1. 概述
大多数 NLP 教程、课程和书籍都会讲解如何将单词转换为向量。
但在实际项目中,我们通常面对的是更复杂的文本结构,比如句子、段落甚至整篇文档。这些结构也需要向量化表示,才能被机器学习模型处理。
本文将介绍将文本序列转换为向量的几种主流方法。阅读本文前,建议你熟悉常见的深度学习技术,比如 RNN、CNN 和 Transformer。
2. 单词向量聚合
如果我们已经有了文本中每个词的向量表示,那么一个很自然的想法是:将这些词向量聚合为一个代表整个文本的向量。
这是一种非常实用的基线方法,很多从业者都会优先考虑,特别是当你已经拥有词向量或可以快速获取时。
常见的聚合方式包括:
- ✅ 平均(Averaging)
- ✅ 最大池化(Max-Pooling)
下面是一个平均词向量的例子:
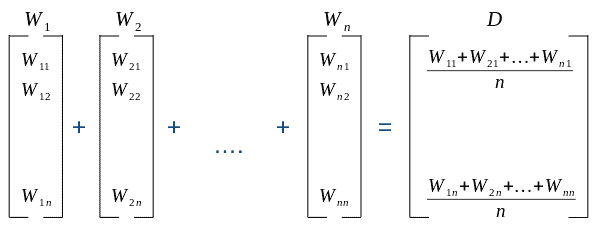
3. 主题建模(Topic Modeling)
主题建模是一种更“高级”的方法:通过训练得到一个向量,其中每个维度代表一个主题。
举个例子:
- 向量
[1.0, 0.6, 0.05]可能代表“恐龙”、“游乐园”、“灭绝”三个主题 - “侏罗纪公园”这部电影就非常适合用这个向量表示
- 而关于“白垩纪-第三纪灭绝”的文章可能更适合
[0.8, 0.0, 1.0]
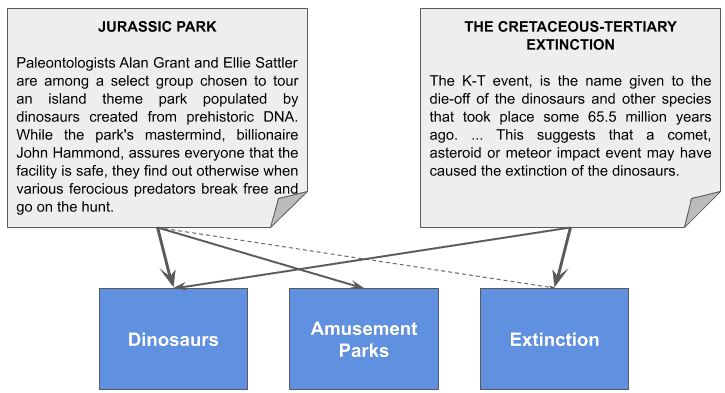
⚠️ 注意:实际训练中发现的主题是隐式的,我们并不知道它们具体代表什么,只能通过分析高频词来推测。
4. 循环神经网络(RNN)
如果你已经掌握了词向量,RNN 是另一个很自然的选择。
这类模型通常由编码器(Encoder)和解码器(Decoder)组成。编码器会逐步读入文本序列,并在最后输出一个状态向量作为整个序列的表示。
例如,下图展示了一个 RNN 编码器的结构:
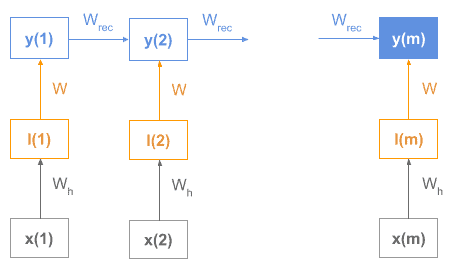
每个词向量作为输入传入 RNN,最终的隐藏状态 y(m) 就是整个序列的向量表示。
✅ 优点:能捕捉序列顺序信息
❌ 缺点:长序列容易遗忘,训练成本高
5. 词袋模型(Bag of Words, BOW)
词袋模型是一种经典方法:将文本表示为一个向量,每个维度对应一个词汇表中的词,值表示该词在文本中的权重。
举个例子:
文本:
- John likes to watch movies. Mary likes movies too.
- Mary also likes to watch football games.
构建词汇表:
V = {John, likes, watch, movies, Mary, too, also, football, games}
对应的词袋向量为:
[1, 2, 1, 2, 1, 1, 0, 0, 0][0, 1, 1, 0, 1, 0, 1, 1, 1]
⚠️ 缺点:忽略词序和语法结构
5.1 词袋 + N-gram
为了缓解词序丢失的问题,可以使用 N-gram 方法,即考虑词的组合顺序。
例如:
- 1-gram(单个词)
- 2-gram(两个词的组合)
✅ 优点:保留部分语序信息
❌ 缺点:维度爆炸,计算成本高
6. BOW 的权重策略
有了词频统计之后,我们还需要决定如何给每个词赋权重。
6.1 是否存在策略(Existence)
简单判断词是否出现在文本中,值为 1 或 0:
- 文本 1:
[1, 1, 1, 1, 1, 1, 0, 0, 0] - 文本 2:
[0, 1, 1, 0, 1, 0, 1, 1, 1]
⚠️ 缺点:不区分词的重要性
6.2 词频计数策略(Count)
统计每个词在文本中出现的次数:
- 文本 1:
[1, 2, 1, 2, 1, 1, 0, 0, 0] - 文本 2:
[0, 1, 1, 0, 1, 0, 1, 1, 1]
✅ 优点:考虑了词频信息
⚠️ 缺点:长文本容易占优势
6.3 词频归一化策略(Term Frequency)
使用词频的相对比例来表示:
$$ TF(t) = \frac{\text{词 t 出现次数}}{\text{总词数}} $$
文本 1:[0.12, 0.25, 0.12, 0.25, 0.12, 0.12, 0.00, 0.00, 0.00]
文本 2:[0.00, 0.16, 0.16, 0.00, 0.16, 0.00, 0.16, 0.16, 0.16]
✅ 优点:消除文本长度影响
6.4 TF-IDF 策略
TF-IDF 是目前最常用的权重策略之一:
$$ TF-IDF = TF \cdot IDF $$
其中 IDF 的定义为:
$$ IDF(t) = \log_e\frac{\text{总文档数}}{\text{包含词 t 的文档数}} $$
举个例子:
文本 1 的 TF-IDF 向量为:[0.08, 0.00, 0.00, 0.17, 0.00, 0.08, 0.00, 0.00, 0.00]
文本 2 的 TF-IDF 向量为:[0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.11, 0.11, 0.11]
✅ 优点:突出关键词,抑制常见词
❌ 缺点:维度高,计算复杂
7. Doc2Vec
如果你有一整套文档,想找出它们之间的相似性,那么 Doc2Vec 是一个不错的选择。
它类似于 Word2Vec,但增加了一个特殊标记 D 来表示整个文档:
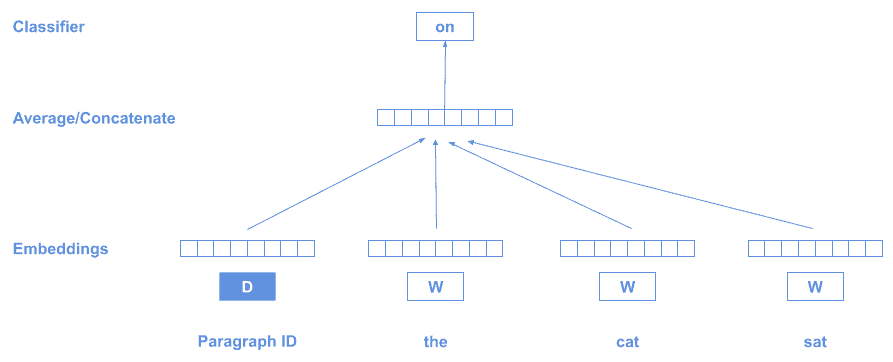
训练时使用“分布假设”:在相同上下文中出现的词具有相似含义。
每段文本会生成一个不同的 D 向量,训练完成后,我们就能得到每个文档的向量表示。
也可以反过来训练:通过文档向量预测上下文词。
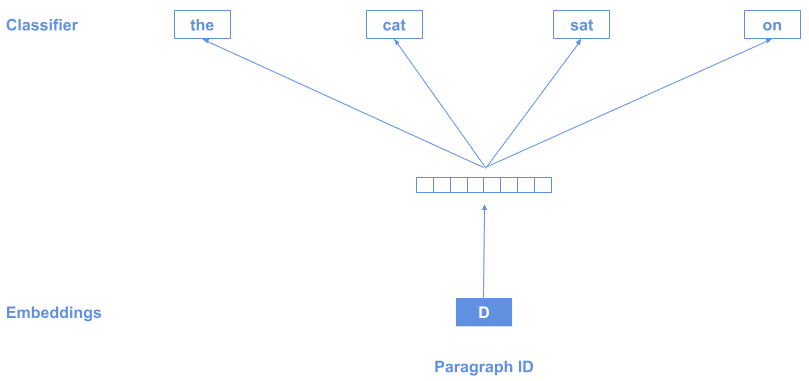
✅ 优点:适用于文档级别表示
❌ 缺点:训练成本高,调参复杂
8. BERT
目前最流行的文本表示模型之一是 BERT(Bidirectional Encoder Representations from Transformers)。
BERT 的特点在于:
- ✅ 同时输出整个序列的向量和每个 token 的向量
- ✅ 使用
[CLS]标记作为整个序列的表示
如下图所示:
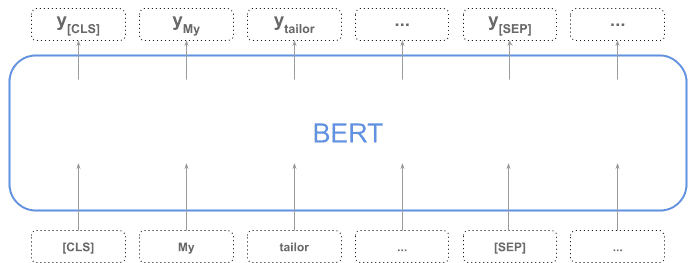
你也可以通过聚合 token 向量(如平均、池化)来获得整个序列的表示。
9. Sentence-BERT(SBERT)
如果你想高效地比较句子之间的相似性,Sentence-BERT(SBERT) 是首选方案。
传统 BERT 在比较句子相似性时效率极低,比如比较 10,000 个句子,需要计算 5,000 万次,非常耗时。
SBERT 使用孪生网络(Siamese Network)或三元组网络(Triplet Network) 训练句子向量,然后通过余弦相似度进行比较。
训练结构如下:
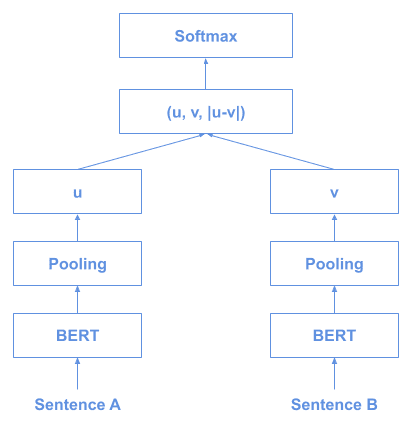
推理结构如下:
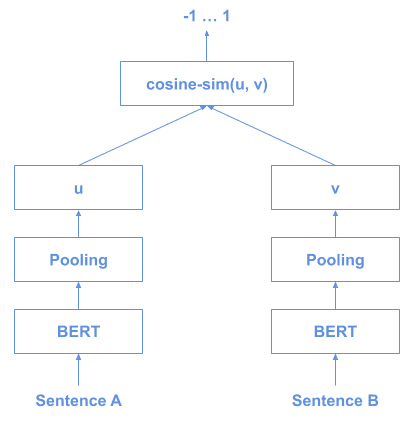
✅ 优点:高效,适合大规模句子相似性比较
❌ 缺点:需要额外训练
10. InferSent
由 Facebook 提出,InferSent 是一种基于监督学习的句子向量表示方法,在多个任务中泛化能力很强。
其核心思想是在 斯坦福自然语言推理数据集(SNLI) 上训练各种编码器结构,如 GRU、LSTM 和 BiLSTM。
训练结构如下:
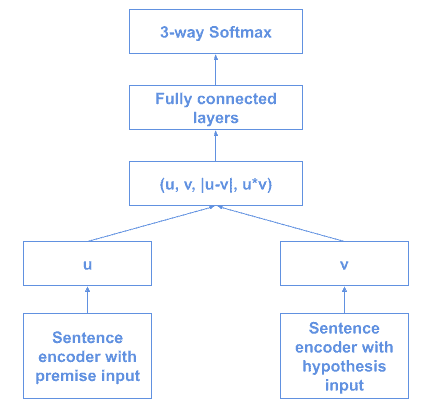
早期版本使用 GloVe 词向量,后来升级为 fastText。
✅ 优点:监督训练,语义表示强
❌ 缺点:依赖标注数据
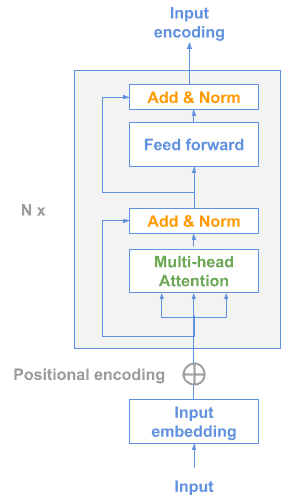
11. Universal Sentence Encoder(USE)
由 Google 推出,提供两种模型架构供选择:
11.1 Transformer 模型
基于 Transformer 的编码器结构:
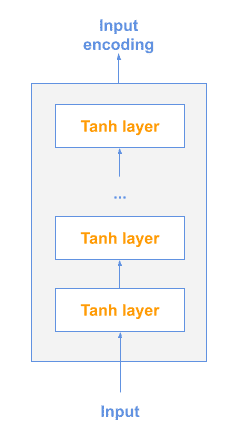
11.2 深度平均网络(DAN)
输入的词和二元组先平均,再通过前馈网络生成句子向量:
✅ 优点:多任务学习,泛化能力强
❌ 缺点:模型较大,推理速度慢
12. 总结
本文介绍了将文本序列转换为向量的多种方法,包括:
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 词向量聚合 | 快速实现 | 简单高效 | 忽略语序 |
| 主题建模 | 高层语义 | 可解释性强 | 主题不明确 |
| RNN | 序列建模 | 捕捉顺序信息 | 长依赖困难 |
| BOW | 传统方法 | 易实现 | 信息丢失严重 |
| TF-IDF | 关键词提取 | 突出关键词 | 维度高 |
| Doc2Vec | 文档表示 | 适用于语义检索 | 训练复杂 |
| BERT | 上下文理解 | 语义强 | 计算资源高 |
| SBERT | 句子相似性 | 高效比对 | 需要训练 |
| InferSent | 监督表示 | 语义清晰 | 依赖标注 |
| USE | 多任务 | 泛化性强 | 模型大 |
选择合适的方法取决于你的具体任务和资源限制。掌握这些技术,是成为一名优秀 NLP 工程师的必经之路。