1. 概述
在本教程中,我们将讨论如何在一个经典问题中查找两个有序数组并集中的第 K 小元素。我们将从一个朴素解法入手,然后逐步优化,最终使用二分搜索方法实现更高效的算法。
文章末尾我们会对比两种方法的优劣,并说明何时更适合使用哪一种。
2. 问题定义
我们有两个数组:
- 数组 A(长度为 n)
- 数组 B(长度为 m)
它们都是升序排列的。我们还需要一个整数 k,要求找出 A 与 B 的合并有序数组 C中的第 k 小元素。
举个例子:
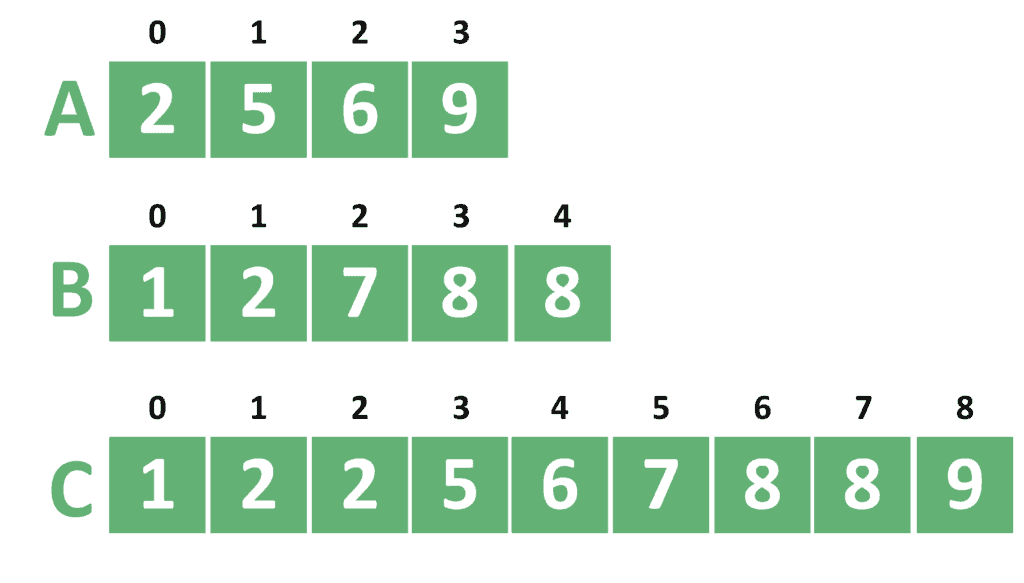
在这个例子中:
- A = [1, 3, 5, 7]
- B = [2, 4, 6, 8, 9]
- 合并后 C = [1, 2, 3, 4, 5, 6, 7, 8, 9]
当 k = 6 时,第 6 小的元素是 7。
3. 朴素解法
✅ 实现思路
我们可以模拟归并排序中“合并两个有序数组”的过程,逐步选出第 k 个元素。我们维护两个指针 i 和 j,分别指向 A 和 B 的当前元素。
每一步我们选择 A[i] 和 B[j] 中较小的那个作为当前最小值,并将对应指针前移。直到我们找到第 k 个最小值为止。
✅ 示例代码
algorithm NaiveApproach(A, B, n, m, k):
i <- 0
j <- 0
answer <- 0
while i + j < k:
if i = n:
answer <- B[j]
j <- j + 1
else if j = m:
answer <- A[i]
i <- i + 1
else if B[j] < A[i]:
answer <- B[j]
j <- j + 1
else:
answer <- A[i]
i <- i + 1
return answer
⚠️ 时间复杂度
- 时间复杂度:O(k)
- 最坏情况下 k = n + m,复杂度为 O(n + m)
❌ 缺点
虽然实现简单,但效率较低,尤其在 k 很大的时候。
4. 二分搜索解法
4.1 基本思想
我们希望利用二分搜索来加速查找过程。核心思路是:
- 在数组 A 中尝试选取 i 个元素,那么在数组 B 中就选取 j = k - i 个元素
- 检查当前 i 是否满足:A[i - 1] <= B[j] 且 B[j - 1] <= A[i]
如果满足,则说明我们已经找到一个合法的分割点,可以确定第 k 小元素的值。
4.2 实现代码
algorithm BinarySearchApproach(A, B, n, m, k):
bestI <- 0
L <- max(0, k - m)
R <- n
while L <= R:
mid <- (L + R) / 2
i <- mid
j <- k - i
if j = 0 or A[i - 1] > B[j - 1]:
R <- mid - 1
bestI <- mid
else:
L <- mid + 1
i <- bestI
j <- k - i
if i != 0:
return min(B[j], A[i - 1])
else:
return B[j - 1]
4.3 示例演示
以 A = [1, 3, 5, 7], B = [2, 4, 6, 8, 9], k = 6 为例:
- 第一步:mid = 2, i = 2, j = 4 → A[1] = 3 vs B[3] = 8 → 不满足
- 第二步:mid = 3, i = 3, j = 3 → A[2] = 5 vs B[2] = 6 → 不满足
- 第三步:mid = 4, i = 4, j = 2 → A[3] = 7 vs B[1] = 4 → 满足
最终返回 min(B[2], A[3]) = min(6, 7) = 6,结果正确。
✅ 时间复杂度
- 时间复杂度:**O(log n)**,其中 n 是数组 A 的长度
✅ 优势
- 比较次数大幅减少
- 特别适合 k 很大时使用
5. 两种方法对比
| 特性 | 朴素解法 | 二分搜索解法 |
|---|---|---|
| 实现难度 | ✅ 简单 | ⚠️ 稍复杂 |
| 时间复杂度 | O(k) | O(log n) |
| 适用场景 | k 较小 | k 较大 |
| 是否需要合并数组 | ❌ 不需要 | ❌ 不需要 |
✅ 如果 k < log n,建议使用朴素解法,因为常数更小,性能更优
✅ 如果 k 接近 n + m,建议使用二分搜索解法,效率更高
6. 总结
我们介绍了在两个有序数组的并集中查找第 k 小元素的问题:
- 首先使用了朴素解法,模拟归并过程,时间复杂度为 O(k)
- 然后使用二分搜索方法,将时间复杂度优化到 O(log n)
- 最后我们对比了两种方法的优劣,指出在不同场景下的选择策略
该问题在算法面试中较为常见,尤其是二分搜索的实现细节容易踩坑,建议多加练习。