1. 简介
在本教程中,我们将讨论两种图搜索算法:深度优先搜索(DFS) 和 迭代加深搜索(Iterative Deepening, ID)。
两者都能用于图搜索,但适用场景和性能差异显著。我们将从完整性、最优性、时间与空间复杂度等多个维度进行对比,并通过一个具体示例说明为何 ID 在大多数情况下更优。
2. 图搜索基础
我们讨论的图是隐式图(implicit graph),即图的结构不是直接存储的,而是通过一个函数动态生成节点的子节点。我们的目标是从一个起点节点 s 出发,找到到目标节点 t 的最短路径。
2.1 假设条件
- 图的边是有向的,且无权重,路径长度等于边数。
- 节点之间通过函数
children(u)生成子节点。 - 判断一个节点是否为目标节点,由函数
target(u)决定。
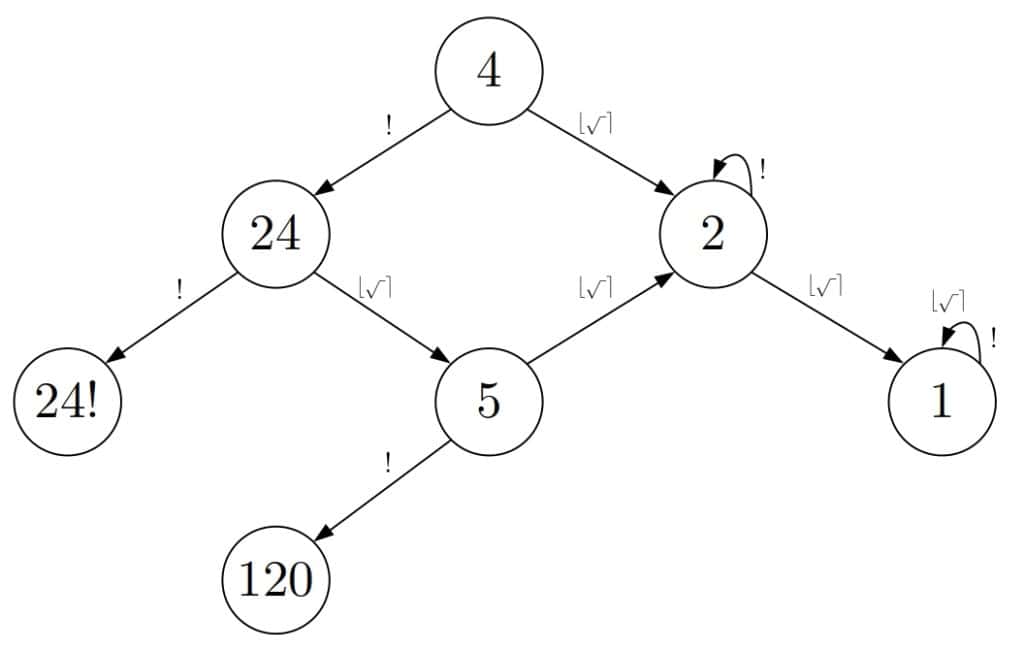
2.2 示例:Knuth 猜想
Knuth 曾提出一个猜想:所有正整数都可以通过对数字 4 应用有限次的平方根、取整和阶乘操作得到。
例如:
$$ 5 = \left\lfloor \sqrt{\sqrt{\sqrt{\sqrt{\sqrt{(4!)!}}}}} \right\rfloor $$
在这个图中:
- 节点是正实数
- 边表示应用操作后的结果(如平方根、阶乘、四舍五入)
- 起始节点是 4
- 目标节点是任意给定的正实数
r
下图展示了这个图的一部分:
3. 深度优先搜索(DFS)
DFS 从起点开始,优先探索当前节点的子节点,直到无法继续或找到目标节点为止。它通过递归或栈结构实现。
3.1 工作流程
- 如果当前节点是目标节点,返回路径。
- 否则,依次扩展子节点,递归探索。
- 若所有子节点都无法找到目标,回溯至上一节点。
3.2 示例
下图展示了 DFS 在数字图中的搜索路径:
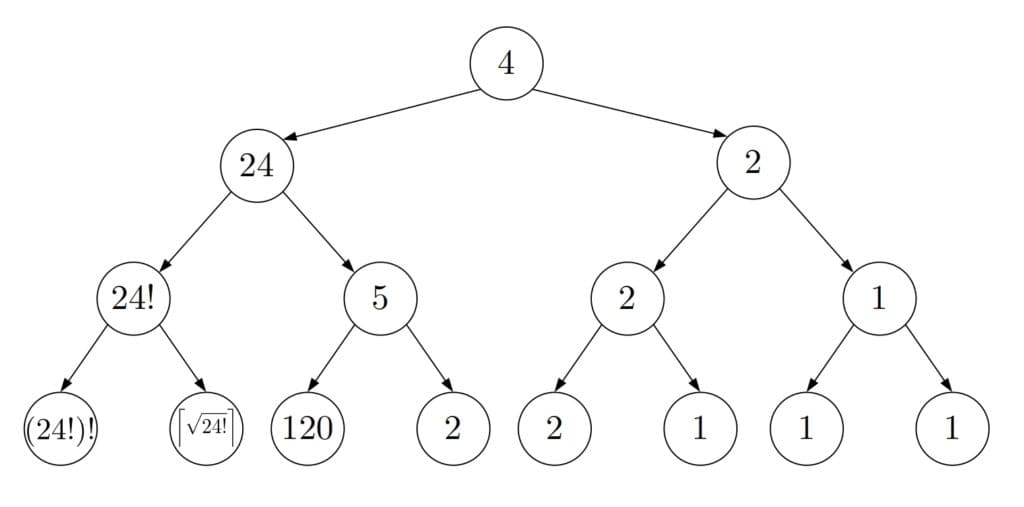
我们可以看到 DFS 会构建一棵搜索树,树的根是起点节点。
3.3 算法实现(递归版)
algorithm RecursiveDepthFirstSearch(u, target):
if target(u):
return [u]
for v in children(u):
path <- RecursiveDepthFirstSearch(v, target)
if path != empty set:
path <- prepend v to path
return path
return empty set
⚠️ 注意:DFS 有 Tree-Search(TSDFS)和 Graph-Search(GSDFS)两种实现方式。前者不记录已访问节点,可能陷入循环;后者通过记录已访问节点避免重复探索。
4. 迭代加深搜索(Iterative Deepening)
DFS 的两个主要问题:
- 可能找不到最短路径
- 可能陷入无限循环(即使使用 GSDFS)
Iterative Deepening(ID) 结合了 DFS 的空间效率和 BFS 的完备性与最优性。
4.1 深度限制 DFS(Depth-Limited DFS)
DLDFS 是 DFS 的一种变体,它限制了搜索的最大深度 ℓ:
- 若
ℓ >= d(d是目标节点的最短路径长度),DLDFS 可以找到最短路径 - 若
ℓ < d,DLDFS 无法找到目标 - 若没有目标节点,DLDFS 返回失败
algorithm DepthLimitedDFS(u, target, ℓ):
if target(u):
return [u]
else if ℓ = 0:
return CUTOFF
cutoff_occurred <- false
for v in children(u):
result <- DepthLimitedDFS(v, target, ℓ - 1)
if result = CUTOFF:
cutoff_occurred <- true
else if result != empty set:
result <- prepend v to result
return result
if cutoff_occurred:
return CUTOFF
else:
return empty set
4.2 ID 的工作原理
ID 依次尝试 ℓ = 0, 1, 2, ...,直到找到目标节点:
algorithm IterativeDeepening(s, target):
for ℓ <- 0, 1, ..., infinity:
result <- apply DLDFS with limit depth ℓ
if result != CUTOFF:
return result
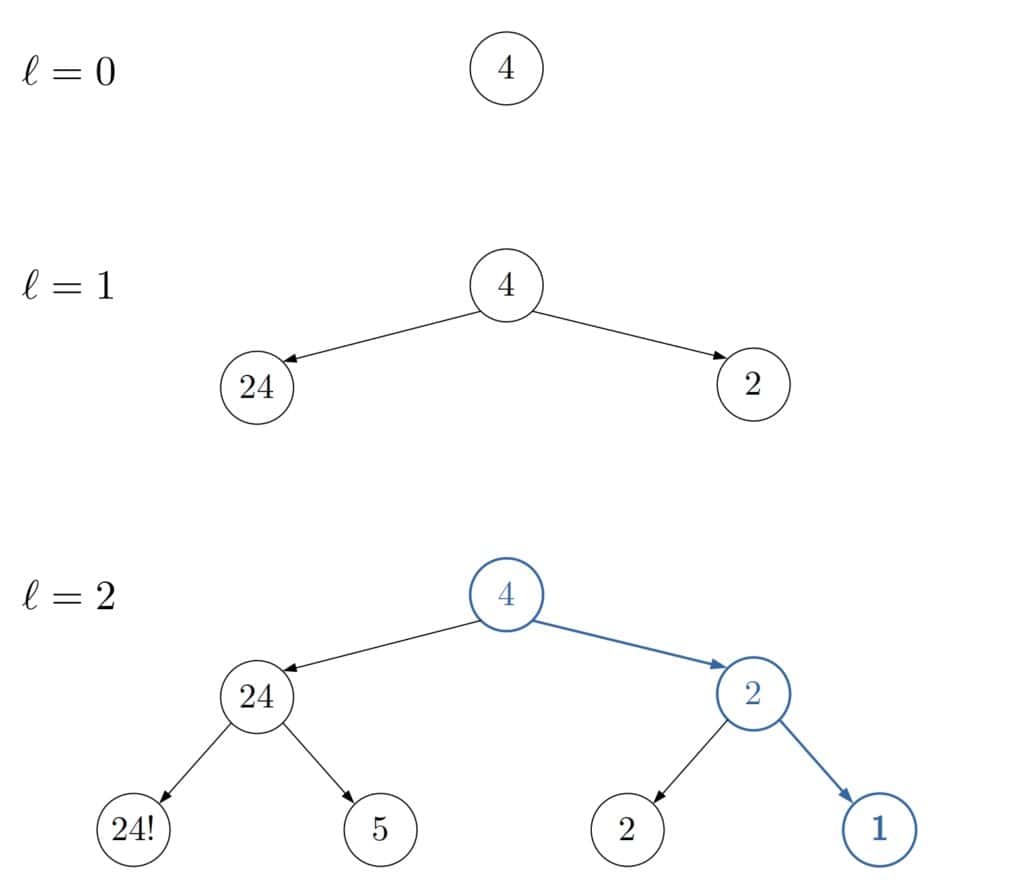
4.3 示例
以寻找数字 1 为例:
ℓ = 0: 仅检查起点 4ℓ = 1: 检查起点及其直接子节点ℓ = 2: 找到目标节点 1
下图展示了 ID 的搜索过程:
4.4 与 BFS 的比较
- BFS 是按层扩展节点,保证找到最短路径,但空间复杂度高(O(n))
- ID 通过反复调用 DLDFS 实现类似效果,空间复杂度仅为 O(bd),但节点可能被多次访问
4.5 随机化 DFS 是否可行?
虽然可以尝试通过随机化子节点顺序降低陷入无限循环的概率,但不能完全避免。DFS 仍可能陷入无限循环或返回非最优路径。
5. 算法对比分析
我们从以下维度比较 DFS 与 ID:
- 完备性(Completeness)
- 最优性(Optimality)
- 时间复杂度
- 空间复杂度
5.1 完备性与最优性
| 算法 | 完备性 | 最优性 |
|---|---|---|
| GSDFS | ✅(有限图) | ❌ |
| TSDFS | ❌ | ❌ |
| ID | ✅(节点子节点有限) | ✅ |
- GSDFS 在有限图中是完备的,但在无限图中可能无法终止
- TSDFS 可能陷入循环,无法保证完备性
- ID 在节点子节点数量有限的前提下是完备的,并能保证找到最短路径
5.2 时间复杂度
- GSDFS:O(n_V + n_E),其中 n_V 是节点数,n_E 是边数
- TSDFS:O(b^m),其中 b 是节点最大子节点数,m 是最长路径长度
- ID:O(b^d),其中 d 是最短路径长度
✅ ID 的时间复杂度优于 DFS,尤其在 b 较大的情况下,优势更明显
5.3 为什么 ID 不比 DFS 慢?
虽然 ID 会重复访问上层节点,但这些节点数量远少于底层节点。例如,若每个节点平均有 5 个子节点,那么最底层节点占总数的 80%,倒数第二层占 16%,只有 4% 的节点会被访问两次以上。
5.4 空间复杂度
| 算法 | 空间复杂度 |
|---|---|
| GSDFS | O(n_V) |
| TSDFS | O(bm) |
| ID | O(bd) |
✅ ID 的空间效率远高于 GSDFS,适合内存受限场景
5.5 总结对比表
| 标准 | GSDFS | TSDFS | ID |
|---|---|---|---|
| 完备性 | 有限图 | ❌ | ✅(b 有限) |
| 最优性 | ❌ | ❌ | ✅ |
| 时间复杂度 | O(n_V + n_E) | O(b^m) | O(b^d) |
| 空间复杂度 | O(n_V) | O(bm) | O(bd) |
6. 总结
本文对比了深度优先搜索(DFS)和迭代加深搜索(ID):
- DFS 虽然实现简单、空间效率高,但不保证找到最短路径,且在无限图中可能无法终止
- ID 通过不断加深搜索限制,结合了 DFS 的空间优势和 BFS 的完备性与最优性
- ID 的时间复杂度更低,空间占用更少,是大多数场景下的更优选择
- 当图的边带有权重时,应使用其他算法(如 Dijkstra、A*)
✅ 推荐使用 ID 的场景:
- 图是隐式的
- 需要找到最短路径
- 内存资源有限
- 图可能无限或非常大
❌ 不适合使用 ID 的场景:
- 图的边有权重
- 已知图的结构且可以使用 BFS
- 需要频繁访问图结构,且图较小