1. 引言
Fibonacci Search 是一种基于 Fibonacci 数列 的比较型搜索算法,与二分查找(Binary Search)类似,它也是一种基于 分治策略(Divide and Conquer) 的搜索方法。
该算法适用于已经 按非降序排序 的数组。在深入理解其内部机制之前,我们先来回顾一下 Fibonacci 数列的基本概念。
2. Fibonacci 数列
Fibonacci 数列是一个递归定义的数列,其任意一项等于前两项之和:
$$ F_n = F_{n-1} + F_{n-2} $$
通常定义初始值为:
$$ F_0 = 0,\quad F_1 = 1 $$
我们来生成一些 Fibonacci 数列的前几项:
$$ \begin{align*} F_0 &= 0 \ F_1 &= 1 \ F_2 &= F_1 + F_0 = 1 \ F_3 &= F_2 + F_1 = 2 \ F_4 &= F_3 + F_2 = 3 \ F_5 &= F_4 + F_3 = 5 \ F_6 &= F_5 + F_4 = 8 \ F_7 &= F_6 + F_5 = 13 \ \end{align*} $$
Fibonacci 数列在信息编码理论中扮演着重要角色,尤其在无线通信和安全编码算法中应用广泛。
3. Fibonacci Search 算法详解
3.1 算法思想
Fibonacci Search 是一种基于 动态规划 的比较型搜索技术。它通过利用 Fibonacci 数列构建搜索路径,从而在排序数组中查找目标值。
与 Binary Search 不同的是,它不使用除法运算,而是通过加减法来缩小搜索范围,因此在某些特定场景下效率更高。
3.2 算法步骤
- 找到一个大于等于数组长度
n的最小 Fibonacci 数F_k。 - 初始化
F_k、F_{k-1}、F_{k-2}和偏移量offset = -1。 - 进入循环,直到
F_k_2 < 0:- 计算当前比较位置
index = min(offset + F_k_2, n - 1) - 比较
arr[index]与key:- 若
arr[index] < key,则在右子数组中继续查找,更新F_k、F_{k-1}、F_{k-2},并设置offset = index - 若
arr[index] > key,则在左子数组中查找,更新相关 Fibonacci 值 - 若相等,则返回
index
- 若
- 计算当前比较位置
- 若循环结束后仍未找到,再比较
arr[offset + 1],若匹配则返回索引,否则返回-1
每次迭代中,搜索范围都会减少约 1/3 或 2/3。
3.3 伪代码实现
algorithm FibonacciSearchAlgorithm(arr, n, key):
F_k_2 <- 0
F_k_1 <- 1
F_k <- F_k_1 + F_k_2
// 找到大于等于 n 的最小 Fibonacci 数
while F_k <= n:
F_k_2 <- F_k_1
F_k_1 <- F_k
F_k <- F_k_1 + F_k_2
offset <- -1
while F_k_2 >= 0:
index <- min(offset + F_k_2, n - 1)
if arr[index] < key:
// 向右子数组查找
F_k <- F_k_1
F_k_1 <- F_k_2
F_k_2 <- F_k - F_k_1
offset <- index
else if arr[index] > key:
// 向左子数组查找
F_k <- F_k_2
F_k_1 <- F_k_1 - F_k_2
F_k_2 <- F_k - F_k_1
else:
return index
// 最后检查一次
if F_k_1 != 0 and arr[offset + 1] == key:
return offset + 1
return -1
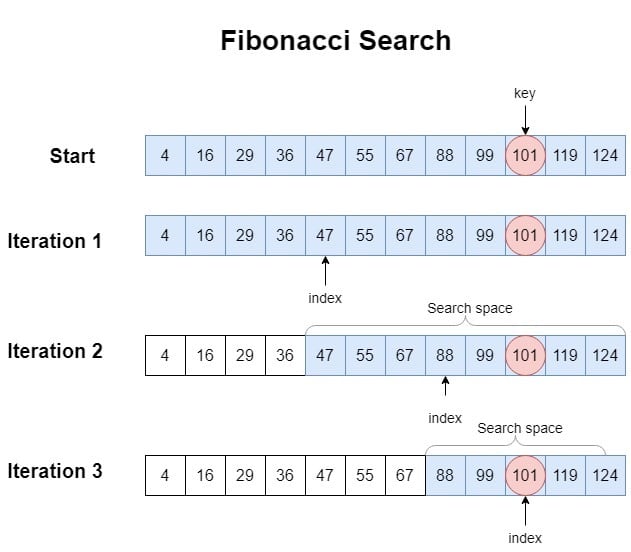
3.4 示例演示
我们以如下有序数组为例进行 Fibonacci Search:
$$ [4, 16, 29, 36, 47, 55, 67, 88, 99, 101, 119, 124] $$
查找目标值 key = 101
迭代过程:
第1次迭代:
n = 12,offset = -1- 找到最小 Fibonacci 数
F_k = 13,对应F_{k-1} = 8,F_{k-2} = 5 index = min(-1 + 5, 11) = 4,arr[4] = 47 < 101- 更新参数,继续向右查找
第2次迭代:
F_k = 8,F_{k-1} = 5,F_{k-2} = 3index = min(4 + 3, 11) = 7,arr[7] = 88 < 101- 继续向右查找
第3次迭代:
F_k = 5,F_{k-1} = 3,F_{k-2} = 2index = min(7 + 2, 11) = 9,arr[9] = 101 == key- 找到目标值,返回
index = 9
整个查找过程如下图所示:
4. 时间与空间复杂度分析
时间复杂度
- 最佳情况:
O(1)—— 当目标值正好是第一个比较的元素 - 最坏情况:
O(log n)—— 每次都在较大的子数组中查找 - 平均情况:
O(log n)—— 每次缩小约 1/3 的搜索空间
空间复杂度
- O(1) —— 只使用了常数级别的额外空间
推导说明
每次缩小搜索空间的比例约为 1/3 或 2/3,因此可以表示为:
$$ T(n) = T\left(\frac{2n}{3}\right) + T\left(\frac{n}{3}\right) + c $$
最终可得:
$$ T(n) = O(\log n) $$
5. 与二分查找的对比
| 特性 | Fibonacci Search | Binary Search |
|---|---|---|
| 比较次数 | 约多 4% | 更少 |
| 操作类型 | 使用 + 和 - |
使用 / 和 *(较重) |
| 缩小比例 | 每次缩小 1/3 或 2/3 | 每次缩小 1/2 |
| 访问次数 | 约多 44% | 更少 |
| 适用场景 | 适合硬件限制较多的系统 | 通用性强 |
✅ 优点:无需除法操作,适合嵌入式或硬件受限环境
❌ 缺点:平均查找次数略多于二分查找
⚠️ 注意:当数组非常大时,Binary Search 的性能更稳定
6. 总结
Fibonacci Search 是一种高效的比较型搜索算法,它利用 Fibonacci 数列的特性,通过加减法而非除法来缩小搜索空间。
虽然其查找次数略多于 Binary Search,但在某些特定场景(如硬件资源受限、不支持除法指令)下,Fibonacci Search 更具优势。
✅ 适用场景:
- 数组已排序
- 不希望使用除法/乘法
- 嵌入式系统、硬件受限环境
✅ 核心优势:
- 使用轻量级运算(加减法)
- 不依赖除法和乘法
- 空间复杂度为
O(1)
📌 一句话总结:Fibonacci Search 是一种在特定条件下优于 Binary Search 的替代方案,尤其适合硬件资源受限的环境。