1. Overview
In this tutorial, we’ll study the functioning of the algorithm “Did you mean?” by Google. We’ll first note what the user sees when conducting Google searches. Then we’ll study the theory behind the algorithm that works on the backend.
Incidentally, we’ll also learn how to exploit user behavior in order to have users label data for natural language processing tasks.
At the end of this tutorial, we’ll know how a search engine can guess the query search that a user inadvertently misspelled.
2. We Know What You Meant
2.1. What Does the User See?
The algorithm that Google uses to guess the desired query by a user who mistypes the search terms functions quite well. Let’s suppose the user searches for a word on Google but inadvertently misspells it:
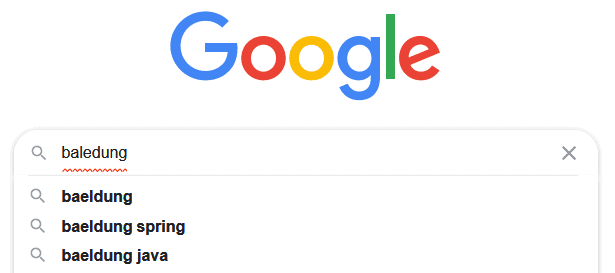
In that case, the search doesn’t show the literal query typed by the user. Instead, it uses the query that likely corresponds to the user’s intended text:
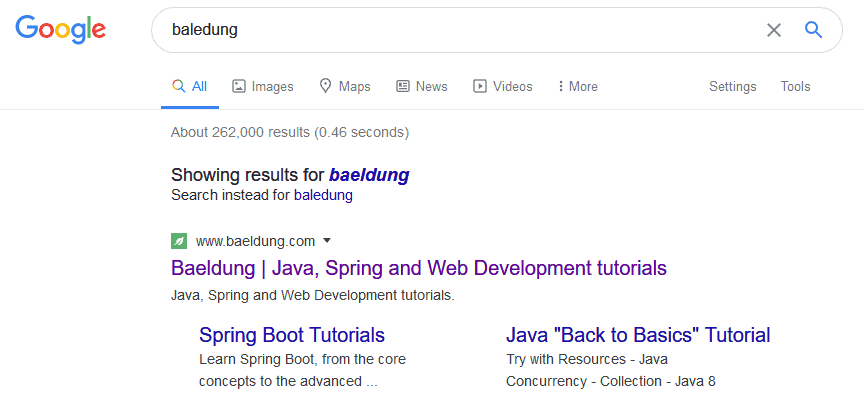
This works systematically for all search terms. When the typing mistake isn’t critical, the search automatically returns the most likely desirable results. It also ignores the literal content of the user input. When the misspelling is somewhat more serious, it provides us instead with a red warning and the suggestion for a possible correction:
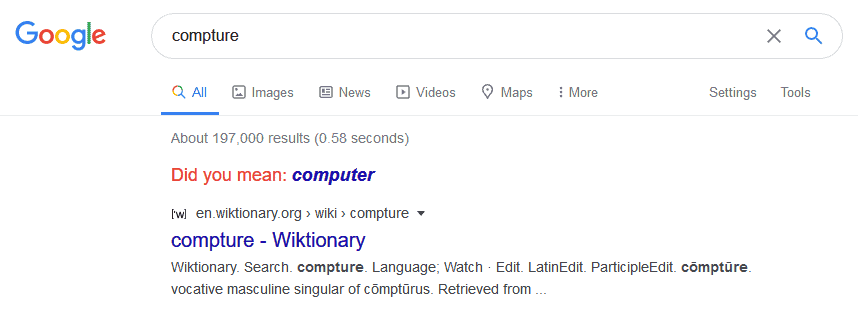
It does, however, run our literal search and then returns the corresponding result.
2.2. A Preliminary Black-Box Analysis
We can initially treat the back-end algorithm for this functionality as a black-box system and study its inner working by a statistical test of the relationship between our input and the algorithm’s output. If we repeat the experiment above with enough search terms and some realistic typos, we then get a feeling that the algorithm it compares the input against all other possible search terms and identifies the mistake.
When mistake is minor, it ignores it and returns the result corresponding to the most likely term. If the mistake is larger, it assumes it’s wanted by the user and thus provides the result to the literal query. In such case, though, it suggests a link with the most likely alternative search term that the user might have wanted.
It appears therefore that the search engine has a probabilistic system of some kind. It allows the identification of the most likely search that a user wanted, given its factual input. The actual algorithm doesn’t exactly work like described above, as we’ll see shortly, but this is a good starting point to learn how it functions.
3. Predicting Individual Intentions Using Aggregate Behavior
3.1. The Size of the Problem
If the algorithm worked exactly in the way we described, it would then require a large table containing, for all possible misspelled input, a list of terms which are the likely intended queries. This would likely be a very large table, as it needs to contain all commonly misspelled words:
User input
Most likely term
Less likely term
Unlikely term
absense
absence
adsense
absinthe
cheif
chief
chef
chaff
sieze
seize
sieve
cease
wether
weather
whether
wetter
It’s unlikely that a table of this type can be developed by the programmers without the assistance of some automated methods. This table would in fact grow in size very quickly. If we consider that the English dictionary alone has half a million words, hand-coding all of them, together with all of their variations, is unfeasible without automation.
3.2. Using User Usage
We can however outsource to the users themselves the task of labeling for us the common mistakes that relate to specific search terms. Let’s imagine that we have a crystal ball, which tells us if a user has found the content he was searching for, given the search query, or if he hasn’t:

If the user didn’t find the information he was searching for, we can ask the crystal ball to continue to monitor him. Then, when the user eventually finds its target, we ask the scrying device to gives us the sequence of queries by that user:
Luckily, we can build one such system. To do so, we need a method for understanding whether a user has incorrectly typed a search term first. And also that, after realizing their mistake, they modified the query and subsequently succeed in finding the target content.
This requires us to have a model of user behavior, in relation to the process of information retrieval. This is a model of the user, not the search engine’s, retrieval process.
We can develop this model while we conduct usability testing for our services. In doing that, we learn how to identify the termination condition. Then, together with it, also the success or failure of the information retrieval process.
3.3. Identifying User Success and Failure
This is a possible model for the process of information retrieval by the user of a search engine:
- at first, the user searches for content on our platform by using the first query
- then, if they find what they’re looking for, they select some of our content and stop using our system
- otherwise, they modify the search query and then repeat the search procedure
We assume that the process terminates. Termination takes place when the user clicks on some links and stops using our search system. When this happens, we analyze the sequence of search queries that the user employed.
The method to track these queries, with a browser-based search service, is by using cookies:
3.4. You Didn’t Really Mean That
Finally, the sequence of search queries that converges to the desired result can be compared with all sequences generated by all users of our service. In turn, this lets us build a model of the aggregated search process by all users.
Subsequently, whenever the first query is input by a new user, we can determine whether this query is known to lead to a distinct final query. If it does, then the algorithm “Did you mean?” can suggest the last element in the most common search sequence.
The more users progress to the same target content by inputting the same sequence of keywords, the more likely it is that the first sequential input meant, instead, the last.
4. Conclusion
In this article, we studied how the “Did you mean?” algorithm in Google works.