1. 简介
树的遍历是指以某种顺序访问树中所有节点,且每个节点仅访问一次。
树的遍历方式有很多,通常根据访问节点的顺序分为不同的类型。从遍历方向来看,主要分为两类:深度优先(Depth-First)和广度优先(Breadth-First)。
在本篇中,我们重点讨论深度优先遍历的三种方式:中序(In-order)、后序(Post-order)和前序(Pre-order)遍历。我们会以一棵二叉树为例进行讲解,因为结构清晰,便于理解和跟踪。但请记住:这些遍历思想同样适用于图结构。
2. 示例二叉树
下图是一棵典型的二叉搜索树(Binary Search Tree, BST),后续的遍历示例都会基于它进行说明:
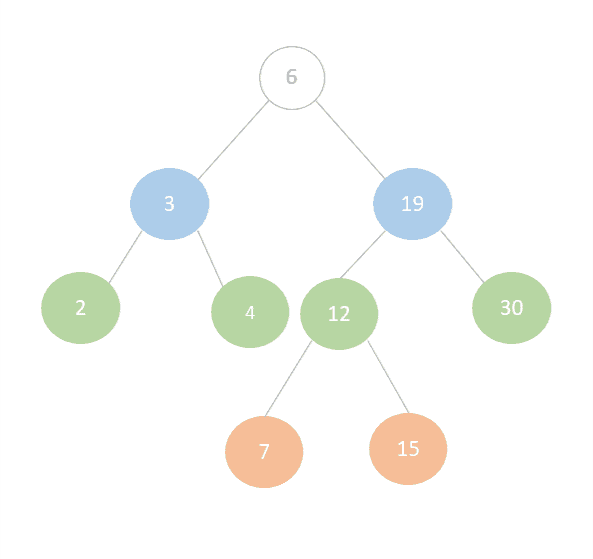
需要注意的是:在图结构中我们可以从任意节点开始遍历,但在二叉树中,我们通常从根节点开始遍历,在这个例子中是节点 6。
3. 中序遍历(In-order Traversal,LNR)
中序遍历的顺序是:左子树 ➝ 当前节点 ➝ 右子树,简称 LNR(Left-Node-Right)。
递归执行步骤如下:
- 遍历左子树
- 访问当前节点
- 遍历右子树
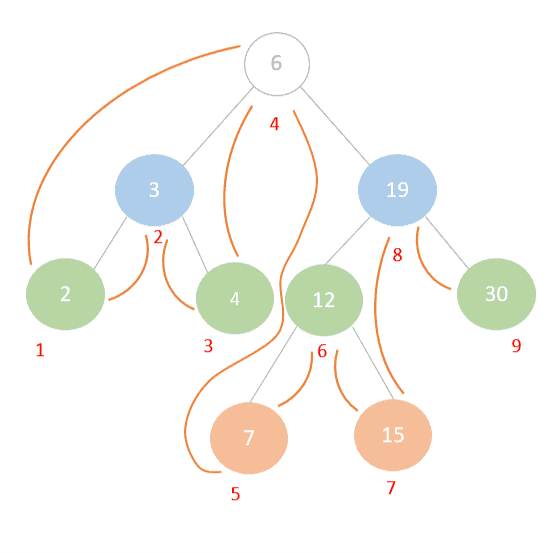
我们从根节点 6 开始:
- 它有左子节点
3,继续往左找到最左节点2,没有左子节点了,可以访问它。 - 回到
3,访问它。 - 接着访问
4。 - 回到根节点
6,访问它。 - 接着遍历右子树,依次访问
7、12、15、19、30。
最终访问顺序如下图红色数字所示:
✅ 中序遍历最常用的应用是按升序输出 BST 中的元素。
如果你希望按降序输出,可以将遍历顺序反过来,即从右子树开始,这称为 逆中序遍历(Reverse In-order Traversal)。
4. 后序遍历(Post-order Traversal,LRN)
后序遍历的顺序是:左子树 ➝ 右子树 ➝ 当前节点,简称 LRN(Left-Right-Node)。
递归执行步骤如下:
- 遍历左子树
- 遍历右子树
- 访问当前节点
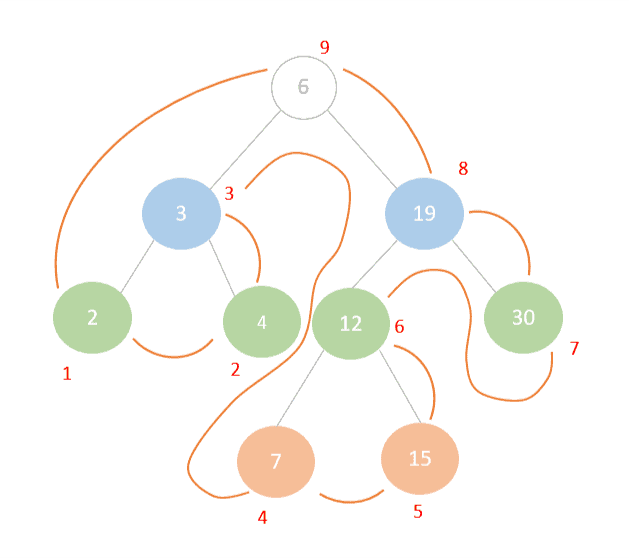
我们依旧以节点 6 为起点,递归遍历其左子树:
2 ➝ 4 ➝ 3(访问顺序为:左 ➝ 右 ➝ 根)- 接着处理右子树:
7 ➝ 15 ➝ 12 ➝ 30 ➝ 19 - 最后访问根节点
6
访问顺序如下图所示:
✅ 后序遍历在某些场景非常实用,比如手动内存管理语言(如 C/C++)中释放树结构的节点时,必须先释放子节点,再释放父节点,否则会出现悬空指针(dangling pointer)问题。
✅ 后序遍历还用于表达式树的后缀表达式(Reverse Polish Notation, RPN)构造。
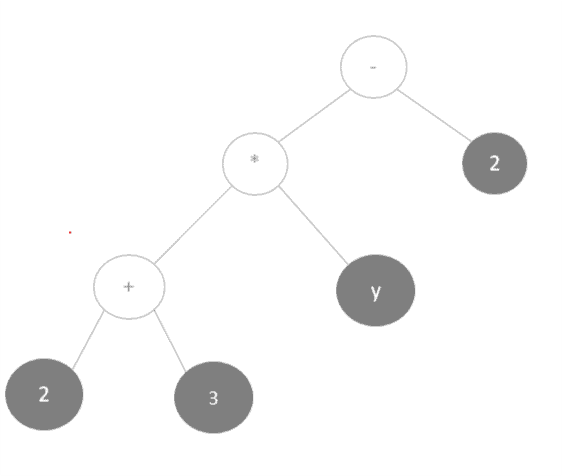
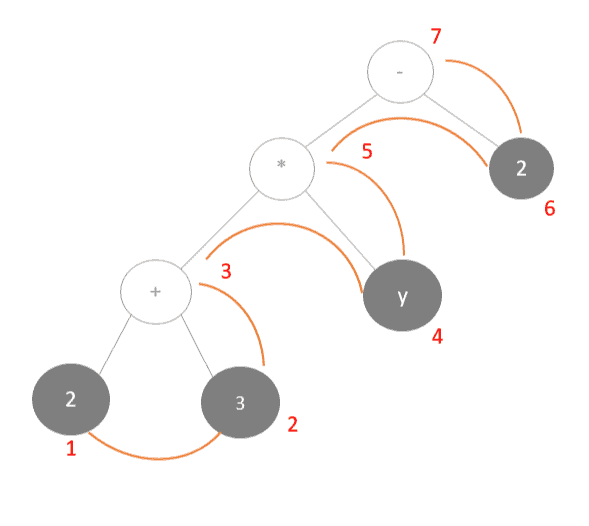
例如,表达式 (2 + 3) * y - 2 可以用后缀表达式表示为 2 3 + y * 2 -。
这种方式无需括号即可表达运算优先级,适合计算机计算。
我们可以通过对表达式树进行后序遍历得到后缀表达式:
表达式树结构如下:
后缀表达式结果如下:
5. 前序遍历(Pre-order Traversal,NLR)
前序遍历的顺序是:当前节点 ➝ 左子树 ➝ 右子树,简称 NLR(Node-Left-Right)。
递归执行步骤如下:
- 访问当前节点
- 遍历左子树
- 遍历右子树
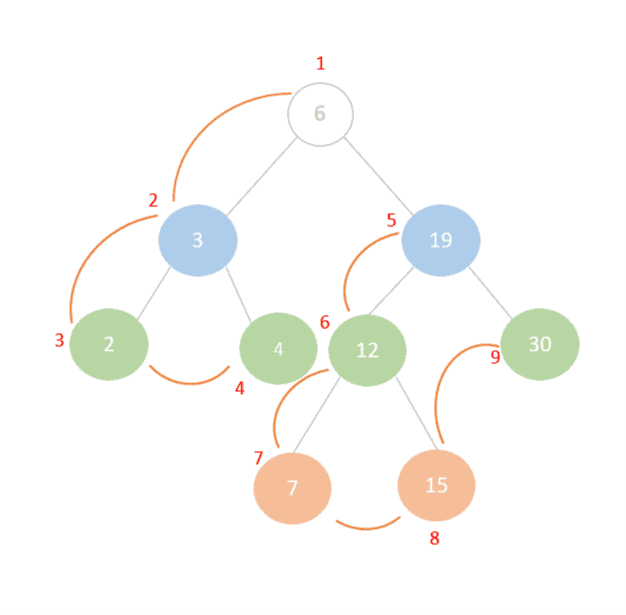
我们从根节点 6 开始:
- 访问
6,接着访问左子树根节点3,再访问2、4 - 回到
3,左子树已遍历完毕,继续右子树 - 回到
6,继续访问右子树,依次访问19、7、12、15、30
访问顺序如下图所示:
✅ 前序遍历在搜索 BST 中的节点时非常有用。
我们可以根据当前节点值决定是往左还是右子树搜索。
✅ 数据库中的 B-树索引在搜索时也常用前序遍历。
✅ 前序遍历还可以用于拓扑排序(Topological Sorting)。
如果一个节点是其子节点的前提条件(依赖项),那么前序遍历可以先输出依赖项,再输出依赖它的节点。
例如 Linux 中的 makefile 工具就利用了这种思想来处理依赖关系。
6. 总结
本篇我们详细介绍了三种深度优先遍历方式及其典型应用场景:
| 遍历方式 | 顺序 | 典型用途 |
|---|---|---|
| 中序遍历 | LNR | BST 升序输出、逆中序降序输出 |
| 后序遍历 | LRN | 手动内存释放、后缀表达式生成 |
| 前序遍历 | NLR | BST 搜索、B-树索引、拓扑排序 |
虽然我们以二叉树为例进行讲解,但这些思想同样适用于图结构。如果你已经理解了这些遍历逻辑,下一步可以尝试自己实现这些遍历算法。
🔗 如果你感兴趣,可以进一步阅读:Java 中如何实现这些遍历方式