1. 引言
本文将深入探讨 Hash Code(哈希码) 与 Checksum(校验和) 之间的异同。两者在生成方式上确实存在相似之处,因此在实际开发中容易被混淆。但它们各自的应用场景和设计目标截然不同。
我们会从基础概念讲起,然后分别介绍 Hash Code 和 Checksum 的定义、用途以及典型实现方式。最后,我们还会通过对比总结帮助你更清晰地理解它们之间的区别与联系。
2. 基础概念
首先明确一点:Checksum 本质上也是一种 Hash Code。 只不过,Hash Code 是一个更广泛的概念,涵盖多种应用场景。
哈希(Hashing)的核心思想是将任意长度的数据转换为固定长度的编码(即哈希值)。这个过程通过 哈希函数(Hash Function) 实现。
哈希函数将输入数据映射为一个 哈希码(Hash Code),也被称为哈希值、摘要或简称哈希。
下图展示了哈希过程的高层抽象:

需要注意的是,哈希过程是 不可逆的。也就是说,我们可以通过原始数据生成哈希码,但无法从哈希码反推出原始数据。
基于这些特性,哈希技术被广泛应用于多个领域,例如:
- ✅ 哈希表(Hash Table):用于快速查找数据
- ✅ 加密哈希(Cryptographic Hash):用于密码存储、数字签名等安全场景
- ✅ 校验和(Checksum):用于验证数据完整性
接下来,我们将分别探讨这些应用场景中的 Hash Code 与 Checksum 的具体实现与用途。
3. Hash Code(哈希码)的应用场景
Hash Code 是一个通用概念,其具体实现会根据应用场景的不同而有所调整。以下两个是最常见的使用方向:
3.1. 哈希表(Hash Table)
哈希表 是一种基于键值对的高效数据结构。它的核心在于使用哈希函数将任意类型的键(Key)转换为统一格式的索引,从而实现快速的插入、查找和删除操作。
从用户角度看,键可以是任意类型和长度;但从实现角度看,哈希函数需要将这些异构键统一映射到固定长度的整数索引。
下图展示了哈希表中数据存储的基本流程:
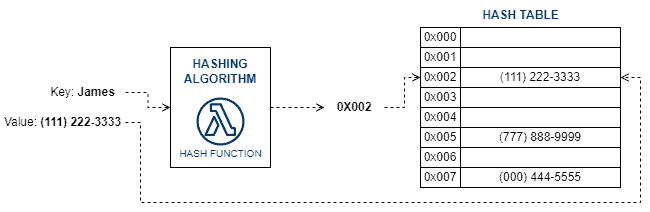
在哈希表的设计中,开发者最关心的问题是 哈希冲突(Collision) —— 即不同键生成相同哈希值。虽然可以通过链表或开放寻址等方式解决冲突,但这些方法会增加访问和维护的复杂度。
3.2. 加密哈希(Cryptographic Hash)
加密哈希用于保护敏感数据,如用户密码。它的核心特性是:
- ✅ 单向性(One-way):无法从哈希值还原原始数据
- ✅ 抗碰撞(Collision Resistance):极难找到两个不同的输入生成相同的哈希值
在用户登录验证中,系统通常会对比输入密码的哈希值与数据库中存储的哈希值是否一致。这种方式即使哈希泄露,也能保护原始密码安全。
下图展示了加密哈希的基本流程:
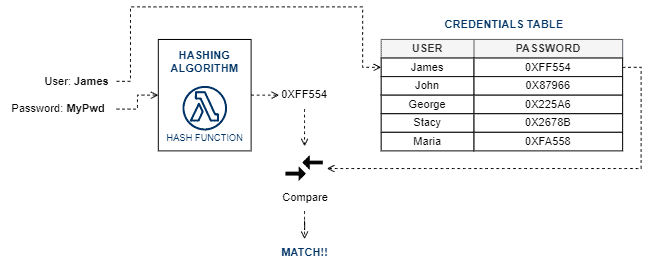
加密哈希的典型算法包括:
- ✅ SHA-256
- ✅ SHA-3
- ✅ bcrypt
- ✅ scrypt
4. Checksum(校验和)
Checksum 本质上也是一种 Hash Code,但它专注于数据完整性验证。
你可以将 Checksum 理解为数据的“指纹”。当你对某段数据计算其 Checksum 后,如果数据发生任何变化(哪怕只是一个比特位),Checksum 也会随之改变。
这使得 Checksum 成为验证数据是否被篡改或传输过程中是否出错的有力工具。
✅ 典型应用场景包括:
- ✅ 文件完整性校验(如下载后验证 MD5)
- ✅ 网络传输中的错误检测
- ✅ 数字签名的一部分
⚠️ 与加密哈希的区别:
- ✅ 速度优先:Checksum 的计算速度通常比加密哈希更快,因为其目标不是安全性而是完整性
- ❌ 不保证抗碰撞:Checksum 可能更容易出现碰撞,不适合用于安全场景
示例:文件完整性校验流程
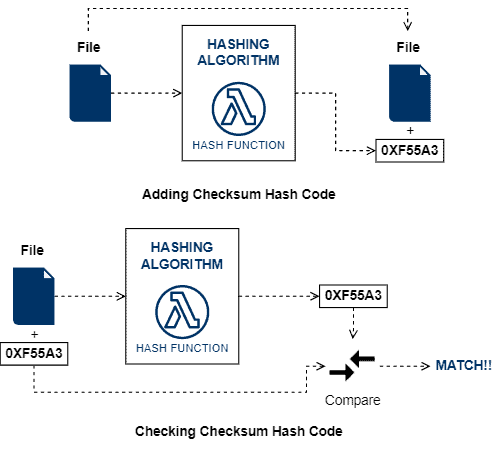
✅ 常用算法包括:
- ✅ MD5(128 位,RFC1321)
- ✅ SHA-1(160 位,RFC3174)
- ✅ CRC32(常用于网络传输)
5. 对比总结
| 类别 | Hash Code(通用) | Checksum |
|---|---|---|
| 核心目标 | 生成统一长度的编码 | 验证数据完整性 |
| 期望特性 | 单向性、抗碰撞 | 快速计算、敏感变化响应 |
| 典型用途 | 哈希表、密码存储 | 文件校验、传输错误检测、数字签名 |
| 注意事项 | 可基于部分数据生成 | 必须基于完整数据生成 |
6. 总结
Hash Code 是计算机科学中一个基础而强大的概念,广泛应用于数据结构、安全加密和数据完整性验证等多个领域。
Checksum 是 Hash Code 的一个重要子集,专注于快速检测数据是否发生变化。虽然它与加密哈希在技术实现上有相似之处,但其设计目标和适用场景截然不同。
✅ 关键点总结如下:
- ✅ Hash Code 是通用概念,根据用途不同,实现方式也不同
- ✅ Checksum 是用于完整性验证的 Hash Code,强调速度和敏感性
- ✅ 加密哈希更注重安全性和抗逆向能力
- ✅ 在实际开发中,选择合适的 Hash 算法至关重要,避免“用错场景”
希望这篇文章能帮助你更清晰地理解 Hash Code 与 Checksum 的区别与联系,在今后的开发中避免踩坑,做出更合理的技术选型。