1. 简介
在本文中,我们将深入讲解 RANSAC(Random Sample Consensus,随机采样一致性) 算法。它是一种经典的鲁棒估计方法,常用于从包含异常值(outliers)的数据中拟合出一个准确的数学模型。RANSAC 的核心思想是通过迭代随机采样,逐步筛选出“内点”(inliers),从而构建一个尽可能排除异常值影响的模型。
2. 为什么需要 RANSAC?
2.1. 异常值的来源与影响
数据集中出现异常值的原因多种多样,比如测量误差、输入错误、设备故障等。有时异常值甚至可能是数据本身的特性。它们的存在会严重影响后续的数据建模与分析。
举个例子来看,假设我们有一组用于信号处理的原始数据:
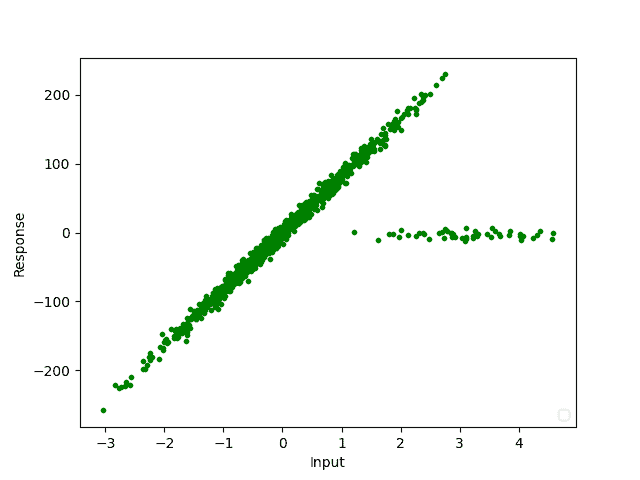
这些异常值在图中肉眼可见,我们用紫色标记出来:
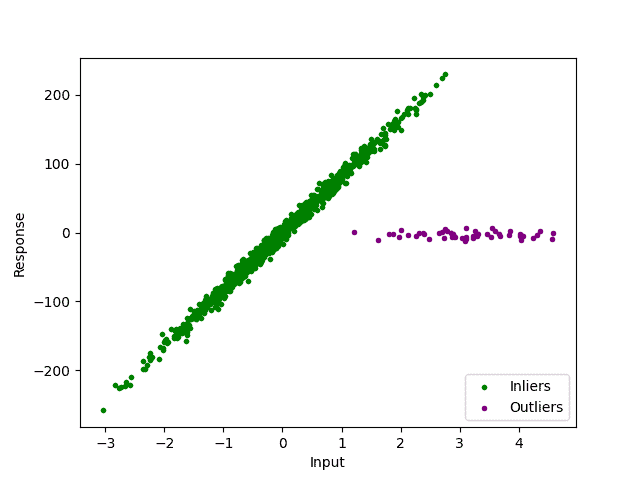
但并不是所有数据都能这么直观地识别异常值,尤其是高维数据。我们需要一种自动、系统化的方式来识别和剔除异常值。
2.2. 异常值对建模的影响
以线性回归为例,如果包含异常值,拟合出的直线会严重偏离真实趋势:
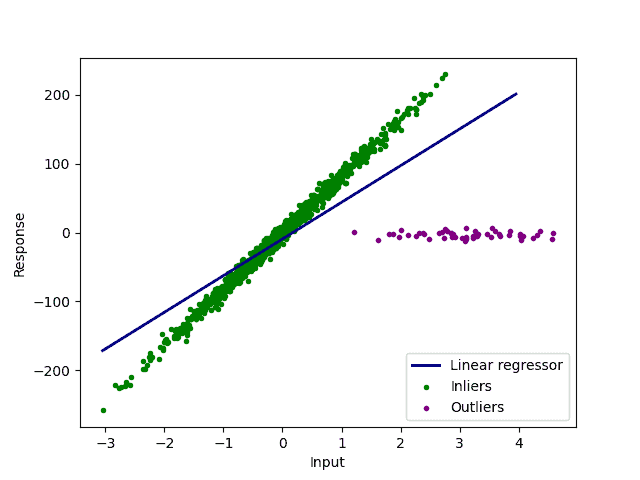
而如果我们只使用内点进行拟合,结果会更合理:
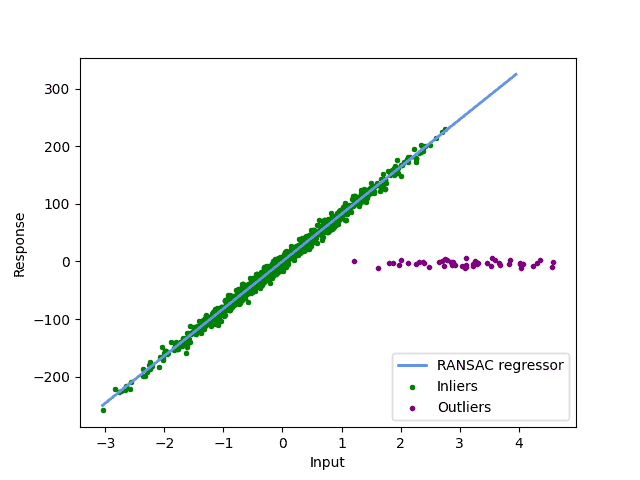
这正是 RANSAC 的目标:自动识别并忽略异常值,从而构建更准确的模型。
3. RANSAC 的实现原理
RANSAC 的核心是通过多次随机采样,寻找一个“最佳拟合模型”。它的基本流程如下:
3.1. 算法流程
下面是 RANSAC 的伪代码实现:
algorithm RANSAC(n, m, data, t, k):
// INPUT
// n = 每次迭代中使用的内点数量
// m = 最大迭代次数
// data = 输入数据集
// t = 内点判定的误差阈值
// k = 判定模型是否有效的最小内点数
// OUTPUT
// bestFit = 最佳拟合模型
i <- 0
bestFit <- null
bestError <- 无穷大
while i < m:
tempInliers <- 从 data 中随机选取 n 个点
tempInliersAdd <- 空列表
tempModel <- 根据 tempInliers 拟合模型
for point in data:
if point 不在 tempInliers 中:
if distance(point, tempModel) < t:
tempInliersAdd.add(point)
if tempInliersAdd.size > k:
newModel <- 根据 tempInliers 和 tempInliersAdd 拟合新模型
if newModel.error < bestError:
bestError <- newModel.error
bestFit <- newModel
return bestFit
算法的关键在于:
- 随机选取初始样本点(tempInliers)
- 拟合初始模型(tempModel)
- 检查所有其他点与模型的偏差是否在阈值 t 以内
- 收集这些点作为候选内点(tempInliersAdd)
- 若候选内点数大于 k,则重新拟合并更新最佳模型
✅ 优点:自动识别异常值,无需人工干预
❌ 缺点:依赖于参数设置,如 t 和 m,且不保证 100% 准确
3.2. 阈值 t 的选择
参数 t 决定了模型与点之间误差的容忍度。如果设置不当,可能会导致误判。
例如,如果 t 设置得太小:
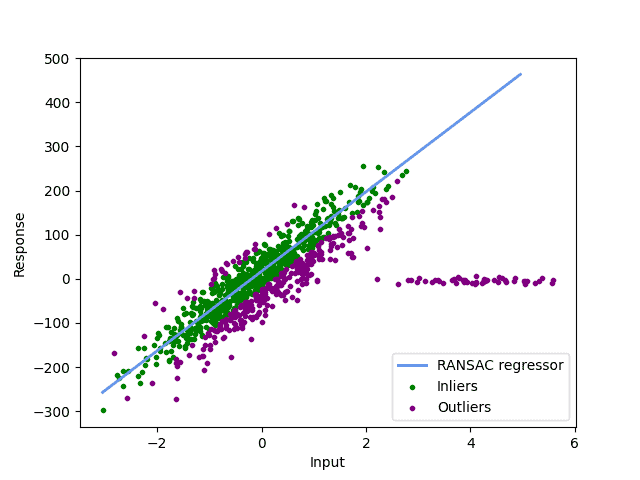
这会导致很多异常值被误判为内点。
更合理的设置如下:
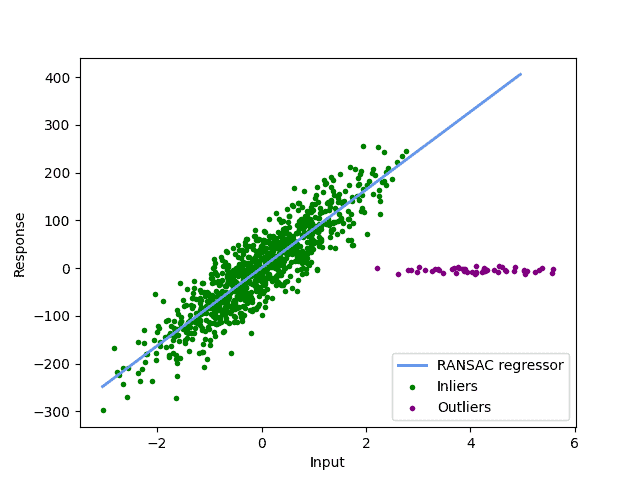
⚠️ 建议:若未指定 t,通常可取数据 y 值的中位数作为默认值。
3.3. 迭代次数 m 的选择
迭代次数越多,越有可能选出一个完全由内点组成的样本集。我们可以通过以下公式估算所需迭代次数:
$$ k = \frac{\log(1-p)}{\log(1-w^n)} $$
其中:
- $ w $:内点比例
- $ n $:每次迭代所需样本点数
- $ p $:至少一次成功采样的概率
例如,若 $ w=0.8 $、$ p=0.99 $、$ n=10 $,则需要约 41 次迭代。
⚠️ 踩坑提醒:迭代次数不是越多越好,应根据实际数据量和内点比例进行合理设置。
4. RANSAC 的优缺点与替代方案
4.1. 优势
- ✅ 对异常值具有鲁棒性
- ✅ 适用于多种模型(如线性回归、平面拟合、图像匹配等)
- ✅ 实现相对简单,适合嵌入式或实时系统
4.2. 局限性
- ❌ 依赖于参数设置(t、m、n、k)
- ❌ 当异常值比例超过 50% 时效果不佳
- ❌ 无法保证全局最优解
4.3. 替代方案
- ✅ SVM(支持向量机):适用于二分类问题,如将数据分为“内点”和“异常值”
- ✅ kNN(K近邻):基于距离判断点是否为异常值
- ✅ DBSCAN:一种基于密度的聚类方法,也可用于异常值检测
5. 总结
本文详细讲解了 RANSAC 算法的原理、实现流程、关键参数设置及其影响。我们还讨论了它在实际应用中的优缺点,并列举了一些替代方案。
RANSAC 是一种简单但非常有效的异常值检测和模型拟合工具,广泛应用于计算机视觉、机器人、信号处理等领域。在使用时要注意参数设置,合理控制迭代次数和误差阈值,以获得最佳效果。