1. 简介
在本篇教程中,我们将深入讲解 Epsilon-Greedy Q-learning,这是一种经典的强化学习算法。我们会简要介绍一些基础概念,例如时间差分(Temporal Difference)和离策略学习(Off-policy Learning),重点分析探索与利用的权衡问题,以及 Epsilon-Greedy 的动作选择策略。最后还会讨论 Q-learning 的学习参数及其调优方法。
2. Q-learning 算法
Q-learning 是强化学习中一种非常基础且广为应用的算法。它属于 离策略、时间差分控制算法,最早由 Watkins 于 1989 年提出。
在 Q-learning 中,我们维护一个 Q 表(Q-table),用于记录状态(State)与动作(Action)的对应价值。这个表的每个条目  表示在状态 S 下采取动作 A 的预期价值。
表示在状态 S 下采取动作 A 的预期价值。
Q-learning 的更新公式如下:
$$ Q(S_t, A_t) \gets Q(S_t, A_t) + \alpha \left[ R_{t+1} + \gamma \max_{a} Q(S_{t+1}, a) - Q(S_t, A_t) \right] $$
其中:
- $ \alpha $:学习率(Learning Rate)
- $ \gamma $:折扣因子(Discount Factor)
- $ R_{t+1} $:执行动作后获得的即时奖励
- $ \max_{a} Q(S_{t+1}, a) $:下一状态中最大 Q 值
这个公式也被称为 Q 函数(Action-value Function),它帮助我们估算在某个状态下采取某个动作的价值。最终,Q 表将逼近最优动作价值函数 $ Q^* $。
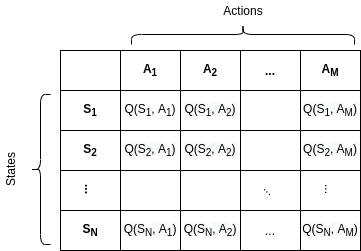
Q 表结构示例
假设我们有 N 个状态和 M 个动作,Q 表的结构大致如下:
举个简单的例子,比如在一个 3×3 的网格中移动的智能体:
- 状态(S):网格中的每个格子
- 动作(A):最多 8 个方向(上下左右 + 斜向)
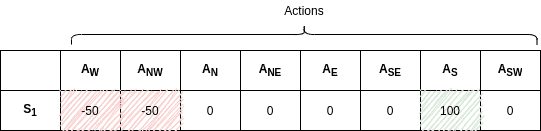
初始状态下,Q 表中所有值都是随机的:
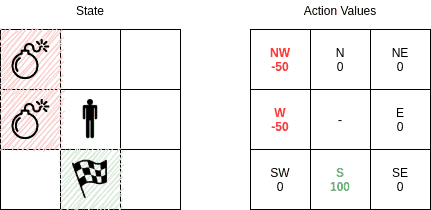
随着训练进行,Q 表逐渐收敛,最终会形成如下结构(假设目标是右下角,有炸弹需要避开):
此时,智能体会根据 Q 表选择动作,避开炸弹,朝目标移动。
3. Q-learning 特性
Q-learning 的几个关键特性如下:
3.1. 无模型强化学习(Model-Free RL)
Q-learning 是一种 无模型算法,即不需要事先知道状态转移概率或奖励函数。智能体通过试错来学习,直接从环境中获得反馈。
✅ 优点:无需建模环境
❌ 缺点:学习效率较低,尤其在状态空间大时
3.2. 时间差分(Temporal Difference)
Q-learning 是 TD 算法的一种,其核心思想是:
- 每一步都更新 Q 值
- 不需要等到一个完整的 episode 结束
这意味着即使在一个 episode 中途,只要执行了一个动作,就可以立即更新对应的 Q 值。
3.3. 离策略学习(Off-Policy Learning)
Q-learning 是一种 离策略算法,它的更新策略与当前策略无关。它总是朝着最优策略(Greedy)逼近,即使当前策略是随机的。
⚠️ 踩坑点:很多初学者误以为 Q-learning 是 On-policy,其实不是。它使用的是目标策略(Greedy)来更新,而当前策略可以是探索性的(如 Epsilon-greedy)。
4. Epsilon-Greedy Q-learning 算法
Epsilon-Greedy 是 Q-learning 中最常用的动作选择策略之一。它的核心思想是:
- 以 $ 1 - \epsilon $ 概率选择当前最优动作(Exploit)
- 以 $ \epsilon $ 概率随机选择动作(Explore)
伪代码
algorithm EpsilonGreedyQLearning():
// 初始化 Q 表
Initialize Q(s,a) arbitrarily, for all s in S, a in A(s), except for Q(terminal, .) <- 0
for each episode:
Initialize state S
while S is not terminal:
// 选择动作
A <- selectAction(Q, S, epsilon)
// 执行动作,获得奖励和新状态
Take action A, observe reward R and next state Z
// 更新 Q 表
q <- max(Q(Z, a))
Q(S, A) <- Q(S, A) + alpha * (R + gamma * q - Q(S, A))
S <- Z
selectAction 函数
algorithm selectAction(Q, S, epsilon):
n <- random number between 0 and 1
if n < epsilon:
A <- random action
else:
A <- argmax(Q(S, a))
return A
5. 动作选择策略
5.1. 探索 vs 利用(Exploration vs Exploitation)
这是强化学习中的核心问题:
- Exploitation(利用):选择已知收益高的动作,获取即时奖励
- Exploration(探索):尝试未知动作,可能发现更高收益的路径
⚠️ 踩坑点:如果只利用,容易陷入局部最优;如果只探索,学习效率太低。
5.2. Epsilon-Greedy 策略
Epsilon-Greedy 是解决探索与利用矛盾的常用方法。它的选择逻辑如下图所示:
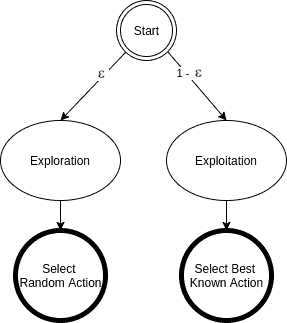
- 以 $ \epsilon $ 概率随机选择动作(探索)
- 以 $ 1 - \epsilon $ 概率选择当前最优动作(利用)
这种方式确保了在有限时间内能尝试所有动作,从而找到全局最优解。
6. Epsilon-Greedy Q-learning 参数
Q-learning 的性能很大程度上取决于参数设置。以下是三个关键参数:
6.1. 学习率 Alpha ( )
)
- 控制更新步长
- $ \alpha \in (0, 1] $
- $ \alpha=0 $:不学习新信息
- $ \alpha=1 $:完全忽略历史经验
✅ 建议:通常设置为 0.1~0.5 之间
6.2. 折扣因子 Gamma ( )
)
- 控制未来奖励的重要性
- $ \gamma \in [0, 1] $
- $ \gamma=0 $:只关注当前奖励
- $ \gamma=1 $:无限期关注未来奖励
✅ 建议:大多数场景设置为 0.9~0.99
6.3. 探索率 Epsilon ( )
)
- 控制探索与利用的平衡
- $ \epsilon \in [0, 1] $
- $ \epsilon=0 $:完全利用已有知识
- $ \epsilon=1 $:完全随机探索
✅ 建议:初期设为 0.1~0.2,随着训练进行逐步降低(Epsilon Decay)
7. 总结
在本篇文章中,我们深入探讨了:
- Q-learning 算法 及其更新机制
- Epsilon-Greedy 策略 在动作选择中的作用
- 探索与利用的平衡 是强化学习的关键
- Alpha、Gamma、Epsilon 三个参数的含义及调优建议
Epsilon-Greedy Q-learning 是一个简单但非常有效的算法,适合入门和实践。在实际项目中,我们还可以结合更复杂的策略(如 Softmax、UCB)来进一步提升性能。