1. Introduction
In this tutorial, we’ll learn an essential natural language processing task called named entity recognition or NER.
2. NER
NER is a sequence-labeling task in natural language processing. Here, we get an input sequence  , and our task is to label each input word
, and our task is to label each input word  with a label
with a label  that belongs to a defined set of
that belongs to a defined set of  entities.
entities.
We use NER to extract critical information, such as identifying key characters in a novel or essential locations in an itinerary.
2.1. Example
Let’s understand NER through an example. Let’s say we have this sentence to tag:
India born Sundar Pichai is the CEO of Google and its parent company, Alphabet, as of May 6, 2024.
We aim to label each word to one of the entities in the set E={LOC, PER, ORG, TIME, OTH}. Here, LOC means location, PER means Person, ORG means organization, and OTH means others (any word that is not a defined entity):
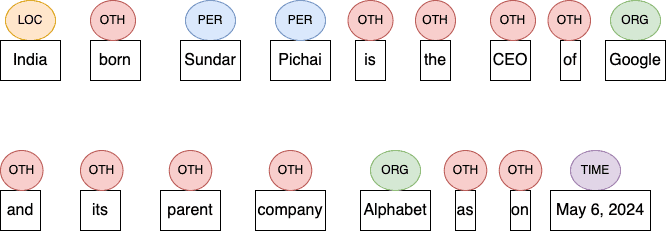
Later, we can use these labels for text classification, sentiment analysis, or other tasks.
3. Types of NER
In this section, we look at various types of NR systems.
3.1. Rule-Based NER
Rule-based NER systems work on handcrafted linguistic rules and the application of regular expressions. For instance, we could rule that all proper nouns following abbreviations (Dr., Mr., Col.) should be considered persons ( ).
).
Rule-based NER is easier to understand and implement, but it requires a lot of human intervention to input, monitor, and tweak the rules. Further, it is challenging to incorporate textual variations outside the rule set. So, we need to devise scalable and robust rules.
3.2. NER Based on Machine Learning
Another class of NER is probability-based machine learning systems. These systems are trained on human-annotated input samples. Here, each sample contains an input sentence and entity labels for each word in the sentence.
These systems use probabilistic models trained on textual patterns and relationships to predict named entities in new text data. An interesting subclass of statistics-based NER is the hidden Markov model or hmm.
A hmm sequence labeler marks each token in a text with tags that indicate the presence (or absence) of target-named entities. Internally, it takes a sequence of units (words, letters, morphemes, sentences, whatever) and computes a probability distribution over possible sequences of labels. Then, it chooses the label sequence that has the maximum probability.
3.3. Neural NER
Neural NER systems use multilayer neural networks to predict named entities. Two major neural network architectures are prominent in the NER domain: recurrent and transformer networks.
Recurrent Neural Networks (RNNs) have internal memory that captures sequential information for the sequence. They work well for sequential data with medium context, such as text. This family of architectures includes long short-term memory (LSTM) networks.
Transformer architectures improve LSTMs on two counts. First, they capture long-term dependency in the text by giving selective importance to each word based on the context. Second, we can process all input words of an input sample in parallel instead of sequential. Transformers are context-sensitive and can apply selective context-dependent attention to different parts of an input.
3.4. Comparison
Each class of NER has its strengths and weaknesses:
Property
Rule-based NER
ML-based NER
Neural NER
Foundation
Based on static rule set and pattern matching by regular expressions
Based on probabilistic machine learning models
Based on multi-layer neural networks
Accuracy
Low
Higher
Highest
Computational Complexity
Low
High
Highest
Difficulty
Easy
Difficult
Most difficult of the lot
Adoption Rate
Low
High
Highest
Rule-based systems serve as a baseline or starting point. Almost all live production systems are neural-based nowadays.
5. NER Tag Encoding
There are several variations of NER tag encodings.
5.1. BIO Tagging
We generally use BIO encoding to define our NER tags:
- B stands for the beginning of an entity
- I stands for “inside” (words in an entity other than the starting word)
- O stands for “outside” (words not included in an entity)
So, each entity of interest has a starting and ending point. For example, John Bernand Shaw starts with the word John, continues to Bernard, and ends with Shaw.
In BIO encoding, we tag the starting point with the prefix B and append an _ followed by an entity tag. After that, for all words following the starting point till the end, we tag them with the prefix I and append an _ followed by an entity tag. Words not in an entity have O as their only tag. For instance, if we’re interested in identifying persons and locations, we could have a NER result such as this:
Sachin (B_PER) Ramesh (I_PER) Tendulkar (I_PER) is (O) a (O) great (O) batsman (O) from (O) India (B_LOC).
Since we’re not interested in entities such as attributes, outstanding is marked as O.
5.2. BIEO
This scheme is similar to the BIO model but with one addition. It has a new tag type, E, for marking the ending word of an entity.
Now, for the same sentence as before, we have this BIEO tagging:
Sachin (B_PER) Ramesh (I_PER) Tendulkar (E_PER) is (O) a (O) great (O) batsman (O) from (O) India (B_LOC).
5.3. BIESO
This scheme differs from BIEO in one thing. It has another tag type, S, that marks single-word entities. So, we have this BIESO tagging for our example sentence:
Sachin (B_PER) Ramesh (I_PER) Tendulkar (E_PER) is (O) a (O) great (O) batsman (O) from (O) India (S_LOC).
The only difference is that the tag for India starts with S instead of B.
5.4. Summary
These schemes are similar but have some differences:
Property
BIO
BIEO
BIESO
Foundation
The tag of the first word of each multi-word entity is prefixed with B, and all the following words are in the entity with I. Words outside of an entity are tagged as O.
Same as BIO, except for the last word of an entity being prefixed with I.
It’s the same as BIEO, but a single-word entity is tagged with S.
Number of Tags
3
4
5
Adoption Rate
Highest
High
Low
6. Applications
6.1. AI Assistants and Chatbots
AI assistants, chatbots, or dialog managers such as ChatGPT (OpenAI) and Bard (Google) use NER models to understand the semantics of user queries. This helps them comprehend the context of the query and deliver accurate and human-like responses.
6.2. Customer Support
For any business, customer support services increase operational costs without any significant increase in revenue. So, companies are increasingly replacing manual labor with AI-powered solutions.
AI-based customer support systems use an ensemble of NER models to categorize feedback and complaints based on product names. As a result, they respond promptly and efficiently to customer queries.
6.3. Information Mining in Niche Domains
For niche sectors such as bioinformatics, finance, and forensics, NER is crucial in extracting pertinent information from various data sources such as crime reports, social media posts, and financial statements**.**
Using NER models, analysts can analyze profitability, perform risk assessments, and monitor trends with higher accuracy and lower turnaround time.
6.4. Search Engines
Companies in this business (Google, Microsoft, Mozilla, etc.) use recommendation engines based on NER to analyze user data, which includes search histories, web preferences, and engagement time. These companies find patterns from critical entities in this data to create personalized recommendations. For example, figuring out the location from recent query history allows them to show advertisements for the location in the queries.
7. Advantages and Disadvantages
NER offers several advantages, but it also poses several challenges:
Advantages
Disadvantages
NER helps companies reduce manual mistakes and biases
It isn’t easy to analyze lexical ambiguities, semantics, and language set intricacies that come with NER.
NER promotes cost-saving and boosts employee productivity by increasing their bandwidth to perform more critical tasks.
Multilingual NER system requires additional processing for out-of-vocabulary words, spelling variations, and polysemous words.
NER can mine customer purchasing patterns, and this enables the marketing team to push targeted and customized offers to each customer
Significant losses exist in a pipelined speech recognition system solution coupled with NER.
NER system requires a massive volume of well-curated training data samples, and this incurs huge cost
8. Conclusion
In this article, we explain the name entity recognition (NER). NER is a sequence labeling problem in which we tag all entities (persons, locations, companies, time, etc.) of interest in a given input text sequence. After completing NER, we can use tags in further processing and decision-making, such as analyzing emerging trends in product usage.