1. Introduction
The field of computer architecture has seen rapid advancements since the inception of computing machines. These developments necessitated a structured framework to classify and understand different architectures.
One such pivotal framework is Flynn’s Taxonomy, proposed by Michael J. Flynn in 1966. This classification helps comprehend how different computer systems handle instructions and data streams, making it an essential tool for students, professionals, and researchers in computer science and engineering.
In this tutorial, we’ll explore Flynn’s Taxonomy, its categories, and their relevance in modern computing.
Before we begin, let’s first understand a little bit of background and history.
2. Background
Michael J. Flynn introduced his taxonomy during a time when computer architectures were diversifying to meet various computational needs. He classified computer systems based on the number of concurrent instruction streams and data streams they can handle.
This classification has four categories: Single Instruction Single Data (SISD), Single Instruction Multiple Data (SIMD), Multiple Instruction Single Data (MISD), and Multiple Instruction Multiple Data (MIMD).
Despite being conceived over half a century ago, Flynn’s Taxonomy remains relevant due to its simplicity and effectiveness in categorizing and comparing different architectures.
3. Classification Criteria
Flynn’s Taxonomy uses two primary criteria for classification: instruction streams and data streams.
- Instruction Streams: refers to the sequence of instructions that the control unit fetches and executes during an instruction cycle. An instruction stream can be single or multiple, affecting how tasks are processed.
- Data Streams: refers to the flow of data that is manipulated by the instructions. Like instruction streams, data streams can also be single or multiple, influencing the system’s data-handling capabilities.
Thus, by combining these two criteria, Flynn’s Taxonomy creates four distinct categories that describe how different systems process instructions and data:
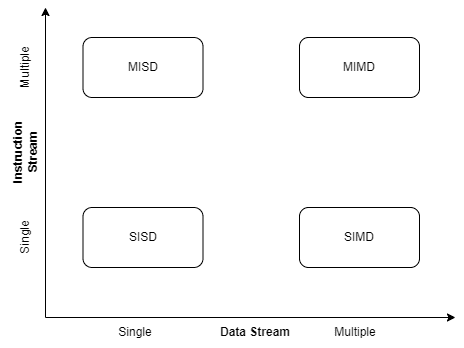
Let’s understand each of these categories in detail.
4. SISD (Single Instruction Single Data)
SISD architectures are conventional single-core computers that process one instruction and one data stream at a time. It represents the structure of a simple computer with a control unit, a memory unit, and a processor unit.
The CPU works with a single data stream sequentially executing instructions one after another. Thus, it may or may not consist of internal parallel processing capability leading to the sequential execution of the instructions. This simplicity makes SISD systems easier to implement and understand.
Traditional uniprocessor systems like the IBM 7090 are prime examples of SISD architectures. These systems are designed to handle tasks sequentially, making them suitable for general-purpose computing.
SISD architectures are ideal for applications that do not require parallel processing, such as basic computing tasks, text processing, and simple calculations. Their straightforward design makes them suitable for scenarios where tasks are executed sequentially without the need for simultaneous data processing.
5. SIMD (Single Instruction Multiple Data)
SIMD architectures execute a single instruction on multiple data streams simultaneously. This is particularly useful for tasks involving large-scale data processing and parallel computation. A single control unit broadcasts the same instruction to multiple processing units, allowing each processing unit to perform the same operation on different pieces of data simultaneously. This parallelism makes SIMD systems highly efficient for vector processing and data-parallel tasks.
Vector processors like the Cray-1 and modern GPUs (Graphics Processing Units) exemplify SIMD architectures. These systems are designed to handle large-scale data processing tasks efficiently, making them suitable for scientific computations and graphics rendering.
SIMD architectures excel in applications that involve repetitive operations on large data sets, such as image processing, scientific simulations, and deep learning. Their ability to process multiple data streams simultaneously makes them ideal for tasks that require high data parallelism.
6. MISD (Multiple Instruction Single Data)
MISD architectures execute multiple instructions on the same data stream. This is a rare and less commonly used architecture. Multiple control units fetch different instructions and all operate on the same data stream. This design allows for redundancy and fault tolerance, making MISD systems suitable for specialized applications where reliability is critical.
While few practical implementations of MISD exist, the concept is theoretically valuable for systems requiring high reliability. Some specialized aerospace systems use this approach to ensure redundancy and fault tolerance.
MISD architectures are typically used in specialized applications that require fault tolerance and redundancy, such as mission-critical systems in aerospace. Their ability to execute multiple instructions on a single data stream makes them ideal for scenarios where high reliability is essential.
7. MIMD (Multiple Instruction Multiple Data)
MIMD architectures execute multiple instructions on multiple data streams concurrently. This architecture supports true parallel processing and is used in most modern multicore processors.
All the processors can execute different instructions and work on separate data simultaneously. Each processor in MIMD runs its own process, generating its own instruction stream. This design allows for high scalability and flexibility, making MIMD systems suitable for a wide range of applications.
Modern multicore processors like Intel Core and AMD Ryzen, as well as distributed computing systems such as clusters and supercomputers, exemplify MIMD architectures. These systems are designed to handle diverse and parallel tasks efficiently.
MIMD architectures are used in applications that benefit from parallel processing, including web servers, databases, scientific computing, and large-scale simulations. Their ability to handle multiple instructions and data streams simultaneously makes them ideal for scenarios that require high performance and scalability
8. Comparison
Let’s have a quick comparison of these categories. This concise overview will help us understand the strengths and weaknesses of each architecture for various computational tasks.
Type
Instruction Streams
Data Streams
Example Systems
Pros
Cons
Performance Considerations
SISD
Single
Single
IBM 7090, Traditional uniprocessors
Simple design, easy to implement
Limited by sequential processing
Best for tasks with low parallelism
SIMD
Single
Multiple
Cray-1, Modern GPUs
Efficient for parallel data tasks
Limited to data-parallel applications
Ideal for tasks with high data parallelism
MISD
Multiple
Single
Specialized aerospace systems
High fault tolerance
Rarely used due to complexity and specific use cases
Suitable for high-reliability systems
MIMD
Multiple
Multiple
Intel Core, AMD Ryzen, Supercomputers
Highly scalable and flexible
Complex design and synchronization overhead
Best for highly parallel tasks with diverse processing needs
The table highlights the key differences between the four architectures in terms of their instruction and data streams, example systems, advantages, disadvantages, and performance considerations.
9. Modern Implications and Future Trends
Flynn’s Taxonomy continues to be a valuable tool for understanding modern computing technologies. It helps in categorizing and designing systems based on their parallel processing capabilities.
However, as technology continues to evolve, we’re progressing towards more efficient and powerful computational systems.
Let’s explore some of the emerging trends in this field.
9.1. Heterogeneous Computing
Heterogeneous computing refers to systems that integrate different types of processors, such as central processing units (CPUs), graphics processing units (GPUs), and specialized processors like digital signal processors (DSPs) or field-programmable gate arrays (FPGAs).
By leveraging the unique strengths of each processor type, heterogeneous computing can optimize performance for diverse workloads. For instance, CPUs handle complex sequential tasks, while GPUs excel at parallel data processing. Moreover, heterogeneous systems can be more energy-efficient by using specialized processors for specific tasks to reduce overall power consumption.
However, programming these systems is more complex, requiring knowledge of different architectures and often involving multiple programming languages and paradigms.
9.2. Quantum Computing
Quantum computing leverages the principles of quantum mechanics to process information using qubits, which can represent multiple states simultaneously, unlike classical bits. It introduces fundamentally different paradigms that challenge traditional classifications. Concepts like superposition and entanglement don’t fit neatly into Flynn’s original categories, suggesting a need for new or extended taxonomies.
Thus, Quantum computers have the potential to solve certain problems much faster than classical computers by exploiting quantum parallelism. This could revolutionize fields such as cryptography, materials science, and complex optimization problems.
Despite their potential, quantum computers are currently in the experimental stage, with significant challenges in error correction, qubit stability, and scalability.
9.3. Edge Computing
Edge computing involves processing data near the source of data generation (the “edge” of the network) rather than relying solely on centralized cloud data centers. By processing data closer to where it is generated, edge computing can significantly reduce latency, making it ideal for time-sensitive applications like autonomous vehicles, industrial automation, and real-time analytics.
Moreover, it reduces the need to transmit large volumes of data to centralized servers, saving bandwidth and lowering costs. Finally, Edge computing may lead to hybrid architectures that combine elements of traditional cloud computing and edge processing, creating systems that blend central and decentralized approaches.
9.4. Future of Computing
Continuous advancements in multi-core and many-core processors are pushing the boundaries of MIMD architectures. As manufacturers continue to increase the number of cores in processors, MIMD systems are becoming more powerful and capable of handling highly parallel tasks.
Improvements in interconnect technologies (such as faster buses and more efficient network topologies) are crucial for maintaining performance as core counts rise, reducing latency, and increasing bandwidth between cores. The trend towards integrating specialized cores (e.g., AI accelerators, security modules) within a single chip enhances the versatility and performance of multicore systems.
As new technologies and hybrid architectures emerge, there is potential for extending Flynn’s Taxonomy to better capture these developments. The introduction of new types of processing units and paradigms, such as neuromorphic computing (inspired by the human brain), optical computing (using light for data processing), and biocomputing (using biological molecules, such as DNA, for data storage and processing), may require new categories beyond Flynn’s original four.
10. Conclusion
In this article, we discussed how Flynn’s Taxonomy provides a clear and concise framework for classifying computer architectures based on their handling of instruction and data streams. Despite being proposed over five decades ago, it remains relevant and useful for understanding modern computing systems and their evolution.
By categorizing systems into SISD, SIMD, MISD, and MIMD, Flynn’s Taxonomy helps in comparing different architectures and understanding their strengths and weaknesses.
As we continue to innovate and develop new computing technologies, Flynn’s Taxonomy will undoubtedly evolve, reflecting the ever-changing landscape of computer architecture.