1. 概述
在本篇文章中,我们将探讨人工智能中两种常见的搜索策略:图搜索(Graph Search, GS) 和 树状搜索(Tree-Like Search, TLS)。这两种策略用于解决AI代理从起点状态到目标状态的最优路径查找问题。
搜索算法的核心在于如何遍历状态图中的节点。GS 和 TLS 的主要区别在于是否记录已访问的状态,以避免重复探索甚至陷入死循环。
2. 搜索问题与状态图
搜索问题是指AI代理需要找到从起始状态到目标状态的最优动作序列。所有可能的状态及其之间的转换关系构成了一个状态图(State Graph)。
一个状态可以是任意内容,取决于具体问题,比如:
- 二维地图中的一个点
- 产品组装顺序
- 国际象棋棋子的布局
3. 搜索树
搜索算法的不同之处在于它们访问状态图节点的顺序。有些算法会构建一个搜索树(Search Tree),其根节点是起始状态。
3.1 搜索树与状态图的区别
- 状态图中每个状态只出现一次
- 搜索树中同一个状态可能多次出现,表示从起点到该状态的不同路径
3.2 前沿(Frontier)
在搜索过程中,我们区分“访问”和“扩展”两个概念:
- 访问:找到从起点到某状态的路径
- 扩展:遍历该状态的所有子状态
我们维护一个前沿集合(Frontier),记录已访问但未扩展的状态。
搜索策略包含两个核心规则:
✅ 是否将新节点加入前沿
✅ 从前沿中选择哪个节点进行扩展
4. 图搜索(Graph Search)
GS 的核心规则是:
❌ 不要将节点加入前沿,如果它的状态已经被扩展过,或者已经在前沿中存在
4.1 伪代码
algorithm GenericGraphSearch(start_state, goal_test, state_graph, choose_one, phi):
frontier <- initialize the frontier to contain only the start node
reached <- make a lookup table that will contain states
while frontier is not empty:
u <- choose_one(frontier)
if u passes goal_test:
return u
for v in expand(u):
if (v.state not in reached) and phi(v):
Insert v.state into reached
Add v to frontier
return failure
4.2 实现细节
节点对象应包含:
- 当前状态
- 父节点指针(用于回溯路径)
- 动作(从父节点到当前节点)
- 路径总成本
frontier的实现依赖于具体算法:- DFS:使用 LIFO 队列(栈)
- BFS:使用 FIFO 队列
- UCS:使用优先队列(最小堆)
reached可以用 Set 或 Map 实现,需支持快速查找和插入
4.3 搜索树的隐式表示
在图搜索中,搜索树是隐式的:
✅ 搜索树由 reached 中但不在 frontier 中的节点构成
5. 树状搜索(Tree-Like Search)
TLS 是图搜索的简化版本,不维护 reached 集合,即不记录已访问状态。
5.1 伪代码
algorithm GenericTreeLikeSearch():
frontier <- initialize the frontier
while frontier is not empty:
u <- choose-one(frontier)
if u passes goal_test:
return u
for v in expand(u):
if phi(v):
add v to frontier
return failure
5.2 特点与问题
- 不检查重复状态
- 可能重复扩展同一状态
- 可能导致无限循环
⚠️ 在含有环路的状态图中,TLS 容易陷入死循环
6. 示例:DFS 的两种实现
我们以一个简单图为例,比较 GS 和 TLS 在深度优先搜索(DFS)中的行为差异。
6.1 测试图结构
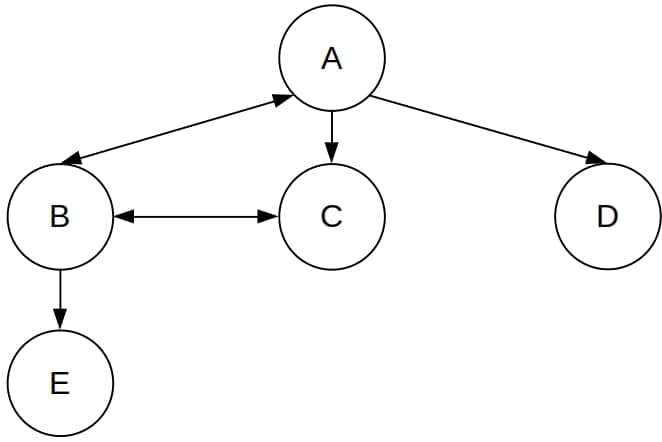
其中 A 是起始状态,没有目标状态。
6.2 TLS DFS 实现
algorithm TLSDFS(start, goalTest, state_graph):
s <- make the start node that contains the start state
if goal_test(s):
return s
frontier <- initialize a LIFO queue containing only s
while frontier is not empty:
u <- pop the node most recently added to frontier
for v in expand(u):
if goalTest(v):
return v
Add v to frontier
return failure
TLS DFS 的搜索路径如下图所示:
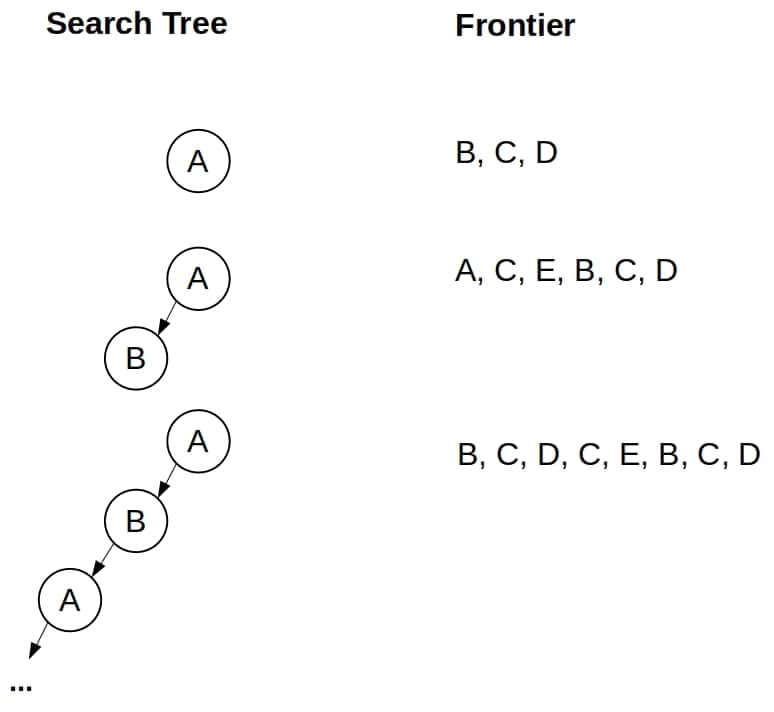
➡️ 结果:进入死循环,无法终止
6.3 GS DFS 实现
algorithm GSDFS(start_state, goal_test, state_graph):
s <- make the start node that contains the start state
if goal_test(s):
return s
frontier <- initialize a LIFO queue containing only s.state
reached <- make a set {s}
while frontier is not empty:
u <- pop the node most recently added to frontier
for v in expand(u):
if goal_test(v):
return v
if v.state not in reached:
add v to frontier
return failure
GS DFS 的搜索路径如下图所示:
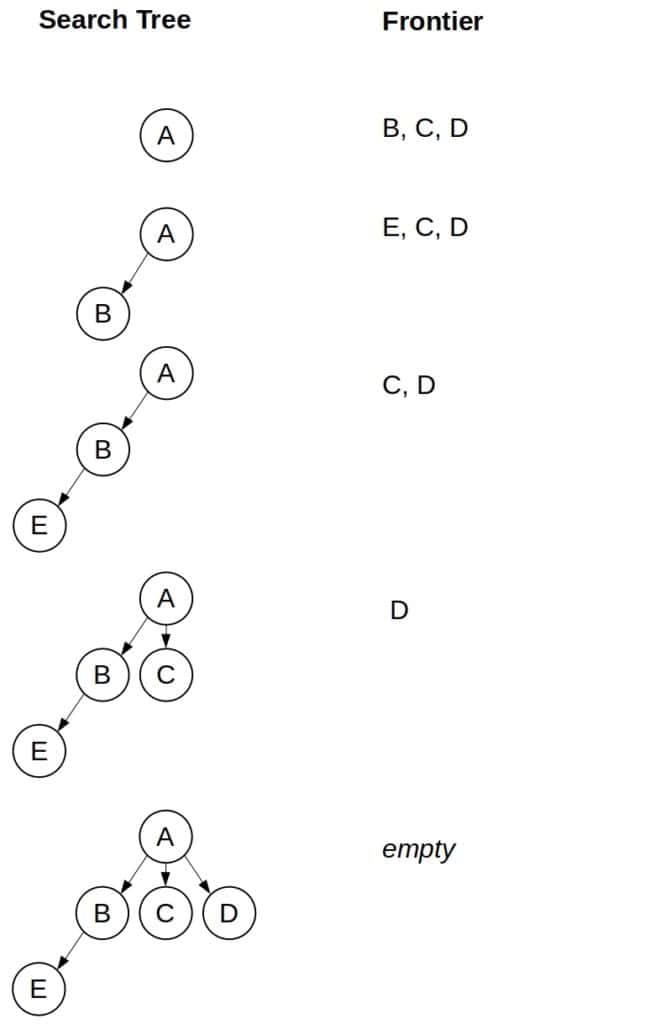
✅ 结果:成功避免死循环
7. 总结与讨论
| 特性 | 图搜索(GS) | 树状搜索(TLS) |
|---|---|---|
| 是否记录已访问状态 | ✅ 是 | ❌ 否 |
| 是否可能进入死循环 | ❌ 否 | ✅ 是 |
| 内存消耗 | ⬆ 较高 | ⬇ 较低 |
| 适用场景 | 含环图、需避免重复 | 无环图、内存受限 |
7.1 折中方案:防环搜索(Loop-Resistant Search)
可以仅检测路径是否构成环路,而非所有重复路径。这样可以在不记录所有状态的前提下避免死循环。
例如,只需判断当前节点是否在其父路径中出现过即可。
if v.state not in path_of(u):
add v to frontier
8. 结论
- 图搜索 更安全,避免重复和死循环,但内存开销大
- 树状搜索 更轻量,但在含环图中可能陷入死循环
- 折中方案 可在性能与安全性之间取得平衡
在实际应用中,应根据状态图的特性(是否有环、是否稀疏)选择合适的搜索策略。
✅ 踩坑提醒:在使用 TLS 时务必考虑图中是否存在环路,否则可能导致程序卡死或无限循环,特别是在图结构复杂或动态生成的场景中。