1. 概述
在本文中,我们将研究线性回归(Linear Regression)与逻辑回归(Logistic Regression)的异同。
我们会先回顾回归分析的基本概念,再分别介绍线性回归与逻辑回归的数学表达、适用场景与模型特性。最后,我们会对比两者的核心差异,帮助你在实际项目中选择合适的模型。
2. 回归分析的基本思想
2.1 还原主义与统计推断
回归分析的哲学基础是“还原主义”(Reductionism),即认为复杂现象可以被拆解为多个变量之间的关系。这种思想广泛应用于科学研究,尤其是在统计建模中。
与之相对的是“涌现性”(Emergence),即系统整体行为无法通过其组成部分的行为来完全解释。回归分析适用于还原主义框架下的问题,而不适用于复杂系统的建模。
2.2 什么是回归?
“回归”一词最早由弗朗西斯·高尔顿(Francis Galton)提出,他发现高个子家族的后代身高会“回归”到平均值。这一观察催生了“回归分析”这一统计学分支。
现代回归分析用于从变量分布中提取简化关系,常用于建模、预测和因果分析。
2.3 回归模型的组成部分
回归模型通常包括以下要素:
- 因变量(Dependent Variable):我们试图预测或解释的变量
- 自变量(Independent Variables):用于预测因变量的特征
- 参数(Parameters):决定模型形状的系数
- 误差项(Error Term):表示模型与真实值之间的偏差
2.4 回归模型的一般形式
我们可以将回归模型形式化为:
y_i = f(α, X_i) + e_i
其中:
y_i是第 i 个观测的因变量X_i是第 i 个观测的自变量向量α是模型参数e_i是误差项
2.5 回归分析的局限性
⚠️ 回归分析不能证明因果关系。它只能帮助我们验证我们预先假设的因果关系是否存在统计显著性。
3. 线性回归(Linear Regression)
3.1 线性模型的基本公式
线性回归假设因变量 y 与自变量 x 之间存在线性关系:
y = a x + b
其中:
a是斜率(slope)b是截距(intercept)
当 a ≠ 0 时,模型有意义;若 a = 0,则 y = b,与 x 无关。
3.2 线性回归模型的构建
当模型无法完美拟合数据时,我们引入误差项:
y_i = a x_i + b + e_i
我们希望误差 e_i 尽可能小。通常使用最小二乘法(Least Squares)来优化模型参数,即最小化误差平方和:
E = Σ (y_i - (a x_i + b))^2
3.3 线性回归的求解方法
线性回归的参数可以通过以下公式求解:
斜率
a:a = Σ[(x_i - x̄)(y_i - ȳ)] / Σ(x_i - x̄)^2截距
b:b = ȳ - a x̄
其中 x̄ 和 ȳ 分别是 x 和 y 的均值。
3.4 线性回归的图形解释
线性回归模型本质上是一条直线,其斜率和截距决定了拟合效果:
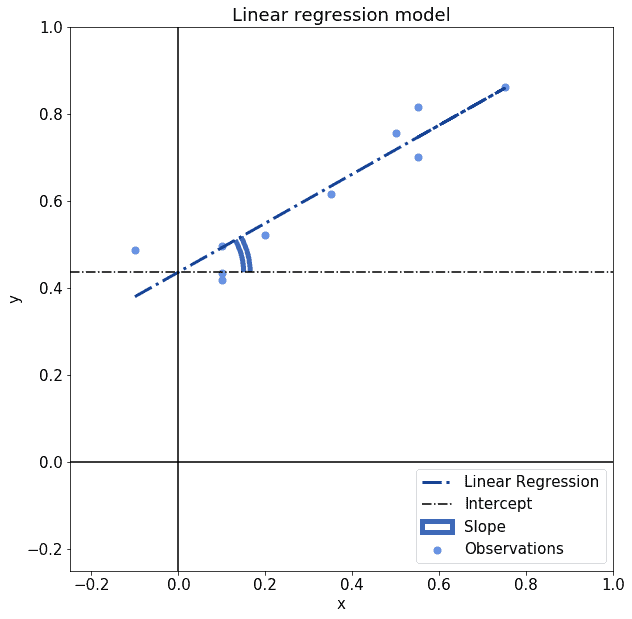
4. 逻辑回归(Logistic Regression)
4.1 逻辑函数(Sigmoid 函数)
逻辑回归使用的是 Sigmoid 函数:
σ(x) = 1 / (1 + e^(-x))
它的输出范围是 (0, 1),非常适合用于建模概率。
4.2 逻辑函数的特点
- 输出值在 (0, 1) 区间内,适合表示二元分类的概率
- 可将任意实数映射到 [0,1],常用于分类任务
- 在神经网络中也常用于激活函数(如 Sigmoid)
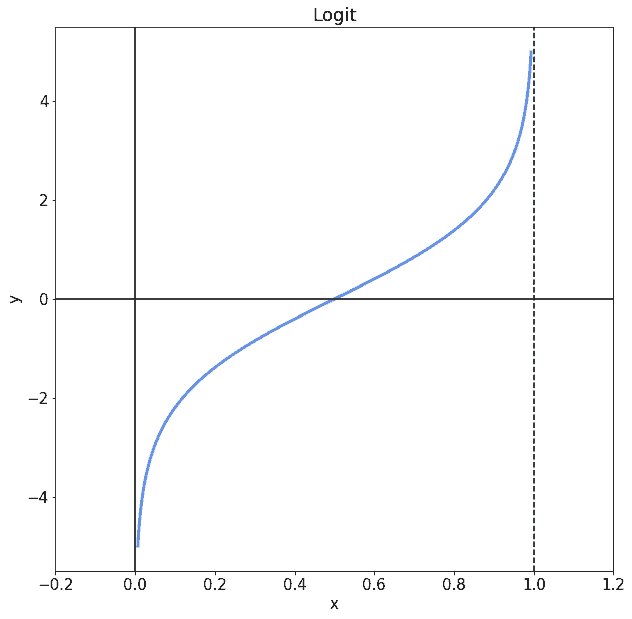
4.3 Logit 模型
Logit 是 Sigmoid 的反函数:
logit(p) = ln(p / (1 - p))
它将概率值映射回实数域,从而可以与线性模型结合使用:
logit(p) = a x + b
即:
p = σ(a x + b)
4.4 逻辑回归的参数估计
逻辑回归通常使用最大似然估计(Maximum Likelihood Estimation, MLE)来估计参数。目标是最大化似然函数:
L(A | y, x) = ∏ [σ(x_i)^y_i * (1 - σ(x_i))^(1 - y_i)]
为方便计算,取对数似然:
ln(L) = Σ [y_i ln(σ(x_i)) + (1 - y_i) ln(1 - σ(x_i))]
然后通过梯度下降等优化算法求解最优参数。
4.5 逻辑回归的分类机制
逻辑回归输出的是一个概率值。设定阈值(通常是 0.5)进行分类:
- 若 σ(a x + b) ≥ 0.5,则预测为类别 1
- 否则预测为类别 0
图示如下:
5. 线性回归 vs 逻辑回归:核心差异
| 对比维度 | 线性回归 | 逻辑回归 |
|---|---|---|
| 输出范围 | 实数域 ℝ | 区间 (0, 1) |
| 因变量类型 | 连续型 | 二元分类(0/1) |
| 模型函数 | 线性函数 y = a x + b | Sigmoid 函数 |
| 误差度量方式 | 最小二乘法(MSE) | 最大似然估计(MLE) |
| 优化方法 | 最小化误差平方和 | 梯度下降优化对数似然 |
| 典型应用场景 | 预测数值(如房价、温度) | 分类任务(如垃圾邮件识别、点击率预测) |
| 是否适合概率建模 | ❌ | ✅ |
6. 总结
✅ 线性回归适用于因变量为连续值的建模,强调数值预测。
✅ 逻辑回归适用于因变量为二元分类的建模,强调概率输出与分类决策。
两者都属于广义线性模型家族,但用途不同,模型结构也不同。选择时应根据任务类型、数据分布和输出需求综合判断。
📌 踩坑提醒:
- 不要混淆“回归”与“分类”任务,逻辑回归虽然名字带“回归”,但本质是分类模型。
- 线性回归不能直接用于分类,因为输出无界,逻辑回归更适合概率建模。
- 使用逻辑回归时注意特征标准化,有助于梯度下降收敛。