1. 简介
Dijkstra 算法用于在带权图中查找从起始节点到目标节点的最短路径。该算法最初设计用于查找两个给定节点之间的最短路径,但现在更常用于计算从源节点到图中所有其他节点的最短路径,生成一棵最短路径树。
在本文中,我们将学习 Dijkstra 算法的基本概念,理解其工作原理,并在最后分析其时间复杂度,比较不同实现方式的性能差异。
2. 算法概述
Dijkstra 算法由荷兰计算机科学家 Edsger Dijkstra 于 1959 年发表,可用于带权图中查找最短路径。算法通过构建一个包含最小距离的节点集合,从单一源节点出发,逐步扩展最短路径树。
2.1 算法前提条件
使用 Dijkstra 算法时需要注意以下几点:
✅ 仅适用于连通图
✅ 图中不能包含负权边
✅ 仅提供最短路径的值或代价,不提供具体路径
✅ 适用于有向图和无向图
2.2 核心思想
Dijkstra 算法本质上是一种基于优先队列(Priority Queue)的广度优先搜索(BFS)。与普通 BFS 不同的是,它不是使用先进先出的队列,而是使用优先队列,每个节点的优先级是其从源节点到达该节点的代价。
算法涉及以下关键结构:
dist[]:记录从源节点到每个节点的最短距离,初始值为无穷大,源节点为 0Q:优先队列,存放所有节点S:已访问节点的集合
算法步骤如下:
- 从优先队列中取出当前距离最小的节点
v - 将
v加入已访问集合S - 遍历
v的所有邻接节点u,尝试更新dist[u]- 如果
dist[v] + weight(v, u) < dist[u],则更新dist[u]
- 如果
- 重复上述步骤,直到队列
Q为空
2.3 示例演示
以下是一个无向图的示例,我们以节点 e 为起点,计算其到其他所有节点的最短路径。
初始状态:
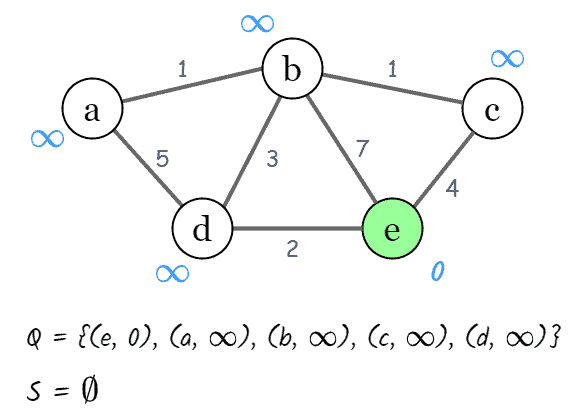
dist[e] = 0,其余节点为 ∞- 从优先队列中取出距离最小的节点
e,更新其邻接节点b,c,d的距离 - 更新后:
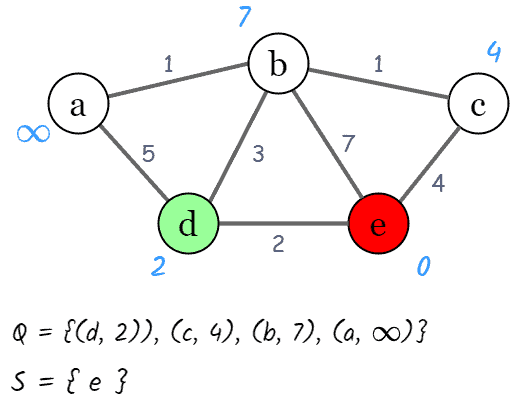
继续从优先队列中取出当前最小距离的节点,重复更新操作,直到队列为空:
最终结果如下:
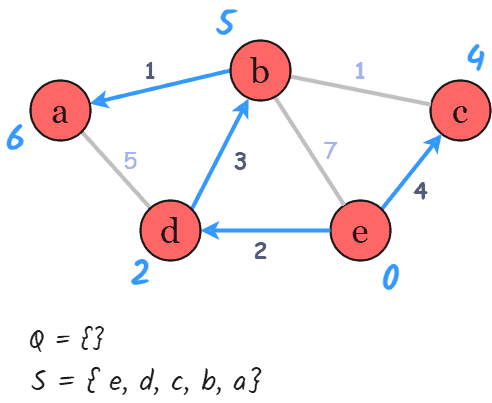
2.4 伪代码
algorithm Dijkstra(G, source):
// 初始化
for v in V
dist[v] = infinity
dist[source] = 0
for v in V:
add v to Q
S = empty set
// 主循环
while Q is not empty:
v = 从 Q 中取出 dist[v] 最小的节点
remove v from Q
add v to S
for 每个邻接节点 u of v:
if u in S:
continue
alt = dist[v] + weight(v, u)
if alt < dist[u]:
dist[u] = alt
更新 Q 中的 dist[u]
return dist
3. 不同实现方式及其时间复杂度分析
Dijkstra 算法的性能取决于图的表示方式和优先队列的实现方式。以下是三种常见实现方式及其时间复杂度对比。
3.1 实现方式一:邻接矩阵 + 无序列表优先队列
适用场景:
- 图用邻接矩阵表示
- 优先队列用无序列表实现
时间复杂度分析:
- 初始化队列:O(|V|)
- 每次从队列中取出最小元素:O(|V|),共 O(|V|) 次
- 更新邻接点:每个节点最多遍历 O(|V|) 次
✅ 总时间复杂度为 O(|V|²)
⚠️ 适合节点数较少的稠密图,不适用于大规模稀疏图。
3.2 实现方式二:邻接表 + 二叉堆优先队列
适用场景:
- 图用邻接表表示
- 优先队列用二叉堆实现
时间复杂度分析:
- 初始化队列:O(|V|)
- 提取最小元素(extract-min):O(log|V|),共 O(|V|) 次
- 更新邻接点:共 O(|E|) 次,每次更新堆为 O(log|V|)
✅ 总时间复杂度为 O((|V| + |E|) * log|V|) = O(|E| * log|V|)
⚠️ 适用于稀疏图,性能优于邻接矩阵实现。
3.3 实现方式三:邻接表 + 斐波那契堆优先队列
适用场景:
- 图用邻接表表示
- 优先队列用斐波那契堆实现
斐波那契堆优势:
- 插入元素:O(1)
- 提取最小元素:O(log|V|)
- 减少优先级:O(1)(摊还时间)
时间复杂度分析:
- 提取最小元素:O(|V| * log|V|)
- 更新邻接点:O(|E|) 次,每次 O(1)
✅ 总时间复杂度为 O(|V| + |E| * log|V|)
⚠️ 理论最优解,但实现复杂度高,实际应用较少。
4. 时间复杂度对比总结
| 实现方式 | 数据结构 | 时间复杂度 | 适用场景 |
|---|---|---|---|
| 邻接矩阵 + 无序列表 | Matrix + List | O( | V |
| 邻接表 + 二叉堆 | List + Binary Heap | O( | E |
| 邻接表 + 斐波那契堆 | List + Fibonacci Heap | O( | V |
✅ 最优实现为斐波那契堆,但实际中二叉堆更为常见
⚠️ 图越稠密,邻接矩阵的优势越不明显
✅ 稀疏图推荐使用邻接表+二叉堆
5. 总结
本文详细介绍了 Dijkstra 算法的基本原理、实现方式及其时间复杂度分析。Dijkstra 是图中最经典的最短路径算法之一,适用于无负权边的图结构。
我们通过一个具体示例演示了算法的执行过程,并通过三种不同实现方式比较了其性能差异。在实际开发中,应根据图的密度和性能需求选择合适的实现方式:
- 稠密图 → 邻接矩阵 + 无序列表
- 稀疏图 → 邻接表 + 二叉堆
- 理论最优 → 邻接表 + 斐波那契堆(不推荐用于生产环境)
如果你对 Java 实现感兴趣,可以参考:Dijkstra 最短路径 Java 实现