1. Introduction
Large language models (LLMs) are a significant step forward in natural language processing and artificial intelligence. They can generate credible and contextually relevant text, translate languages, summarize documents, and even compose poetry. However, these systems face a problem: hallucinations.
In this tutorial, we’ll explain LLM hallucinations and examine their causes. We’ll cover aspects like the training data and the probabilistic nature of large language models. We’ll also discuss real-world grounding and mitigation strategies.
2. What Are Hallucinations?
Large language models can generate responses that seem logical or coherent but contain incorrect or inconsistent information. We refer to this phenomenon as a hallucination.
For example, a model might say something like, ‘Marseille is the capital of France.’ While this statement is false, it could sound perfectly plausible without checking with an external truth source.
For example, in response to a question about the health benefits of particular foods, the model would likely consult an internet source and communicate what it has learned. However, not every piece of online information is true or relevant. Our model could quickly obtain the wrong sources and give bad advice.
Another cause of such errors is that LLMs can misrepresent the context in which a prompt is presented. This can lead to a response that is contextually inappropriate or inaccurate.
3. Causes of Hallucinations in Large Language Models
We’ll review the main factors contributing to this issue. These include
- training data quality
- temporal limitations of data
- the probabilistic nature of large language models
- a lack of real-world understanding
- ambiguities and complex prompts
- overfitting
3.1. Training Data Issues
Large language models analyze vast quantities of textual data. The quality and accuracy of these data aren’t consistent. Some will be trustworthy, whereas other parts will be inaccurate, biased, or contradictory. However, LLMs absorb all these imperfections in the data. Consequently, they can generate incorrect texts.
3.2. Temporal Limitations of Data
The training dataset records available information in its original form at the time it was collected. As a result, models might produce responses based on outdated information.
For example, a model trained on data up to 2021 wouldn’t know about events from 2022 onward. If we ask an LLM for the latest information, it might hallucinate.
Let’s consider a digital educational tool running an LLM that supports students with history lessons. Let’s say the model was trained on a wide corpus of historical documents from different sources, some of which include narratives that were disputed after training. As a consequence, the model might reproduce wrong information to students.
3.3. Probabilistic Nature of Large Language Models
Text generation in all large language models is probabilistic. A model generates output text based on the likelihood of each word sequence. It can produce a text sequence that’s syntactically and contextually reasonable but inaccurate or incoherent.
Let’s consider a digital tutor for grammar exercises. It could generate grammatically sound sentences with appropriate contextual alignment. However, it might include minor errors causing ambiguities.
3.4. Lack of Real-World Understanding
LLMs lack real-world knowledge, and that can cause them to hallucinate and produce unrealistic answers.
For example, a model for improving young children’s literacy levels might challenge them with responses containing advanced vocabulary. The goal behind this is for children to learn complex words.
However, despite the logic of this idea, AI fails to account for developmental phases. In practice, educators must match the books and activities to each child’s reading ability to foster gradual progression.
3.5. Ambiguities and Complex Prompts
Given ambiguous input, an LLM might produce responses that seem reasonable but miss the intended meaning. This will result in inadequate and potentially inaccurate answers. The clearer the meaning of the input, the less likely the model is to produce misleading outputs.
For instance, when asked the question, “Can you recommend any splendid books?”, the model may provide a series of celebrated literary works. It might do this without taking into account what genre or age group specifically suits the user’s interests. Consequently, this approach will result in poor and potentially erroneous responses.
3.6. Overfitting to Specific Patterns
There’s also a risk of overfitting. An LLM might memorize phrases or facts in the training data and reproduce them in inadequate contexts.
Let’s say a model is trained to answer questions using old texts and quizzes. If it overfits the training data, it may not understand the context of new questions. Consequently, when presented with novel inquiries that require contextual interpretation, the model responses could prove misaligned with the student’s needs.
A student may ask, “What do I need to do to improve my essays?” The model’s response would likely consist of generic tips acquired through historical data. It will not take into account critical aspects specific to that learner’s challenges and skill level.
4. Mitigation Strategies
Some methods can help mitigate hallucinations in large language models.
4.1. Enhancing Training Data Quality
One of the most promising ways to control hallucinations is to use quality data for training. We should carefully curate datasets and process them to identify and correct errors.
Researchers and developers should use only reliable sources of information. Although checking a source’s trustworthiness can be laborious, it will increase the credibility of the training material.
In addition, we can use natural language processing (NLP) tools to find errors in the training data. These tools can find inconsistencies, biases, and mistakes. They can also flag areas that might need more or different data.
Machine learning algorithms such as Isolation Forest, Local Outlier Factor, and One-Class SVM can also be used to identify discrepancies between data points.
We can address biases with data augmentation and bias detection algorithms. Tools such as AI Fairness 360 and Google’s What-If tool can detect and quantify biases via statistical tests and metrics.
Similarly, adversarial training can be used to minimize biases. For example, a discriminator model can identify and penalize biased outputs during training.
4.2. Enhanced Model Architectures
Model architectures that allow systems to deal with ambiguity are part of the solution. They can also help to improve context.
One approach to improving model architecture is to create context-aware models. These models maintain an extended context, which gives them a better idea of a prompt’s true meaning.
In education, context-aware models enable adaptive learning environments. That means they can adjust the form of the educational materials depending on how students are performing and learning. Knowing the context of a student’s struggle, the model can adjust its responses. This ensures the student’s problem is addressed with explanations that fit their learning style.
4.3. Fact-Checking Mechanisms
We could introduce additional external fact-checking mechanisms. By letting models check their responses against outside sources of quality information, we can significantly reduce hallucinations.
For example, our tutoring system could check its answers with credible academic databases containing fact-checked solutions to math problems or discussions of scientific facts. Thus, the responses sent to the students would always be up-to-date and accurate.
4.4. Instruction-Tuning
A variant of instruction-tuning can facilitate the mitigation of hallucinations. It means providing clear and contextually relevant instructions to the LLM and specifying the intended response format.
The design of LLMs should incorporate features that ask for additional information in case of ambiguities. Subsequent user inputs can expand and rectify earlier responses.
For example, the LLM tutor can ask for additional details if a student doesn’t submit a clear question. Upon receiving the detailed context, the model can provide good explanations tailored to the student, taking into account the student’s current proficiency and specific problem.
4.5. User Feedback
If many users point to the same issue, we know where our model falls short and what to fix.
Systems to collect user feedback can give us some idea of how the model performs in the real world. This would involve building feedback mechanisms within apps that use large language models. For instance, a digital tutor might enable students to rate the quality of each answer or flag poor responses. Such feedback could assist in addressing common mistakes in model accuracy.
Using users’ feedback to improve the model implies continuously updating our model.
5. Mitigation Summary
Most strategies eliminate more than one cause of hallucinations:
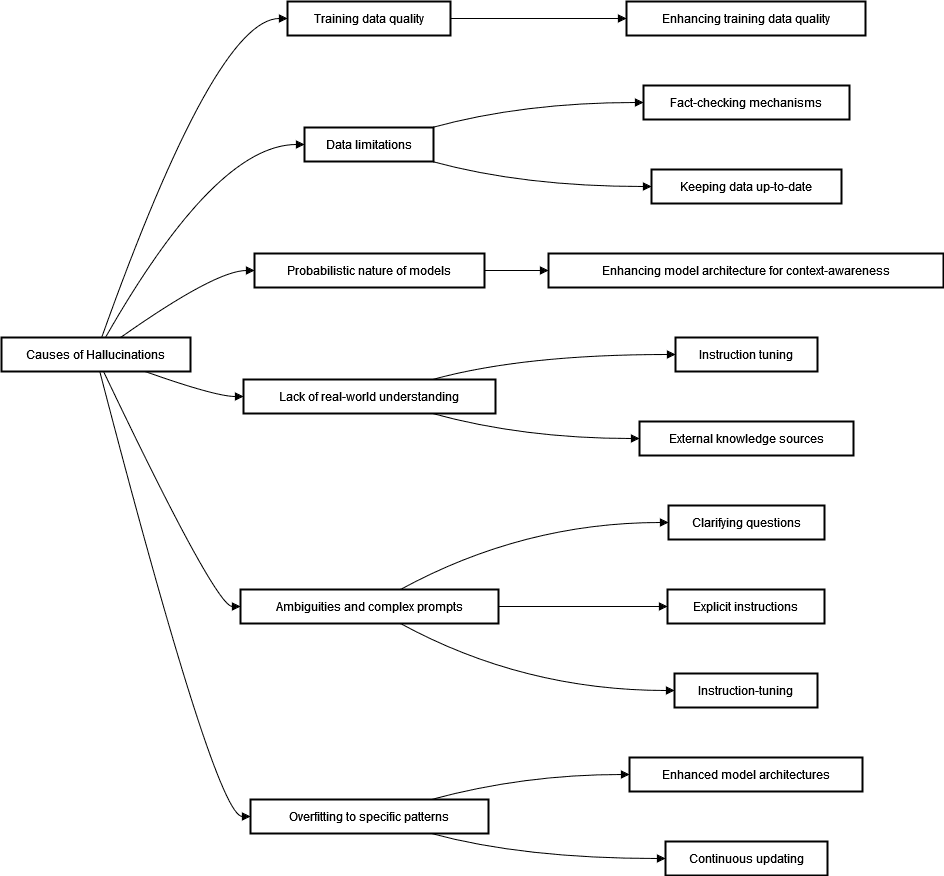
In practice, we’ll combine these strategies to achieve the best results.
6. Conclusion
In this article, we learned that hallucinations are a significant challenge in large language models. The inherent limits of the training data and model architecture cause this problem. Additionally, the models lack understanding of the real world.
To tackle these challenges, we need better training data, model architectures that handle ambiguities, and real-time fact-checking. Additionally, user feedback can help models evolve to make hallucinations less likely.