1. 概述
本文将讨论如何查找链表的交集。我们会先介绍几种查找两个链表交集的方法,再扩展到多个链表的情况。
最后,我们会对各种方法进行比较,总结它们的优缺点和适用场景。
2. 定义说明
链表交集指的是多个链表中共同元素的集合。例如:
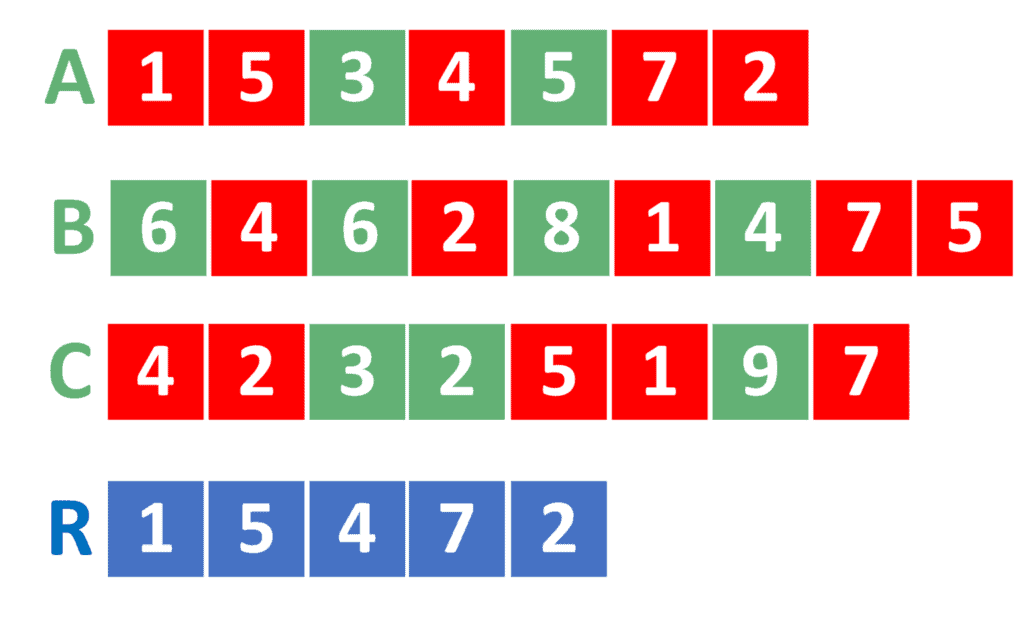
如上图所示,链表 A、B、C 的交集是 R,其中 R 包含的是三个链表中共有的元素(用红色标出)。
⚠️ 重复元素的处理规则:
如果某个值在 A 中出现 2 次,B 中出现 3 次,C 中出现 2 次,那么在交集中应保留该值的最小重复次数(即 2 次)。
3. 暴力法(Naive Approach)
✅ 核心思想
遍历第一个链表中的每个元素,检查它是否存在于第二个链表中。如果存在,则将其加入结果链表,并从第二个链表中删除一个该值。
✅ 示例代码
algorithm naiveIntersection(A, B):
R <- empty list
iter <- A.head
while iter != null:
if B.contains(iter.value):
R.add(iter.value)
B.erase(iter.value) // 仅删除第一个匹配项
iter <- iter.next
return R
⚠️ 时间复杂度
- **O(n × m)**:n 是 A 的长度,m 是 B 的长度
- 因为每次
contains()都是线性查找
⚠️ 缺点
- 性能差,尤其当链表较长时
- 会破坏原始链表结构(修改了 B)
4. 哈希映射法(Faster Approach)
✅ 核心思想
使用 TreeMap 或 HashMap 来记录 B 中每个值的出现次数,这样查找和删除操作都可以在 O(log n) 或 O(1) 时间内完成。
✅ 实现步骤
- 遍历 B,记录每个值的出现次数(存入 map)
- 遍历 A,如果当前值在 map 中且次数 > 0:
- 加入结果列表
- map 中该值的计数减一
✅ 示例代码
algorithm fasterIntersection(A, B):
map <- empty map with default value 0
iter <- B.head
while iter != null:
map[iter.value] <- map[iter.value] + 1
iter <- iter.next
R <- empty list
iter <- A.head
while iter != null:
if map[iter.value] > 0:
R.add(iter.value)
map[iter.value] <- map[iter.value] - 1
iter <- iter.next
return R
⚠️ 时间复杂度
- **O(n log m + m)**:使用 TreeMap 时
- **O(n + m)**:使用 HashMap 时(推荐)
⚠️ 建议
- 优先将较大的链表加入 map
- 因为查找时间比遍历时间快,所以大链表做 map 更划算
5. 特殊情况优化
5.1 小整数优化(Small Integers)
✅ 适用场景
当链表中元素为较小的整数时,可以用数组代替哈希表。
✅ 实现方式
- 创建大小为
MaxValue的数组代替 map - 初始化为 0
- 遍历 B 时,将值作为索引,对应位置自增
- 遍历 A 时,判断数组中该值是否 > 0
✅ 时间复杂度
- O(n + m + MaxValue)
⚠️ 注意事项
MaxValue要取两个链表中较小的那个最大值- 如果 A 中某个值大于
MaxValue,直接跳过
5.2 已排序链表优化(Sorted Lists)
✅ 适用场景
当两个链表都有序时,可以使用双指针法。
✅ 实现方式
- 使用两个指针分别遍历 A 和 B
- 如果当前值相等 → 加入结果,并同时移动两个指针
- 否则 → 移动较小值的指针
✅ 示例代码
algorithm sortedListsIntersection(A, B):
R <- empty list
aIter <- A.head
bIter <- B.head
while aIter != null and bIter != null:
if aIter.value < bIter.value:
aIter <- aIter.next
else if bIter.value < aIter.value:
bIter <- bIter.next
else:
R.add(aIter.value)
aIter <- aIter.next
bIter <- bIter.next
return R
⚠️ 时间复杂度
- O(n + m)
✅ 优点
- 不需要额外空间
- 时间效率高
6. 多个链表求交集
✅ 通用策略
- 先求前两个链表的交集
- 再与第三个求交集
- 依此类推
⚠️ 时间复杂度示例(排序链表)
- 三个链表长度分别为 n, m, k
- 总时间复杂度:O(n + m + k)
7. 方法对比总结
| 方法 | 时间复杂度 | 空间复杂度 | 使用场景 |
|---|---|---|---|
| 暴力法 | O(n × m) | O(1) | 通用,性能最差 |
| 哈希映射法 | O(n log m + m) 或 O(n + m) | O(m) | 通用,推荐使用 |
| 小整数优化 | O(n + m + MaxValue) | O(MaxValue) | 元素为小整数 |
| 已排序链表法 | O(n + m) | O(1) | 链表已排序时最优 |
✅ 推荐选择
- 通用场景:哈希映射法(HashMap)
- 已排序链表:双指针法
- 元素为小整数:小整数优化法
8. 总结
本文介绍了多种查找链表交集的方法,包括:
- 暴力法(性能最差)
- 哈希映射法(推荐通用方法)
- 小整数优化(适用于特定数据类型)
- 双指针法(适用于已排序链表)
并总结了如何将这些方法扩展到多个链表的交集计算中。最后通过表格对比了各方法的时间、空间复杂度及适用场景。
✅ 选择合适的方法可以显著提升性能,特别是在处理大数据量或特殊数据结构时更应谨慎选择算法。