1. 概述
在图论中,深度优先搜索(DFS, Depth First Search)是一种重要的图遍历算法。本文将介绍该算法,并分别实现其递归与非递归版本。
我们会先讲解 DFS 的基本原理,并展示递归实现方式。随后,我们会分析非递归实现的思路,提供具体实现代码,并通过一个图示示例说明两种方式的执行流程。
最后,我们会对比两种实现方式,指出各自的适用场景。
2. 基本概念
2.1 算法原理
DFS 从一个起始节点开始,沿着一条路径尽可能深入,直到无法继续为止,然后回溯,尝试访问其他未访问的邻接节点。
与广度优先搜索(BFS)不同,DFS 不是按层遍历节点,而是“深入到底,再回溯”。
我们通常使用邻接表来表示图,这样可以高效地访问每个节点的邻居。
2.2 示例图
考虑如下图示:
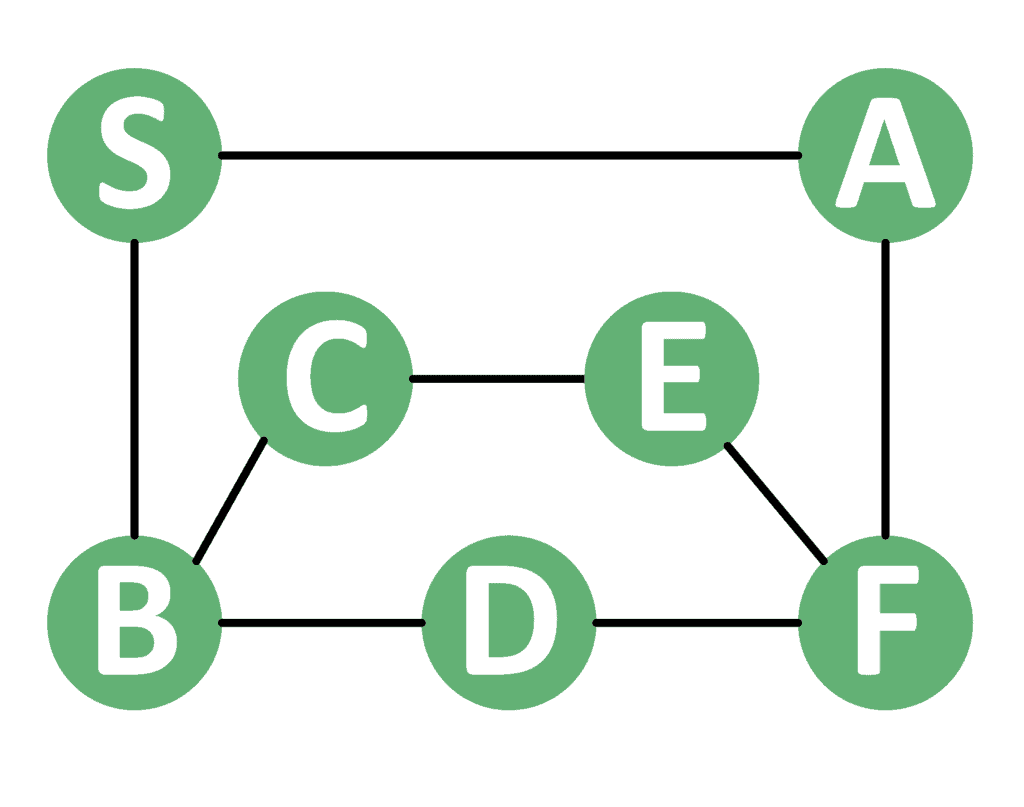
从节点 S 开始 DFS,假设邻接节点按字母顺序排列,则访问顺序为:
✅ S → A → F → D → B → C → E
3. 递归实现 DFS
3.1 实现思路
递归 DFS 的核心思想是:
- 从起始节点开始
- 标记当前节点为已访问
- 遍历所有邻接节点,递归调用 DFS
3.2 Java 示例代码
public class RecursiveDFS {
private boolean[] visited;
private List<List<Integer>> adjList;
public RecursiveDFS(int n) {
visited = new boolean[n];
adjList = new ArrayList<>();
for (int i = 0; i < n; i++) {
adjList.add(new ArrayList<>());
}
}
public void addEdge(int u, int v) {
adjList.get(u).add(v);
}
public void dfs(int u) {
visited[u] = true;
System.out.print(u + " ");
for (int v : adjList.get(u)) {
if (!visited[v]) {
dfs(v);
}
}
}
public void traverse(int root) {
dfs(root);
}
}
3.3 时间复杂度
- ✅ 时间复杂度:**O(V + E)**,其中 V 是节点数,E 是边数
- ✅ 空间复杂度:**O(V)**(递归栈 + visited 数组)
4. 非递归实现 DFS
4.1 实现思路
非递归 DFS 的核心思想是模拟递归栈的行为:
- 使用一个显式的栈来保存待访问节点
- 每次从栈中弹出一个节点,处理它,并将其未访问的邻接节点压入栈中
- 注意:邻接节点应按逆序压入栈中,以保证访问顺序与递归一致
4.2 Java 示例代码
public class IterativeDFS {
private boolean[] visited;
private List<List<Integer>> adjList;
public IterativeDFS(int n) {
visited = new boolean[n];
adjList = new ArrayList<>();
for (int i = 0; i < n; i++) {
adjList.add(new ArrayList<>());
}
}
public void addEdge(int u, int v) {
adjList.get(u).add(v);
}
public void dfs(int root) {
Stack<Integer> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
int u = stack.pop();
if (visited[u]) continue;
visited[u] = true;
System.out.print(u + " ");
// 逆序压栈,保证访问顺序一致
for (int i = adjList.get(u).size() - 1; i >= 0; i--) {
int v = adjList.get(u).get(i);
if (!visited[v]) {
stack.push(v);
}
}
}
}
}
4.3 时间复杂度
- ✅ 时间复杂度:O(V + E)
- ✅ 空间复杂度:**O(V)**(显式栈 + visited 数组)
5. 示例对比
我们以如下图为例:
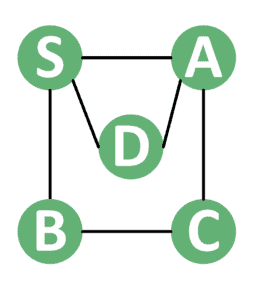
5.1 递归 DFS 访问顺序
✅ S → A → C → B → D
5.2 非递归 DFS 访问顺序
✅ S → A → C → B → D
两种方式的访问顺序一致,说明逻辑是等价的。
6. 递归 vs 非递归
| 特性 | 递归 DFS | 非递归 DFS |
|---|---|---|
| 实现难度 | ✅ 简洁易写 | ❌ 相对复杂 |
| 栈空间 | 使用系统调用栈 | 使用显式栈(堆内存) |
| 栈溢出风险 | ⚠️ 图很大时可能栈溢出 | ✅ 更安全 |
| 可控性 | ❌ 难以控制中间状态 | ✅ 可灵活控制栈 |
| 推荐使用 | ✅ 一般场景 | ✅ 图非常大或栈受限时 |
7. 总结
深度优先搜索(DFS)是一种基础且重要的图遍历算法,具有广泛的应用场景,如路径查找、连通性检测、拓扑排序等。
- ✅ 递归实现简单直观,适合大多数情况
- ✅ 非递归实现更安全,适用于图较大或栈受限的环境
- ⚠️ 注意邻接节点压栈顺序,以保持与递归一致的访问顺序
掌握 DFS 的两种实现方式,有助于在实际开发中灵活应对不同场景。