1. 介绍
在本文中,我们将深入了解光学字符识别(OCR)技术。我们会先了解OCR的实际用途,然后逐步讲解其基本工作流程,并介绍一些常用的OCR模型和训练数据集。
如果你是从事文档处理、图像识别或自动化数据提取相关的开发工作,OCR技术对你来说一定不陌生。它可以帮助我们将图像中的文字内容转化为可编辑、可搜索的文本格式,极大提升信息处理效率。
2. 什么是光学字符识别?
光学字符识别(OCR)是一种将图像中的文字内容转换为机器可读文本格式的技术。
OCR 的核心价值在于:它让文字的检索、编辑和存储变得简单,从而简化了数据录入流程。对企业、个人用户而言,OCR 技术使得文档可以被电子化保存并随时调用。
2.1 从图像中提取有用文本
OCR 技术通过自动提取图像中的文字内容,节省了大量人工录入的时间和成本。
OCR 应用可以从扫描文档、照片、以及纯图像格式的 PDF 文件中提取文本内容:

OCR 软件会识别图像中的字符,将其转换为单词,再组合成句子,最终输出结构化文本。这种方式无需人工参与,即可完成数据的电子化处理。
2.2 一种压缩技术
OCR 同时也是一种有效的数据压缩手段。通过将图像文档转换为纯文本或富文本格式,可以显著减小文件体积,同时保留关键信息。
在使用 OCR 提取文本时,我们更关注文字内容本身,而非其排版样式或字体。虽然字体、字号、语言等信息也有价值,但不是最关键的:

OCR 可以将纸质文档和扫描图像转换为可搜索的 PDF 文件,从而优化大数据建模流程。没有 OCR,很多缺少文字图层的文档将无法被自动化处理和分析。
3. OCR 引擎是什么?
OCR 系统通常由硬件和软件共同组成,用于将纸质文档转化为机器可读文本。硬件部分包括扫描仪或专用电路板,而软件部分则负责高级处理。
20 世纪 90 年代初,OCR 技术因数字化旧报纸而流行。如今,OCR 技术已高度成熟,现代 OCR 引擎的识别准确率已接近完美水平。
OCR 引擎是 OCR 软件工具链中执行识别任务的核心组件。
常见 OCR 引擎包括:
- Transym
- Tesseract
- ABBYY
- Prime
- Azure
这些引擎在不同场景下各有优势,开发者可以根据项目需求进行选择。
4. OCR 引擎的基本工作流程
OCR 引擎的工作流程通常包括以下几个关键步骤:
- 图像预处理
- 图像二值化
- 字体/风格识别
- 字符识别
- 结果优化
下面我们将逐一介绍。
4.1 图像二值化
图像二值化的目的是去除图像中的非文本元素,提高识别效率。
文档图像通常以灰度图形式存储,每个像素点的灰度值在 0~255 之间。如果直接处理多灰度图像,会增加计算复杂度。
二值化后的图像(黑白图像)可以显著减少处理时间。

二值化的基本方法是设定一个阈值(threshold):
- 如果像素的灰度值高于阈值,则设为白色(255)
- 否则设为黑色(0)
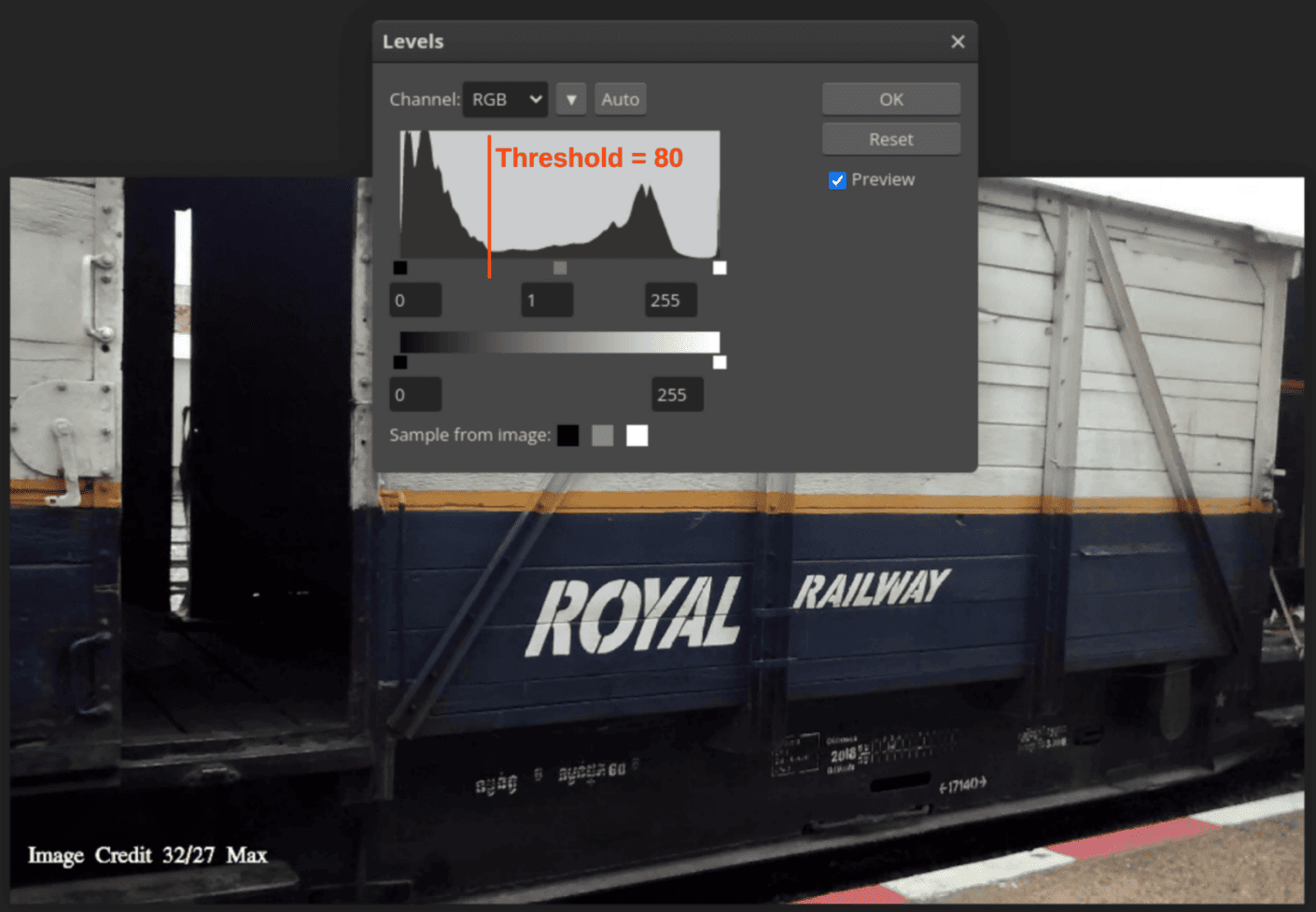
二值化方法包括:
- 全局阈值法(Global Thresholding)
- 局部阈值法(Adaptive Thresholding),使用滑动窗口(moving window)动态调整每个区域的阈值
4.2 风格分类(Style Classification)
风格分类的目标是识别文本的字体类型、是否为手写体,甚至是谁的笔迹。
不同语言的文字风格差异很大。例如:
- 阿拉伯语是从右向左书写
- 印度语系中常有连笔字
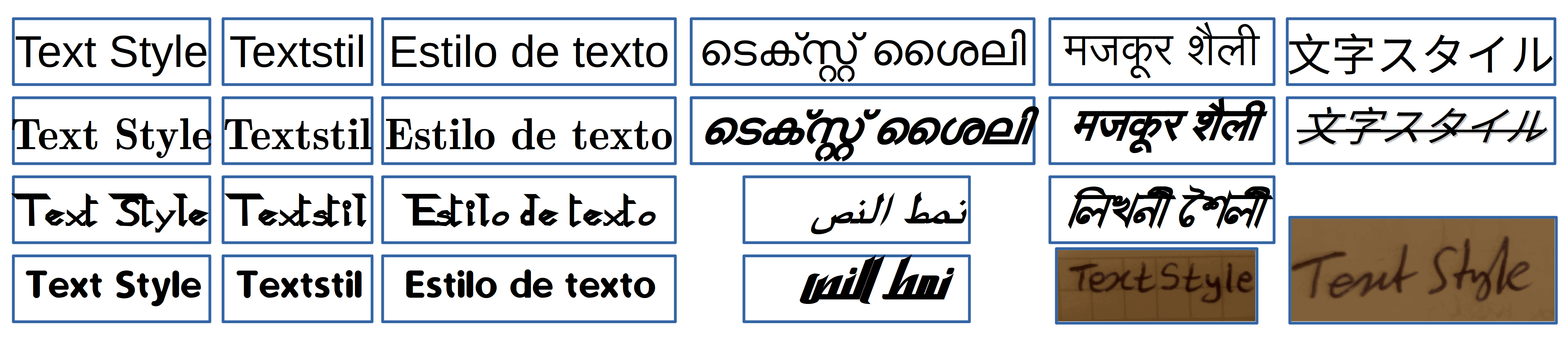
风格识别对后续的字符识别算法选择至关重要。
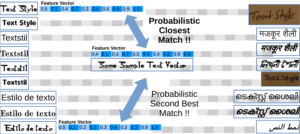
实现方式包括:
- 提取文本样本
- 将样本转换为特征向量(feature vector)
- 与已有字体/语言特征库进行匹配
4.3 字符识别(Character Classification)
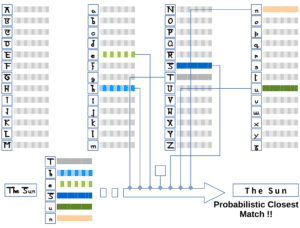
这是 OCR 引擎的最后一步,目标是识别图像中每个字符。
根据风格分类结果,将字符从图像中分割出来,并使用以下方法之一进行识别:
- 特征检测(Feature Detection):基于字符的几何属性(如线条数量、角度等)进行识别
- 模式识别(Pattern Recognition):使用已训练好的识别模型进行比对
4.4 结果优化(Refinements)
OCR 引擎通常会通过以下方式优化识别结果:
- 字典纠错:将识别出的“错误单词”替换为最接近的正确单词(类似手机输入法的自动纠错功能)
- 上下文修正:利用语言模型或语法规则修正语义不通的句子
- 位置信息辅助:例如电话号码区域应为数字,姓名区域应为字母组合
5. OCR 分类模型
OCR 引擎使用的分类模型主要分为两类:
- 传统方法(Classical Methods)
- 现代方法(Modern Methods)
5.1 传统方法
传统 OCR 模型多采用统计模型,如:
- 隐马尔可夫模型(HMM):适用于连笔字、手写体识别,无需先分割字符
- 自然语言处理(NLP)模型:用于语义优化和上下文纠错
✅ 优点:模型轻量,适合嵌入式设备
❌ 缺点:识别准确率受限,对复杂场景支持差
5.2 现代方法
现代 OCR 多采用机器学习和深度学习技术,常见模型包括:
- 支持向量机(SVM):适用于图像分类和回归任务,识别准确率高
- 卷积神经网络(CNN):用于图像特征提取和字符识别
- Transformer 模型:用于处理长文本序列,支持上下文建模
⚠️ 特别说明:深度学习模型在低分辨率图像识别中表现不佳,需配合超分辨率(super-resolution)技术提升图像质量。
✅ 优点:识别精度高,支持多语言、多字体
❌ 缺点:模型较大,计算资源消耗高
5.3 OCR 训练数据集
训练高质量的 OCR 模型需要大量标注数据,常见数据集包括:
| 数据集名称 | 内容描述 |
|---|---|
| SVHN | 包含 26032 个测试数字、73257 个训练数字 |
| Scene Text | 包含 3000 张英文和韩文场景文本图像 |
| Devanagari 字符集 | 包含印度语系 25 位书写者的 1800 个样本 |
⚠️ 踩坑提醒:英文数据集丰富,但其他语言(如中文、阿拉伯语)的数据集较少,训练模型时需注意数据多样性。
6. 总结
本文我们系统地讲解了 OCR 技术的基本原理和工作流程,包括:
- 图像预处理(二值化)
- 风格识别
- 字符识别
- 结果优化
我们还介绍了 OCR 引擎常用的分类模型(如 HMM、SVM、CNN)及其训练数据集。
OCR 技术广泛应用于文档数字化、自动化数据录入、智能客服等多个领域。随着深度学习的发展,OCR 的识别精度和应用场景也在不断提升和扩展。
如果你正在开发图像识别、文档处理类项目,OCR 技术是一个非常值得深入研究的方向。