1. Introduction
In this tutorial, we’ll explain how to evaluate Retrieval-Augmented Generation (RAG) models using some popular metrics.
2. What Is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is a technique used in natural language processing (NLP) that combines retrieving relevant information from a large database with generating human-like text. This approach usually helps LLMs to improve the quality and accuracy of the generated response.
We can imagine a simple RAG model as an LLM chatbot on steroids. In most cases, it’s an LLM model enhanced with a custom database and retrieval system.
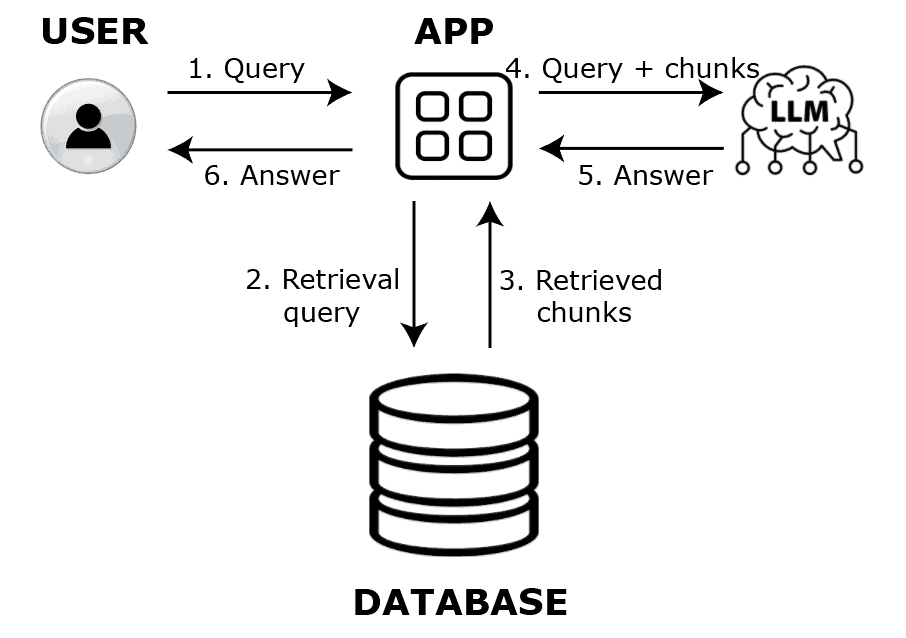
For example, imagine we have a database containing transcriptions of Joe Rogan’s podcasts. We want to develop a RAG system (chatbot) that mimics Joe Rogan’s style to answer questions. If someone asks the Joe Rogan chatbot about its thoughts on aliens, the retrieval system will search the database for relevant sentences or paragraphs, retrieve them, and send them along with the question to an LLM chatbot like ChatGPT or Gemini.
Using its knowledge, the retrieved information, and the initial question, the LLM will then generate a response:
3. What Are The Evaluation Metrics for RAGs?
To ensure that RAG models are functioning correctly, we need to monitor their performance. Some of the popular metrics that we can use to evaluate RAG models are:
- ROUGE score
- BLEU score
- METEOR score
- Personal Identifiable Information (PII)
- Hate speech, Abuse, and Profanity (HALF)
- Context relevance
- Hallucination
More about them we’ll explain below.
3.1. ROUGE Score for Evaluating RAG Models
ROUGE (recall-oriented understudy for gisting evaluation) score is a set of metrics that compares a response generated by the model with a group of expected responses generated by humans.
The comparison can be defined in several ways by measuring the overlap of n-grams, word sequences, or word pairs between the model response and expected responses. Besides RAG models, this metric is also popular for evaluating automatic summarization and machine translation systems.
3.2. BLEU Score for Evaluating RAG Models
BLEU (bilingual evaluation understudy) score is a metric that we can use to measure the precision of the model’s generated response, specifically focusing on individual words. Similar to the ROUGE score, the response generated by the model is compared with a group of expected responses.
The formula for the BLEU score is:
(1) 
where BP is the brevity penalty,  is the weight for each n-gram precision, and
is the weight for each n-gram precision, and  is the precision for n-grams. A more detailed explanation of this metric can be found in our article here.
is the precision for n-grams. A more detailed explanation of this metric can be found in our article here.
3.3. METEOR Score for Evaluating RAG Models
METEOR (metric for evaluation of translation with explicit ordering) is a metric originally created for the evaluation of machine-translation output. This metric provides a combined score of precision and recall, giving a more well-rounded view of model performance.
The formula of the METEOR score is:
(2) 
where  ,
,  is precision and
is precision and  recall between unigrams of generated and expected text. Also,
recall between unigrams of generated and expected text. Also,  , where
, where  is a number of chunks (adjacent unigrams) and
is a number of chunks (adjacent unigrams) and  is the number of unigrams in those chunks.
is the number of unigrams in those chunks.
To create chunks in generated and expected text, we need to follow several steps:
- Align the unigrams (words) between generated and expected text based on exact match, stemming, synonyms, and paraphrases
- Identify sequences of matched words that appear in the same order in both the generated and expected text. These sequences represent chunks. We need to identify the fewest possible number of chunks
- Count the number of matched chunks and words
For example, assume that our model generated the sentence “The quick brown dog jumps over the lazy fox” and the expected sentence is “The quick brown fox jumps over the lazy dog“. The fewest possible number of chunks is  (“The quick brown” and “jumps over the lazy”), and the number of unigrams in that chunk is
(“The quick brown” and “jumps over the lazy”), and the number of unigrams in that chunk is  .
.
3.4. PII Filter for Evaluating RAG Models
The personal identifiable information (PII) filter ensures the model doesn’t generate responses that include any information that can be used to identify an individual directly or indirectly. This includes sensitive information such as names, addresses, phone numbers, passport numbers, medical records, and similar.
3.5. HAP Filter for Evaluating RAG Models
The hate speech, Abuse, and Profanity (HAP) filter monitors the model for generating hateful or abusive language. More precisely, it includes:
- Hate speech – Expressions of hatred based on attributes such as race, religion, sexual orientation, disability, or gender.
- Abusive language – Rude language that is meant to bully, debase, or demean someone.
- Profanity – Toxic words such as expletives, insults, or sexually explicit language.
3.6. Context Relevance Criteria for Evaluating RAG Models
We need to ensure that our model creates relevant responses to our queries. This includes the relevance of retrieved documents to the query, the correctness and informativeness of the generated text, and the seamless integration of retrieved content into the response.
3.7. Hallucination Criteria for Evaluating RAG Models
We need to make sure that the model is not giving answers which are incorrect or misleading. Hallucination criteria involve assessing how often and to what extent the model produces information that is not supported by the retrieved documents or factual data.
4. Conclusion
In this article, we’ve explained some of the metrics and criteria that can be used for evaluating RAG models. To ensure the effectiveness, accuracy, and reliability of RAG models, we have to adjust and use some of the explained metrics.
Besides RAG models, these metrics can be used to evaluate other NLP systems such as LLM models, machine translation, summarization, and similar.