite as :
![[\setcounter{MaxMatrixCols}{20} v = \begin{bmatrix}a_{1,1} & a_{1,2} & a_{1,3} & a_{2,1} & a_{2,2} & a_{2,3} & a_{3,1} & a_{3,2} & a_{3,3}\end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-b0267820ed8c4a12cfbc8f1501a0d3f5_l3.svg "Rendered by QuickLaTeX.com")
Finally, we multiply and :
![[ \setcounter{MaxMatrixCols}{20} Mv^T = \begin{bmatrix} a_{1,1}k_{1, 1} + a_{1,2}k_{1, 2} + a_{1,3}\cdot 0 + a_{2,1}k_{2, 1} + a_{2,2}k_{2, 2} + a_{2,3}\cdot 0 + a_{3,1}\cdot 0 + a_{3,2}\cdot 0 + a_{3,3} \cdot 0 \\a_{1,1}\cdot 0 + a_{1,2}k_{1, 1} + a_{1,3}k_{1,2} + a_{2,1}\cdot 0 + a_{2,2}k_{2, 1} + a_{2,3}k_{2,2} + a_{3,1}\cdot 0 + a_{3,2}\cdot 0 + a_{3,3} \cdot 0 \\a_{1,1}\cdot 0 + a_{1,2}\cdot 0 + a_{1,3} \cdot 0 + a_{2,1}k_{1, 1} + a_{2,2}k_{1, 2} + a_{2,3}\cdot 0 + a_{3,1}k_{2, 1} + a_{3,2}k_{2, 2} + a_{2,3}\cdot 0 \\a_{1,1}\cdot 0 + a_{1,2}\cdot 0 + a_{1,3} \cdot 0 + a_{2,1}\cdot 0 + a_{2,2}k_{1, 1} + a_{2,3}k_{1,2} + a_{3,1}\cdot 0 + a_{3,2}k_{2, 1} + a_{3,3}k_{2,2} \end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-fd2de441211bb90706526efdf11780dd_l3.svg "Rendered by QuickLaTeX.com")
Since  , we obtain the result of the convolution as a
, we obtain the result of the convolution as a  matrix by simplifying and reshaping :
matrix by simplifying and reshaping :
![[ \begin{bmatrix}a_{1,1}k_{1, 1} + a_{1,2}k_{1, 2} + a_{2,1}k_{2, 1} + a_{2,2}k_{2, 2} & a_{1,2}k_{1, 1} + a_{1,3}k_{1,2} + a_{2,2}k_{2, 1} + a_{2,3}k_{2,2} \\ a_{2,1}k_{1, 1} + a_{2,2}k_{1, 2} + a_{3,1}k_{2, 1} + a_{3,2}k_{2, 2} & a_{2,2}k_{1, 1} + a_{2,3}k_{1,2} + a_{3,2}k_{2, 1} + a_{3,3}k_{2,2} \\\end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-51f1326aa848eab69d533a995f10e65e_l3.svg "Rendered by QuickLaTeX.com")
4.1. Numeric Example
Let’s say and are:
![[A = \begin{bmatrix}1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9\end{bmatrix} \qquad K = \begin{bmatrix}10 & 11 \\ 12 & 13\end{bmatrix}]](/wp-content/ql-cache/quicklatex.com-8f905665bd20d1103f404bab515262ad_l3.svg "Rendered by QuickLaTeX.com")
The corresponding , , and are as follows:
![[ v^T = \begin{bmatrix}1 \\ 2 \\ 3 \\ 4 \\ 5 \\ 6 \\ 7 \\ 8 \\ 9\end{bmatrix} \qquad\hat{K} = \begin{bmatrix}10 & 11 & 0 & 12 & 13 & 0 \\ 0 & 10 & 11 & 0 & 12 & 13\end{bmatrix} \qquad M = \begin{bmatrix}10 & 11 & 0 & 12 & 13 & 0 & 0 & 0 & 0 \\ 0 & 10 & 11 & 0 & 12 & 13 & 0 & 0 & 0 \\ 0 & 0 & 0 & 10 & 11 & 0 & 12 & 13 & 0 \\ 0 & 0 & 0 & 0 & 10 & 11 & 0 & 12 & 13\end{bmatrix}]](/wp-content/ql-cache/quicklatex.com-ace75c255be578b4a1c95b30636d50cc_l3.svg "Rendered by QuickLaTeX.com")
The result of the convolution is:
![[Mv^T = \begin{bmatrix}1\cdot 10 + 2\cdot 11 + 3\cdot 0 + 4\cdot 12 + 5\cdot 13 + 6\cdot 0 + 0\cdot 7 + 0\cdot 8 + 0\cdot 9 \\1\cdot 0 + 2\cdot 10 + 3\cdot 11 + 4\cdot 0 + 5\cdot 12 + 6\cdot 13 + 0\cdot 7 + 0\cdot 8 + 0\cdot 9 \\0\cdot 1 + 0\cdot 1 + 0\cdot 3 + 4\cdot 10 + 5\cdot 11 + 6\cdot 0 + 7\cdot 12 + 8\cdot 13 + 6\cdot 0 \\0\cdot 1 + 0\cdot 1 + 0\cdot 3 + 4\cdot 0 + 5\cdot 10 + 6\cdot 11 + 7\cdot 0 + 8\cdot 12 + 9\cdot 13 \\ \end{bmatrix} =\begin{bmatrix}145 \\191 \\283 \\329 \\\end{bmatrix} ]](/wp-content/ql-cache/quicklatex.com-aa9df079d71560b7f407bb1488d49e86_l3.svg "Rendered by QuickLaTeX.com")
We can reshape  :
:
![[\begin{bmatrix}1\cdot 10 + 2\cdot 11 + 4\cdot 12 + 5\cdot 13 & 2\cdot 10 + 3\cdot 11 + 5\cdot 12 + 6\cdot 13 \\ 4\cdot 10 + 5\cdot 11 + 7\cdot 12 + 8\cdot 13 & 5\cdot 10 + 6\cdot 11 + 8\cdot 12 + 9\cdot 13 \\\end{bmatrix} =\begin{bmatrix}145 & 191 \\283 & 329 \\\end{bmatrix}]](/wp-content/ql-cache/quicklatex.com-1bba88dc092d5d15319ff2ea34f2f0ef_l3.svg "Rendered by QuickLaTeX.com")
5. Advantages of the Matrix Approach
Matrix multiplication is easier to compute compared to a 2D convolution because it can be efficiently implemented using hardware-accelerated linear algebra libraries, such as BLAS (Basic Linear Algebra Subprograms). These libraries have been optimized for many years to achieve high performance on a variety of hardware platforms.
In addition, the memory access patterns for matrix multiplication are more regular and predictable compared to 2D convolution, which can lead to better cache utilization and fewer memory stalls. This can result in faster execution times and better performance.
6. Conclusion
In this article, we showed how to compute a convolution as a matrix-vector multiplication. The approach can be faster than the usual one with sliding since matrix operations have fast implementations on modern computers.