1. 引言
表面上看,马尔可夫链(Markov Chains, MC)和隐马尔可夫模型(Hidden Markov Models, HMM)非常相似。
我们将从两个角度来澄清它们之间的区别:
- 一是从数学角度出发,理解它们的结构差异;
- 二是从应用场景出发,看看它们各自适合解决什么类型的问题。
在此之前,我们先了解一个它们共有的基础概念:随机过程(Stochastic Process)。
2. 随机过程(Stochastic Processes)
简单来说,随机过程是一系列按索引排序的随机变量序列,例如:
$$ {x_0, x_1, \cdots, x_T} $$
这些变量是从某个概率分布中抽取的,因此被称为“随机”的。随机过程通常用于建模自然现象或过程。
举个例子,泊松点过程(Poisson Point Process)的定义如下:
$$ P(X = k) = \frac{\mu^k}{k!} e^{-\mu} $$
其中 $k \in {1, 2, \cdots, N}$ 表示事件发生的次数,$\mu$ 是该分布的期望值,即我们预期的平均事件发生次数。
这种随机过程适用于事件随机发生但具有平均发生率的场景,例如某个区域内的车祸数量、神经元的脉冲次数等。
在这些情况下,每个观察值之间互不影响,即概率分布是恒定的。但如果我们希望建模的是一个状态之间存在依赖关系的过程呢?
这就引出了马尔可夫链的概念。
3. 马尔可夫链(Markov Chains)
考虑一个离散系统,它可以处于 $N$ 个不同的状态之一:
$$ {x_1, x_2, \cdots, x_N} $$
每个状态都有一定概率转移到其他 $N-1$ 个状态。我们可以构建一个 转移矩阵(Transition Matrix),这是一个 $N\times N$ 的矩阵,表示从一个状态转移到另一个状态的概率。
假设我们观察了系统 $m$ 步,得到状态序列:
$$ {X_1, X_2, \cdots, X_m} $$
那么,下一步 $X_{m+1}$ 处于状态 $x_j$ 的概率是多少?
对于一个随机过程来说,如果它满足 马尔可夫性质(Markov Property),即下一个状态仅依赖于当前状态,而不是更早的状态,那么它就是一个马尔可夫模型:
$$ P(X_{m+1} = x_j\ |\ X_m, X_{m-1}, \cdots, X_1) = P(X_{m+1} = x_j\ |\ X_m) $$
3.1 应用场景
使用马尔可夫模型的前提是假设系统满足马尔可夫性质,并且系统本身是稳定的(转移矩阵不随时间变化)。
我们可以从两个方向来使用马尔可夫模型:
✅ 参数估计:根据已有的状态序列,使用最大似然估计(MLE)来估计转移矩阵的参数。
✅ 状态序列评估:已知转移矩阵参数,评估某状态序列出现的可能性。
示例:蚂蚁数量预测
假设我们观察一个盒子中蚂蚁的数量变化。每天我们统计某个小区域内的蚂蚁数量 $n(t)$。
我们假设蚂蚁数量每天最多增减 1,且满足马尔可夫性质。
转移概率定义如下:
$$ P(n(t+1) = n(t) + 1\ |\ n(t)) = \alpha \frac{N - n(t)}{N} \ P(n(t+1) = n(t) - 1\ |\ n(t)) = 1 - \alpha \frac{N - n(t)}{N} $$
这样我们只需要估计一个参数 $\alpha$,而不是 $N$ 个参数。
使用最大似然估计我们得到 $\alpha = 0.6$,并模拟了 20 条蚂蚁数量变化的轨迹,如下图所示:
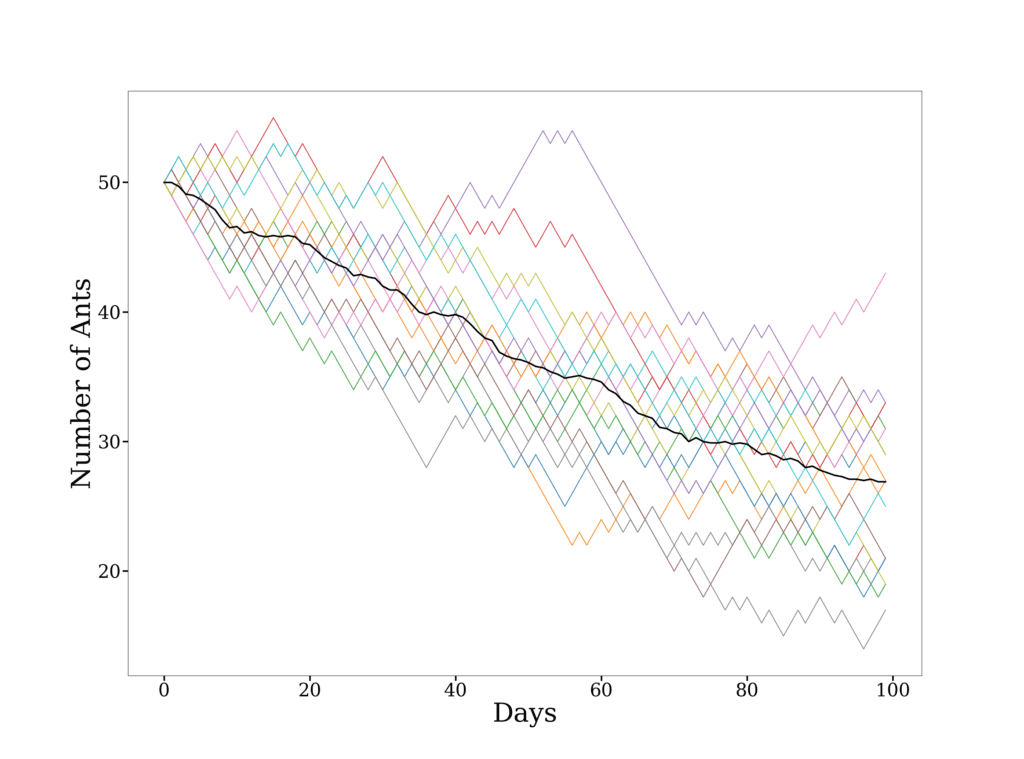
可以看出,蚂蚁逐渐倾向于避开该区域,这可能提示我们需要进一步调查原因。
虽然这个例子有些“幼稚”,但它很好地展示了马尔可夫链的实际应用价值。
⚠️ 扩展应用:在一些复杂系统中,直接获取概率分布困难,这时我们可以使用 马尔可夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC) 方法进行采样逼近。
4. 隐马尔可夫模型(Hidden Markov Models)
马尔可夫链的状态是可观测的,而隐马尔可夫模型的状态是不可见的,只能通过“观测”序列来间接推断隐藏状态序列。
也就是说,观测序列依赖于隐藏状态序列,但隐藏状态本身并不直接可见。
除了转移矩阵,HMM 还引入了 发射矩阵(Emission Matrix),它表示每个隐藏状态生成某个观测状态的概率。
参数数量分析
假设我们有 $N$ 个隐藏状态和 $M$ 个观测状态:
- 转移矩阵是一个 $N \times N$ 的矩阵,每个行和为 1,因此有 $N(N-1)$ 个参数;
- 发射矩阵是一个 $N \times M$ 的矩阵,同样每行和为 1,因此有 $N(M-1)$ 个参数;
- 总参数数为:$N^2 + NM - 2N$,即 $\mathcal{O}(N^2 + NM)$。
如果状态是向量而非标量,参数数量会进一步爆炸。
虽然动态规划算法(如前向算法)可以加速计算,但 HMM 通常只适用于隐藏状态较少的系统。
4.1 应用场景
HMM 更适合建模那些观测序列依赖于某些未知潜在因素的系统。
示例:蚂蚁行为识别
我们继续使用蚂蚁的例子:
- 观察到的是蚂蚁数量的变化;
- 但我们被告知蚂蚁有两个隐藏行为状态:偏向进入该区域(enter-biased)和偏向离开该区域(leave-biased);
- 观测状态变为:是否有蚂蚁进入(+1)或离开(-1)。
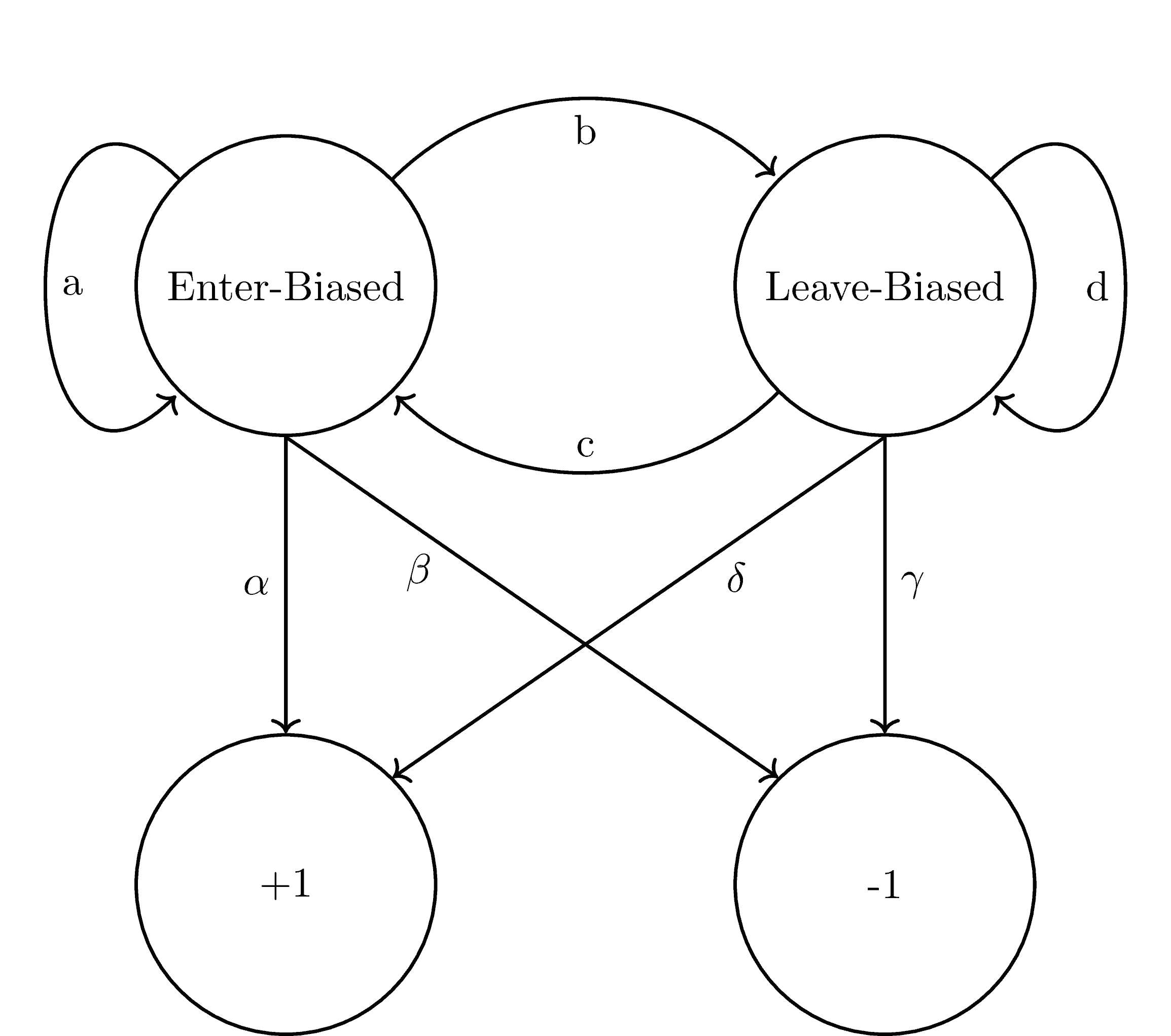
我们定义转移矩阵 $T$ 和发射矩阵 $E$ 如下:
$$ T = \begin{bmatrix} a & b \ c & d \end{bmatrix}, \quad E = \begin{bmatrix} \alpha & \beta \ \delta & \gamma \end{bmatrix} $$
图形表示如下:
使用 Baum-Welch 算法对 100 天的数据进行参数估计后,得到:
$$ T = \begin{bmatrix} 0.9 & 0.1 \ 0.1 & 0.9 \end{bmatrix}, \quad E = \begin{bmatrix} 0.8 & 0.2 \ 0.2 & 0.8 \end{bmatrix} $$
然后我们模拟轨迹如下:
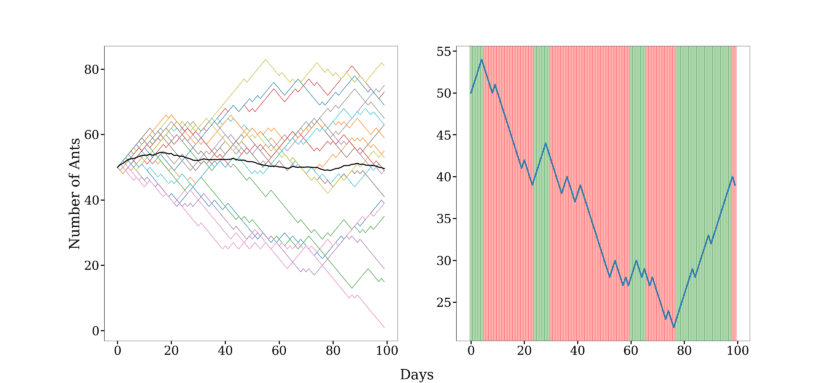
绿色表示进入倾向状态,红色表示离开倾向状态。可以看出,隐藏状态很好地解释了蚂蚁行为。
除了预测,我们还可以进行其他分析,如状态解码、参数学习等。
5. 总结
在本文中,我们:
- 介绍了随机过程的基本概念;
- 比较了马尔可夫链和隐马尔可夫模型的数学结构和应用场景;
- 使用蚂蚁数量变化的例子说明了它们在建模中的不同用途。
简要对比如下:
| 特性 | 马尔可夫链(MC) | 隐马尔可夫模型(HMM) |
|---|---|---|
| 状态是否可观测 | ✅ 是 | ❌ 否 |
| 是否有隐藏状态 | ❌ 无 | ✅ 有 |
| 参数数量 | $O(N)$ | $O(N^2 + NM)$ |
| 典型应用 | 状态预测、采样逼近 | 行为识别、语音识别、生物序列分析 |
两者都有广泛的应用,本文仅展示了基础概念和简单示例。实际应用中,它们的变体和扩展(如高阶马尔可夫模型、贝叶斯网络等)也十分丰富。