1. 引言
在本教程中,我们将探讨高可用性(High Availability)与容错(Fault Tolerance)这两个概念之间的异同。
随着网络技术的发展和云计算的普及,联网服务已经深入到我们生活的方方面面。服务提供商需要确保这些服务在任何时间、任何地点都能正常访问。为此,他们通常会签订最低服务可用性协议,并采用各种容错与恢复机制来保障服务的连续性。
虽然这两个概念常常被混为一谈,但实际上它们并不等价。接下来我们将先介绍背景知识,然后分别深入探讨高可用性和容错机制,最后通过对比帮助你更清晰地理解它们的差异和适用场景。
2. 背景知识
尽管高可用性和容错机制早已存在,但真正推动其发展的,是云计算的普及。
云计算通过互联网提供各种计算资源,使得服务方能够在线部署服务,供全球用户访问。常见的服务模式包括:
- 基础设施即服务(IaaS)
- 平台即服务(PaaS)
- 软件即服务(SaaS)
无论采用哪种模式,用户都期望在需要时能立即访问这些服务。这就对系统的稳定性和可靠性提出了更高的要求,高可用和容错机制正是为了解决这一问题而设计的。
2.1 冗余(Redundancy)
在讨论高可用和容错之前,我们必须理解一个关键概念:冗余。
冗余是指部署多个系统组件的副本(硬件或软件)。这些副本在正常运行时并非必须,但在故障发生时能确保服务不中断。
冗余是实现高可用和容错的基础。接下来我们会看到,两者在冗余的使用方式上有所不同。
3. 高可用性(High Availability)
高可用性是一种设计目标,旨在尽可能减少系统或服务的停机时间。
它的核心目标是保持系统持续可用。通常通过服务可用时间百分比来衡量。常见的可用性等级如下:
| 可用率 | 最大年停机时间 |
|---|---|
| 90%(一个九) | 约36.5天 |
| 99%(两个九) | 约3.65天 |
| 99.9%(三个九) | 约8.77小时 |
| 99.99%(四个九) | 约52.6分钟 |
| 99.999%(五个九) | 约5.26分钟 |
更高的可用性意味着更小的停机时间,但也意味着更高的成本。实际选择时应根据服务等级协议(SLA)来决定合适的可用性等级。
3.1 高可用系统的实现方式
高可用系统通常依赖组件复制来实现,这些复制的组件组成一个高可用集群(High Availability Cluster)。
集群中的组件共享资源,如数据库、配置文件等。当主节点出现故障或负载过高时,备用节点可以迅速接管服务。
下图是一个简化的高可用系统架构示意图:
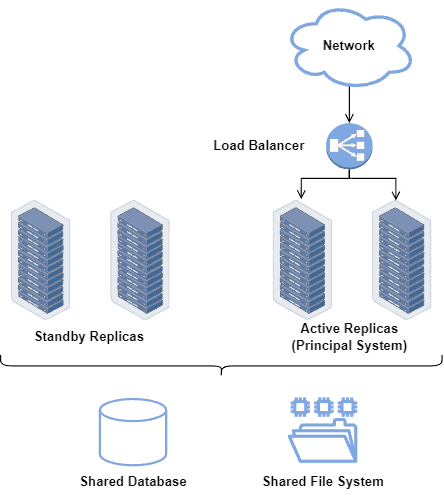
备用系统通常处于“待命”状态,只在主系统故障时才启用。从主系统故障到备用系统启动的时间被视为非运行时间,这个时间越短,系统的可用性越高。
✅ 踩坑提醒:不要盲目追求“五个九”,除非你的业务真的需要。否则,高可用带来的成本和复杂度可能远超预期。
4. 容错(Fault Tolerance)
容错是指系统在出现故障时仍能继续正常运行的能力。
容错系统不仅能检测和处理故障,还能在不影响服务的前提下恢复组件。它强调的是即使某些组件失效,系统整体仍能提供正确服务。
容错的关键在于系统对故障的定义和处理方式。常见的故障模型有:
- Fail-stop:组件直接崩溃,停止工作
- Fail-silent:组件未崩溃,但未按预期响应
- Byzantine(拜占庭故障):组件行为不可预测,可能时好时坏
容错系统的设计目标是在一定数量的故障发生时,仍能输出正确结果。
4.1 容错系统的实现方式
容错系统通常也依赖组件复制,但与高可用系统不同的是,这些组件独立运行并协作,通过多数投票机制确定最终结果。
假设系统需要容忍 f 个故障,通常需要至少 n 个副本,其中:
- 对于 Fail-stop 故障,n ≥ 2f + 1
- 对于 Byzantine 故障,n ≥ 3f + 1
下图展示了一个容错 DNS 系统的简单示意图:
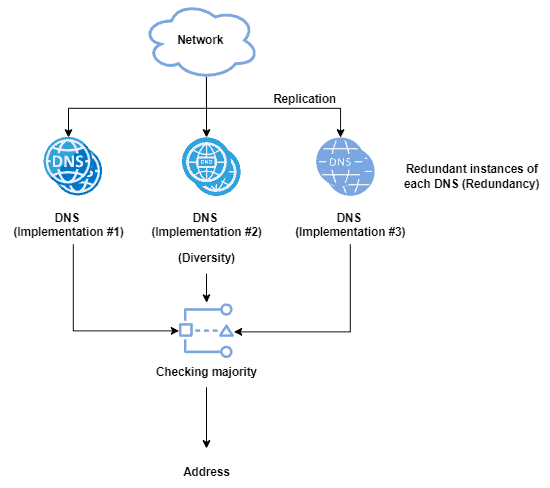
除了冗余,容错系统还强调多样性(Diversity),即使用不同的实现方式来降低共性故障的风险。
❌ 踩坑提醒:容错系统成本高、复杂度高,适合对可靠性要求极高的场景,如金融交易、航空航天等。
5. 对比总结
| 特性 | 高可用(High Availability) | 容错(Fault Tolerance) |
|---|---|---|
| 目标 | 最小化系统停机时间 | 即使有故障也能正常运行 |
| 核心机制 | 冗余、共享资源 | 冗余、复制、多样性 |
| 基础设施 | 多个冗余组件 + 管理系统 | 多个复制组件 + 协作机制 |
| 优点 | 成本较低、易扩展、负载均衡 | 零中断、无数据丢失 |
| 缺点 | 难以维持高可用等级、可能有数据丢失 | 系统复杂、成本高昂 |
⚠️ 注意:高可用 ≠ 容错,但二者可以结合使用,打造既稳定又可靠的系统。
6. 总结
随着网络服务的普及,越来越多的关键业务依赖于在线系统。在这种背景下,高可用性和容错成为现代系统设计中不可或缺的两个方面。
- 高可用性关注的是系统的持续运行能力,强调最小化停机时间
- 容错则更进一步,要求系统在出现故障时仍能正确运行
它们各有侧重,适用于不同场景。合理选择并结合使用,才能构建出真正健壮的系统。
✅ 总结建议:
- 如果你追求的是“服务不中断”,优先考虑高可用方案
- 如果你的系统不能容忍任何错误输出,必须使用容错机制
- 实际项目中,往往需要将两者结合使用
高可用和容错是系统架构设计中的“双子星”,缺一不可。掌握它们的原理和适用场景,是每位高级工程师的必修课。