1. 概述
在深度学习中,标准化(Normalization)是提升模型训练效率和性能的重要手段之一。本文将重点介绍两种常见的归一化方法:实例归一化(Instance Normalization, IN) 和 批归一化(Batch Normalization, BN),并对比它们的实现机制和适用场景。
2. 为什么需要标准化
标准化(Normalization)的核心思想是让不同范围的特征对模型的影响保持均衡。例如在预测汽车价格的模型中,如果一个特征是“行驶里程”(以千为单位),另一个是“车龄”(以年为单位),不加处理的话,前者会主导模型的学习过程,导致后者被“忽略”。
在深度神经网络中,不仅输入层需要标准化,隐藏层的激活值也可能因分布偏移而影响训练稳定性。因此,在中间层引入标准化操作,有助于缓解梯度消失、加速训练过程。
3. 实例归一化(Instance Normalization)
3.1 基本概念
实例归一化(IN)最初在 StyleNet 中被提出,也被称为对比度归一化(Contrast Normalization)。它的核心思想是:
对单个样本的特征图进行归一化处理
也就是说,IN 是在每个样本的每个通道上,对其空间维度(宽和高)进行均值和方差的计算。
3.2 数学公式
假设输入张量为 $ x \in \mathbb{R}^{N \times C \times H \times W} $,其中:
- $ N $:batch size
- $ C $:通道数
- $ H \times W $:特征图大小
对于每个样本 $ x_{ni} $(第 $ n $ 个样本,第 $ i $ 个通道):
均值:
$$ \mu_{ni} = \frac{1}{HW} \sum_{l=1}^{W} \sum_{m=1}^{H} x_{nilm} $$方差:
$$ \sigma^2_{ni} = \frac{1}{HW} \sum_{l=1}^{W} \sum_{m=1}^{H} (x_{nilm} - \mu_{ni})^2 $$归一化后输出:
$$ y_{nijk} = \frac{x_{nijk} - \mu_{ni}}{\sqrt{\sigma^2_{ni} + \epsilon}} $$
其中 $ \epsilon $ 是一个防止除零的小常数。
最后通过两个可学习参数 $ \gamma $ 和 $ \beta $ 进行线性变换,以保留模型的表达能力:
$$ y_{nijk} = \gamma \cdot \hat{x}_{nijk} + \beta $$
3.3 图示说明
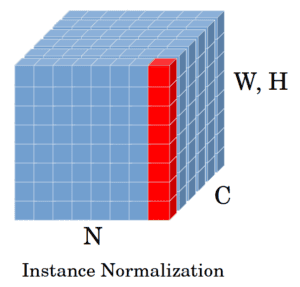
IN 对每个样本的每个通道,按空间维度(H × W)做归一化
4. 批归一化(Batch Normalization)
4.1 基本概念
批归一化(BN)最早由 Ioffe 和 Szegedy 在 2015 提出,其核心思想是:
对一个 batch 中所有样本的同一通道进行归一化
也就是说,BN 是在每个通道上,对 batch 中所有样本的该通道做均值和方差统计。
4.2 数学公式
对于输入张量 $ x \in \mathbb{R}^{N \times C \times H \times W} $,BN 的计算如下:
均值:
$$ \mu_i = \frac{1}{NHW} \sum_{n=1}^{N} \sum_{l=1}^{W} \sum_{m=1}^{H} x_{nilm} $$方差:
$$ \sigma^2_i = \frac{1}{NHW} \sum_{n=1}^{N} \sum_{l=1}^{W} \sum_{m=1}^{H} (x_{nilm} - \mu_i)^2 $$归一化后输出:
$$ \hat{x}{nijk} = \frac{x{nijk} - \mu_i}{\sqrt{\sigma^2_i + \epsilon}} $$最终输出:
$$ y_{nijk} = \gamma \cdot \hat{x}_{nijk} + \beta $$
同样,$ \gamma $ 和 $ \beta $ 是可学习参数。
4.3 图示说明
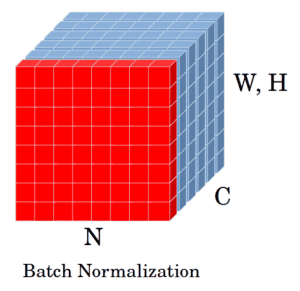
BN 对 batch 中所有样本的同一通道做归一化
5. IN 与 BN 的对比分析
| 特性 | 实例归一化(IN) | 批归一化(BN) |
|---|---|---|
| 归一化维度 | 单个样本的每个通道(C × H × W) | 同一通道的所有样本(N × H × W) |
| 依赖 batch size | ❌ 不依赖 | ✅ 依赖(batch 越大越稳定) |
| 训练 vs 推理阶段一致性 | ✅ 一致 | ⚠️ 不一致(推理时用移动平均) |
| 适合场景 | 风格迁移、生成模型(如 GAN) | 分类、检测等通用任务 |
| 内存占用 | 更低 | 较高(需保存 batch 统计信息) |
5.1 实际应用中的注意事项
- BN 对 batch size 敏感:小 batch size 时,BN 的统计量不稳定,影响训练效果。
- IN 更适合图像生成任务:比如在 GAN 或风格迁移中,IN 能更好地保留图像的结构和纹理。
- BN 更适合分类任务:BN 能提升训练速度并增强泛化能力,广泛用于 CNN 分类模型中。
6. 总结
- IN 是对单个样本的每个通道进行归一化,适合图像生成、风格迁移等任务。
- BN 是对 batch 中所有样本的同一通道进行归一化,适合分类、检测等任务。
- BN 对 batch size 敏感,推理阶段需使用移动平均;IN 则在训练和推理阶段表现一致。
- 实际使用中应根据任务类型、batch size 限制、模型结构等因素选择合适的归一化方式。
✅ 建议:
- 如果你在训练 GAN、图像风格迁移模型,优先考虑 IN;
- 如果你在训练 CNN 分类模型,BN 是更稳妥的选择;
- batch size 很小时,BN 的效果可能不如 IN。