1. 概述
本文将带你了解 生成对抗网络(Generative Adversarial Networks, GANs) 的基本概念、结构原理、训练流程以及实际应用场景。
我们将从生成模型的基本分类谈起,接着深入介绍 GAN 的核心架构与训练机制,并通过具体示例帮助理解。最后,我们还将讨论 GAN 的一些实际挑战和应用场景。
2. 生成模型
在机器学习中,主要分为两大类学习方式:
2.1 监督学习(Supervised Learning)
我们拥有输入变量 X 和对应的标签 Y,目标是学习一个映射函数 f: X → Y,使得损失函数最小化。这类模型通常是判别模型(Discriminative Models),学习的是条件概率 **p(Y|X)**。常见的任务包括分类和回归。
2.2 无监督学习(Unsupervised Learning)
我们只有输入变量 X,目标是挖掘数据中的潜在结构。这类模型是生成模型(Generative Models),学习的是数据的联合分布 **p(X)**。常见任务包括聚类、降维等。
2.3 生成模型的目标
生成模型的核心目标是学习数据的分布。一旦模型掌握了这个分布,就可以:
- 判断一个样本出现的概率
- 生成符合该分布的新样本
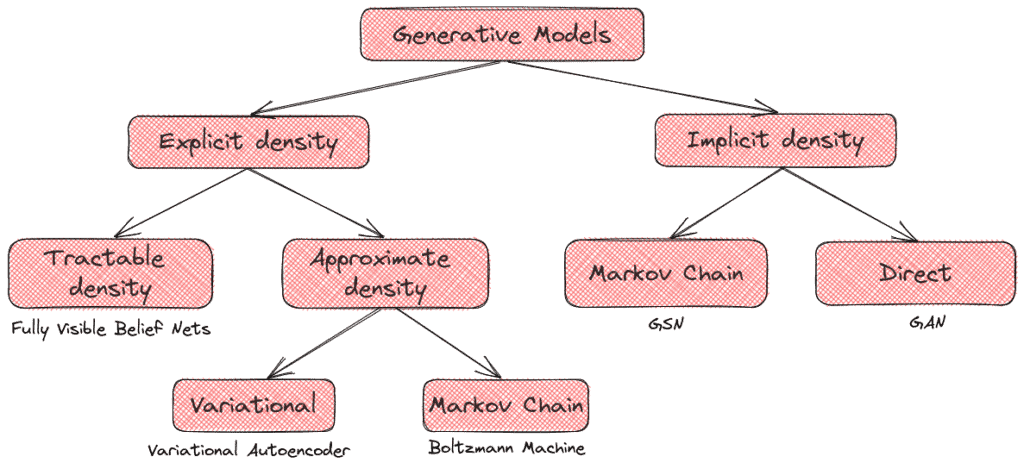
2.4 生成模型的分类
生成模型可分为两大类:
✅ 显式密度模型(Explicit Density Models):假设数据分布已知,通过最大化似然函数来拟合数据。若能用参数形式表达该密度函数,则称为“可处理密度函数”。
❌ 隐式密度模型(Implicit Density Models):不直接建模密度函数,而是通过某种随机过程直接生成数据。GAN 属于此类。
下图展示了生成模型的分类结构:
3. 生成对抗网络(GAN)
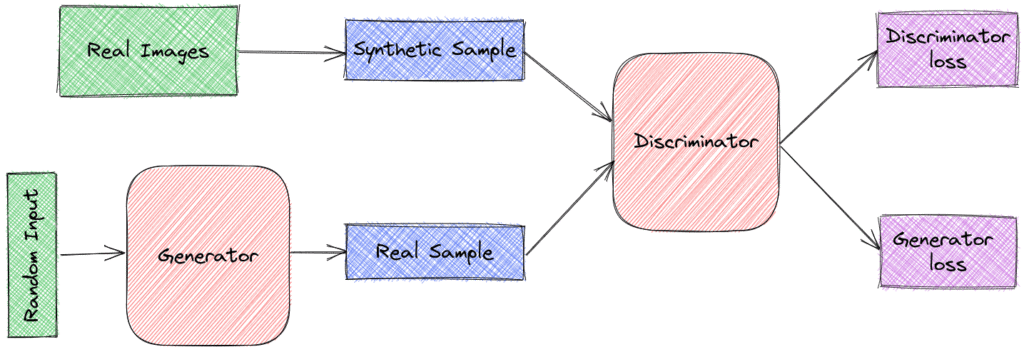
3.1 架构组成
GAN 由两个神经网络组成:
- 生成器(Generator):接受一个随机向量 z,输出一个样本 **G(z)**,目标是模仿真实数据的分布。
- 判别器(Discriminator):输入一个样本 x(来自真实数据或生成器),输出一个标量,表示该样本来自真实数据的概率。
GAN 的基本结构如下图所示:
两者均为可微函数,通常由神经网络实现。
3.2 损失函数
可以把 GAN 看作是生成器与判别器之间的博弈:
- 生成器像伪造货币的造假者,希望生成的样本能骗过判别器。
- 判别器则像警察,努力识别真假样本。
目标函数如下:

其中:
- D(x) 表示判别器认为 x 是真实样本的概率。
- G(z) 是生成器输出的样本。
优化过程是:
- 判别器最大化该目标函数,提升识别能力。
- 生成器最小化该目标函数,提升伪造能力。
⚠️ 注意:这不是一个标准的优化问题,而是一个博弈问题,目标是达到纳什均衡(Nash Equilibrium)。
3.3 训练流程
GAN 的训练采用同步随机梯度下降(SGD),每一步包括:
- 从真实数据集中采样 x
- 从先验分布中采样 z
- 分别通过生成器和判别器
- 同时更新两个模型的参数
这种训练方式对参数初始化和学习率非常敏感,容易导致训练不稳定。
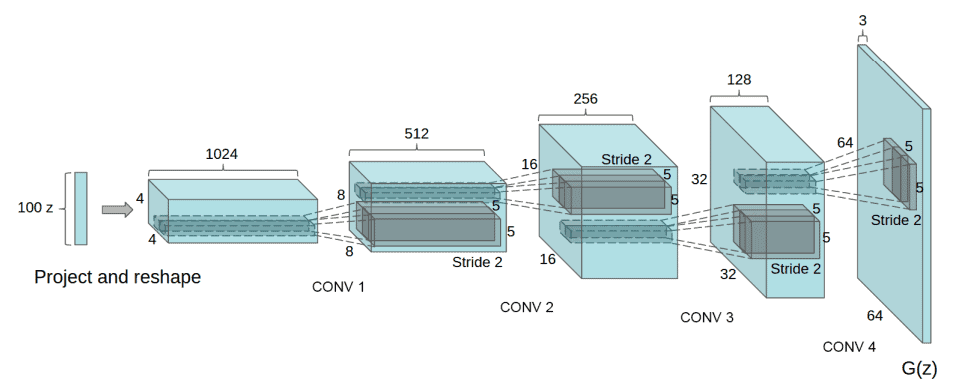
3.4 DCGAN 示例
深度卷积 GAN(Deep Convolutional GAN, DCGAN) 是图像生成中最常用的 GAN 架构之一,其特点包括:
- 在生成器和判别器的所有层使用 Batch Normalization
- 生成器使用 ReLU 激活函数
- 判别器使用 Leaky ReLU 激活函数
- 通常使用 Adam 优化器
其生成器的结构如下图所示:
3.5 示例:生成数字“7”
以 MNIST 数据集为例,展示 GAN 是如何一步步学会生成数字“7”的。
初始阶段,生成器输出的图像完全是噪声:

随着训练进行,生成器逐渐学会生成更接近“7”的图像:

最终,生成器输出的图像与真实“7”的分布非常接近:

4. 应用场景
GAN 在多个领域展现出巨大潜力,以下是几个典型应用:
4.1 数据增强(Data Augmentation)
当训练数据不足时,GAN 可用于生成合成样本,从而增强数据集的多样性。
4.2 图像修复(Image Inpainting)
GAN 可用于修复图像中的缺失或损坏区域。例如,下图展示了模型成功移除绳索后的效果:

4.3 超分辨率(Super-Resolution)
将低分辨率图像转化为高分辨率图像,广泛应用于安防、医学成像等领域。
4.4 图像到图像转换(Image-to-Image Translation)
将输入图像转换为另一种风格或结构。例如,使用 CycleGAN 实现风格迁移:

这只是 GAN 应用的冰山一角。随着研究的深入,GAN 的应用边界不断扩展。
5. 挑战与限制
尽管 GAN 在多个领域取得成功,但在训练和应用过程中仍面临诸多挑战:
5.1 收敛性问题(Non-convergence)
GAN 的训练本质是一个博弈问题,而非传统优化问题。因此,很难保证同时优化生成器和判别器的收敛性。
⚠️ 常见现象:生成器和判别器互相“抵消”,导致训练停滞。
5.2 评估难题(Evaluation)
GAN 的生成质量难以用单一指标衡量。虽然可以通过肉眼观察生成样本的质量,但缺乏统一的定量评估标准。
⚠️ 踩坑提醒:高似然值的模型可能生成不真实样本,反之亦然。
5.3 离散输出问题(Discrete Outputs)
GAN 的生成器需要是可微函数。若目标是生成离散数据(如文本),则传统 GAN 框架难以适用。
⚠️ 目前已有多种改进方案,但尚未形成统一解决方案。
5.4 编码向量获取困难(Latent Code Inversion)
生成器输入的随机向量 z 可视为样本的潜在特征表示。然而,给定一个样本 x,反推对应的 z 非常困难。
⚠️ 这限制了 GAN 在下游任务中的应用潜力。
6. 总结
本文系统介绍了 GAN 的基本原理、架构设计、训练方法以及实际应用。我们从生成模型的分类谈起,深入解析了 GAN 的生成器与判别器工作机制,并通过示例展示了其训练过程。
最后,我们总结了 GAN 的主要应用场景和当前面临的挑战。GAN 作为一个快速发展的领域,未来在图像生成、文本生成、风格迁移等方面仍有广阔前景。