1. Overview
In this tutorial, we’ll discuss how diffusion models work. First, we’ll introduce diffusion models and present their theoretical background. Then, we’ll discuss their training and sampling pipeline and present some of their applications.
2. Introduction to Diffusion Models
Generative AI has revolutionized numerous aspects of our everyday lives by enabling machines to generate realistic synthetic data that closely resemble human-generated content. Diffusion models are a new class of state-of-the-art generative models that can generate diverse and high-quality images. Large technological companies like OpenAI, Nvidia, and Google have already managed to train large-scale diffusion models with amazing capabilities.
Examples of architecture that are based on diffusion models are Imagen, DALLE-2, and GLIDE.
In this article, we’ll introduce the basic principles of these models. There are already numerous variations of diffusion-based architectures. We’ll focus on the most famous architecture, the Denoising Diffusion Probabilistic Models (DDPM), presented initially by Sohl-Dickstein et al. and then proposed by Ho et al. 2020.
3. Theoretical Background
Let’s start by presenting the basic ideas behind the concept of diffusion models. In general, diffusion models take as input an image  and gradually add Gaussian noise to it through a series of
and gradually add Gaussian noise to it through a series of  steps. This procedure is called a forward process. It is necessary in order to generate the targets of the learning task, which is the noisy image after applying noise for
steps. This procedure is called a forward process. It is necessary in order to generate the targets of the learning task, which is the noisy image after applying noise for  steps.
steps.
The next step is to train a neural network to learn in order to recover the original image from a corrupted one by reversing the noise process. If we achieve it with a relatively good performance, we can then use the model to generate new data, taking us input pure noise. This process is called the reverse process. In the image below, we can see how the forward and reverse processes work in an example image depicting a cat. We observe that after some steps, we cannot distinguish the cat and we end up with pure noise:

The motivation behind the idea of diffusion models lies in the principle of simulating a diffusion process related to heat dissipation or spreading of information over time from physics.
4. Training Diffusion Models
The process of training a diffusion model typically involves optimizing a set of parameters to remove the noise from a corrupted image and output the real one. To achieve this, a U-Net architecture is usually employed that was initially proposed for the task of semantic segmentation. Later, this symmetrical architecture showed exciting performance in learning to output the added noise to an input image.
Specifically, a U-Net is a symmetrical architecture where the input and the output have the same spatial size. It consists of skip connections between consecutive encoder and decoder blocks. Specifically, the input image is downsampled and upsampled until it reaches its initial size.
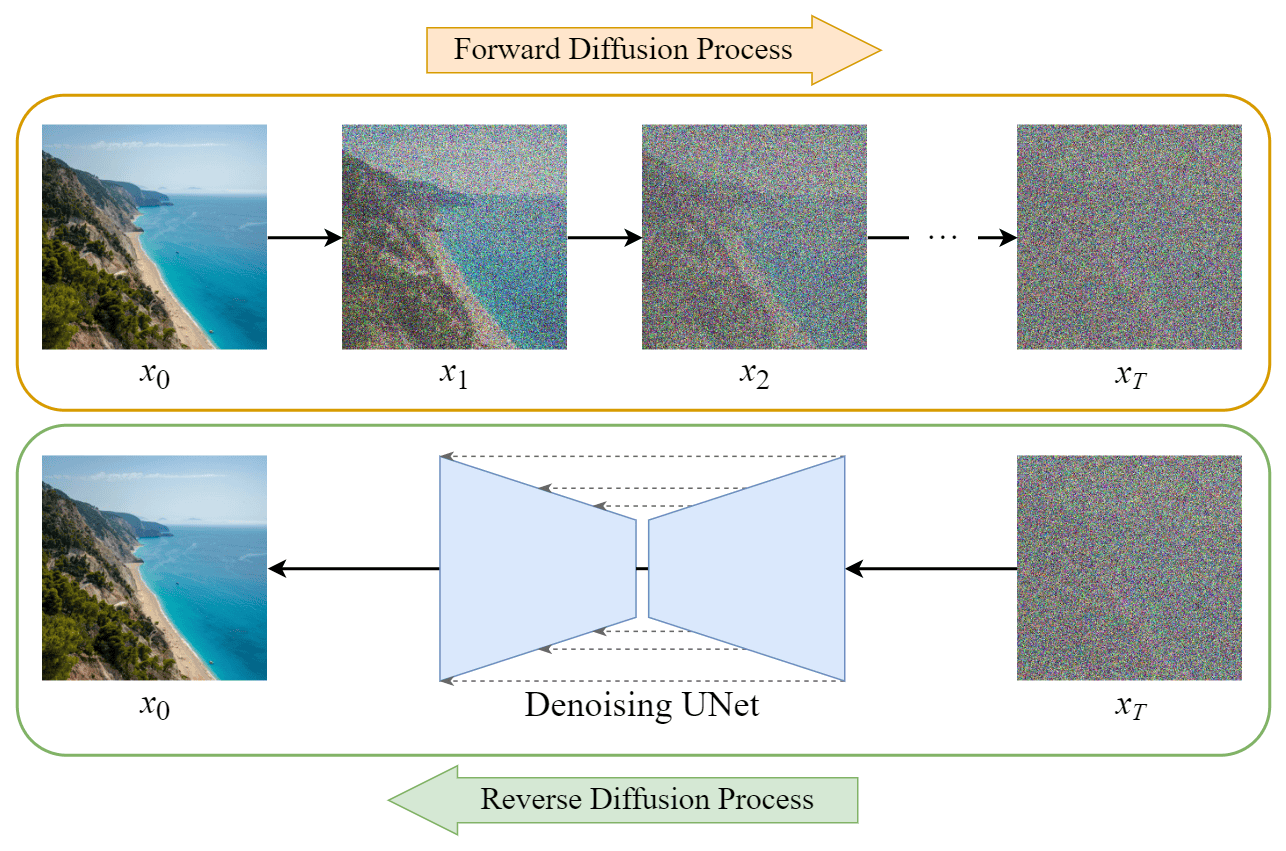
5. Sampling from Diffusion Models
Once the model has been successfully trained to denoise corrupted images, we are ready to use the diffusion mode to generate synthetic samples. Sampling from a diffusion model involved running the aforementioned diffusion process in reverse. Specifically, we start with a fully noisy image and iteratively remove noise for some timesteps until we end up with a realistic synthetic image. An important parameter in the sampling process is the temperature parameter that controls the trade-off between the quality and the diversity of the generated samples.
Below, we can see some synthetic images generated by the well-known Midjourney, which is based on diffusion models. It is important to note that the model generated these images without having seen any of these people depicted in the images:

6. Applications
Now that the internal mechanism of diffusion models is more clear let’s talk a bit about the numerous applications of this new technology.
6.1. Image Generation and Denoising
**It is easily understood that the most obvious applications of diffusion models are image generation and denoising.**These models are amazing at capturing fine-grained details and generating visually appealing results. As a result, they enable content creators to create almost anything they want. In parallel, diffusion models can remove noise from images and preserve important details, enabling us to improve the quality of old, low-resolution images.
6.2. Drug Discovery
An additional application of diffusion models is in drug discovery, where they are used more and more in molecular design. Specifically, they have shown amazing capabilities in generating novel molecular structures with desired properties. As a result, the drug discovery process improves by identifying promising candidates for further experimental validation.
6.3. Generative Modeling for Reinforcement Learning
Finally, diffusion models are very useful in reinforcement learning where they can produce realistic samples of environment states or action trajectories. We can then use these samples for policy learning, exploration, and model-based reinforcement learning algorithms.
7. Conclusion
In this article, we introduced diffusion models. We started with an overview of their theoretical background and then discussed the training and sampling pipeline. Finally, we presented some of their numerous applications.