1. 简介
Kosaraju 算法是一种用于在有向图中寻找强连通分量(Strongly Connected Components, SCC)的经典算法。它结构清晰、易于实现,是图论中处理 SCC 问题的基础方法之一。
2. 强连通分量的定义
在有向图 G 中,顶点集合 V 和边集合 E 构成了图的基本结构。一个强连通分量是一个极大子集 S ⊆ V,满足以下两个条件:
✅ 互达性:S 中任意两个顶点 u 和 v 都可以通过有向路径互相到达
✅ 不可扩展性:向 S 中添加任何不在其中的顶点都会破坏互达性
任意非空有向图都至少包含一个 SCC,所有 SCC 构成了对 V 的一种划分(不重不漏)
示例图解
下图展示了一个最简单的图,每个顶点单独构成一个 SCC:
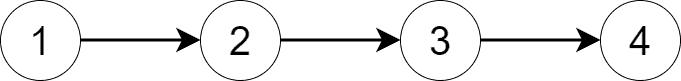
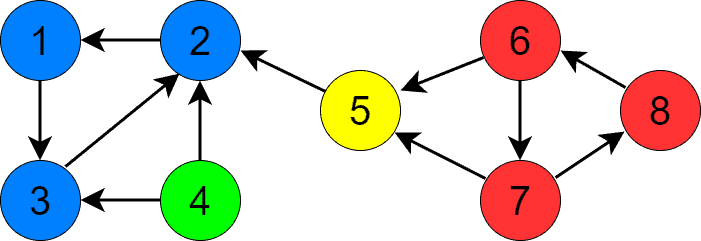
下图是一个更复杂的图:
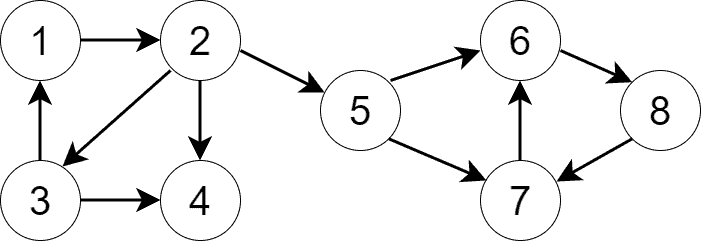
它包含 4 个 SCC,不同颜色代表不同 SCC:
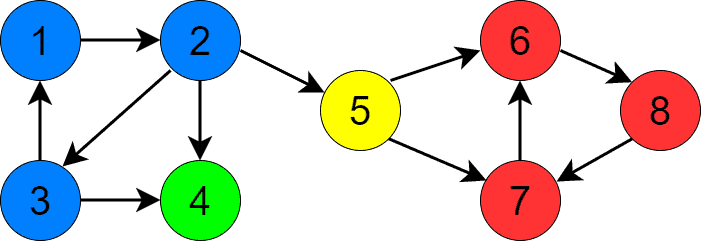
3. Kosaraju 算法详解
Kosaraju 算法分为三步:
3.1 第一步:DFS 求出顶点优先级
进行一次深度优先搜索(DFS),记录每个顶点完成访问的时间(exit time),根据完成时间倒序将顶点压入栈中。越晚完成的顶点优先级越高。
如下图所示,假设从顶点 1 开始 DFS,得到的优先级如下(红色数字):
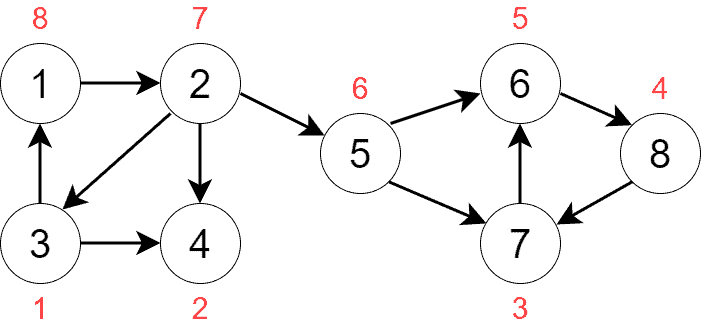
最终栈中顶点顺序为:[3, 4, 7, 8, 6, 5, 2, 1]
3.2 第二步:构建原图的转置图(Transpose Graph)
转置图是将原图中所有边的方向反转得到的新图。例如原图中有边 u → v,则转置图中有边 v → u。
下图是原图对应的转置图:
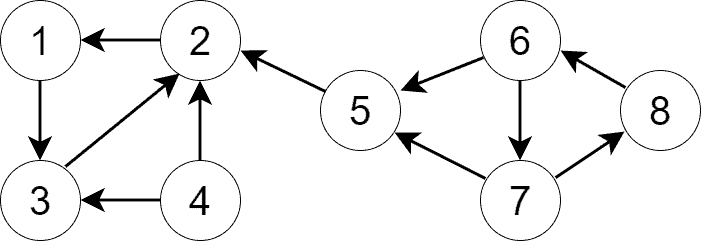
3.3 第三步:在转置图上按优先级进行 DFS
从栈顶开始取出顶点,在转置图上进行 DFS。每次 DFS 调用将找到一个完整的 SCC。
以下为每一步的执行过程:
从顶点 1 开始 DFS,找到 SCC {1, 2, 3}
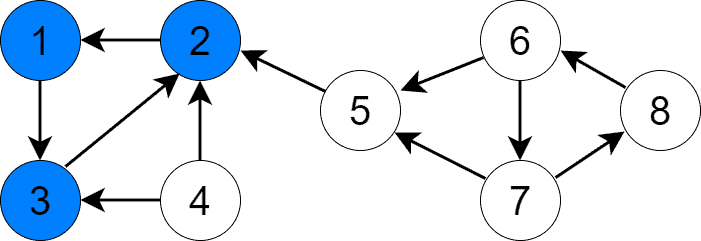
下一个优先级最高的是顶点 5,DFS 找到 SCC {5}
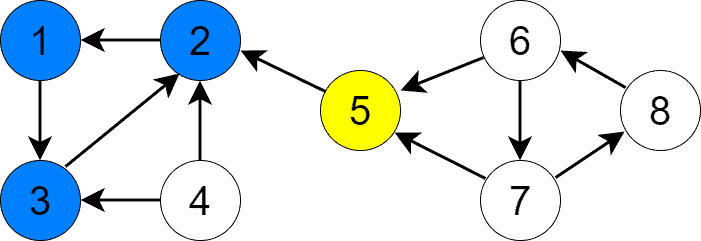
顶点 6 开始,找到 SCC {6, 7, 8}
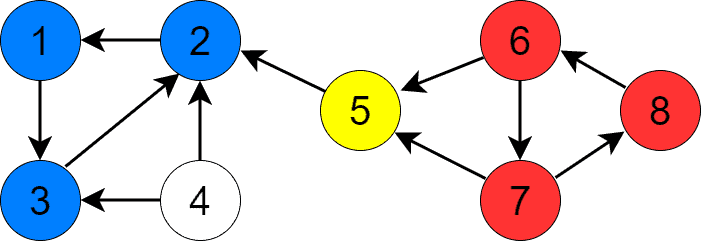
最后是顶点 4,找到 SCC {4}
4. 伪代码实现
基础 DFS
algorithm CommonDFS(G, v, visited):
visited[v] <- true
process vertex v
for u in G.neighbours[v]:
if visited[u] = false:
DFS(G, u, visited)
带优先级的 DFS
algorithm DFSWithVertexPriorities(G, v, priority, visited):
visited[v] <- true
for u in G.neighbours[v]:
if visited[u] = false:
DFSWithVertexPriorities(G, u, priority, visited)
priority.push(v)
构建转置图
algorithm TransformGraphCreation(G):
TG <- new graph with N vertices
for v in G.V:
for u in G.neighbours[v]:
TG.neighbours[u].add(v)
return TG
Kosaraju 主算法
algorithm KosarajusAlgorithm(G):
visited <- boolean array of size N initialized to false
priority <- stack for vertices
for v in G.V:
if visited[v] = false:
DFSWithVertexPriorities(G, v, priority, visited)
TG <- TransformGraphCreation(G)
Clear visited array
while priority is not empty:
v <- priority.pop()
if visited[v] = false:
CommonDFS(TG, v, visited)
process current SCC
5. 算法背后的原理
5.1 缩点图(Condensation Graph)
将每个 SCC 视为一个点,若原图中存在跨 SCC 的边,则缩点图中也存在对应边。缩点图是一个 DAG(无环有向图),如下图所示:
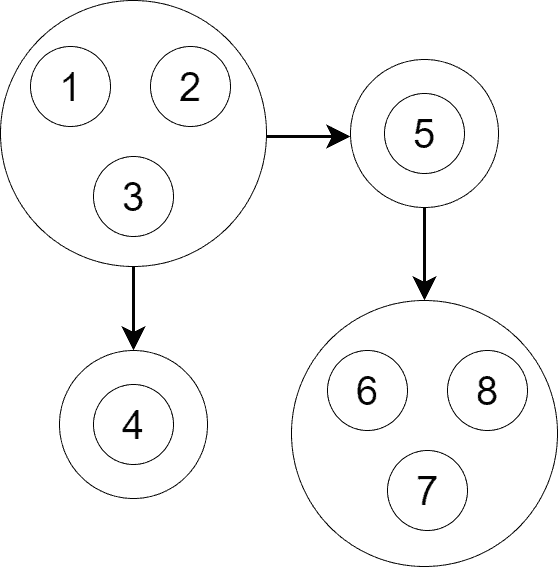
缩点图中每个点对应一个 SCC,边表示 SCC 之间的连接关系。
5.2 遍历顺序
缩点图是 DAG,可以进行拓扑排序。拓扑排序中 SCC2 在 SCC1 之后出现 ⇒ 步骤 1 中至少有一个 SCC1 的顶点优先级高于所有 SCC2 的顶点 ⇒ 步骤 3 中先处理 SCC1。
5.3 转置图的性质
转置图和原图有相同的 SCC。边只在 SCC 之间反转。步骤 3 中在转置图上按优先级 DFS,能保证每次 DFS 只访问当前 SCC 的顶点,不会“跑偏”。
6. 时间复杂度分析
使用邻接表表示图,Kosaraju 算法的时间复杂度为:
✅ O(N + M)
其中:
- 第一步 DFS:O(N + M)
- 构建转置图:O(N + M)
- 第三步 DFS:O(N + M)
7. 小结
Kosaraju 算法通过三次图遍历高效地找出所有强连通分量:
- 第一次 DFS 设置顶点优先级(exit time)
- 构建转置图
- 第二次 DFS 按优先级在转置图中查找 SCC
该算法结构清晰、易于实现,是图论中处理 SCC 问题的基础工具之一。在实际应用中,它常用于社交网络分析、依赖分析、编译优化等场景。
✅ 优点:逻辑清晰,实现简单
❌ 缺点:需要两次 DFS 和一次图反转操作,空间开销略高
⚠️ 注意:图必须是有向图,不适用于无向图(无向图的 SCC 等价于连通分量)