1. 简介
自编码器(Autoencoder)是一种强大的深度学习方法,主要用于预训练和生成模型,当然也有其他用途。基本的自编码器由两个部分组成:编码器(Encoder)和解码器(Decoder),它们分别学习数据的编码和解码过程。变分自编码器(VAE)是对传统自编码器的扩展,它改进了学习到的表示空间特性,而重参数化技巧(Reparameterization Trick)是实现这一改进的关键所在。
在本文中,我们将解释什么是重参数化技巧,为什么我们需要它,如何实现它,以及为什么它有效。我们会先快速回顾一下VAE的基本概念,然后解释VAE中为什么需要重参数化技巧,接着说明其原理和实现方式,最后从数学上进行形式化解释。
2. 变分自编码器(VAE)
VAE 是当前最流行、也是最基础的无监督学习结构之一。它在传统自编码器的基础上引入了概率建模的思想,使得学习到的表示空间更加连续、平滑。
2.1 自编码器回顾
自编码器通常由两个神经网络模块组成:
- 编码器:将输入数据映射到一个低维的嵌入空间(embedding space)中,得到一个向量表示。
- 解码器:将该向量还原为原始输入数据。
训练的目标是最小化原始输入与重构输出之间的差异。这种结构被称为“传统自编码器(Vanilla Autoencoder)”。
这种结构在图像重建等任务上表现良好,但存在一个关键问题:在编码空间中进行线性插值时,生成的结果往往并不理想。
2.2 传统自编码器的问题
传统自编码器的编码空间可能存在“断层”或“不连续”,导致两个编码之间的插值无法生成有意义的图像。
比如下图展示的是在二维编码空间中,对数字“2”和“9”之间的编码进行线性插值的结果:

可以看到,中间的过渡图像非常混乱,几乎无法识别。这说明传统自编码器的学习空间并不具备良好的连续性。
2.3 什么是 VAE?
VAE 由 Diederik P. Kingma 和 Max Welling 在 2013年的一篇论文 中提出,其核心思想是:不再直接输出编码向量,而是输出一个分布的参数(通常是高斯分布的均值 μ 和标准差 σ),然后从该分布中采样得到编码 z。
如下图所示:
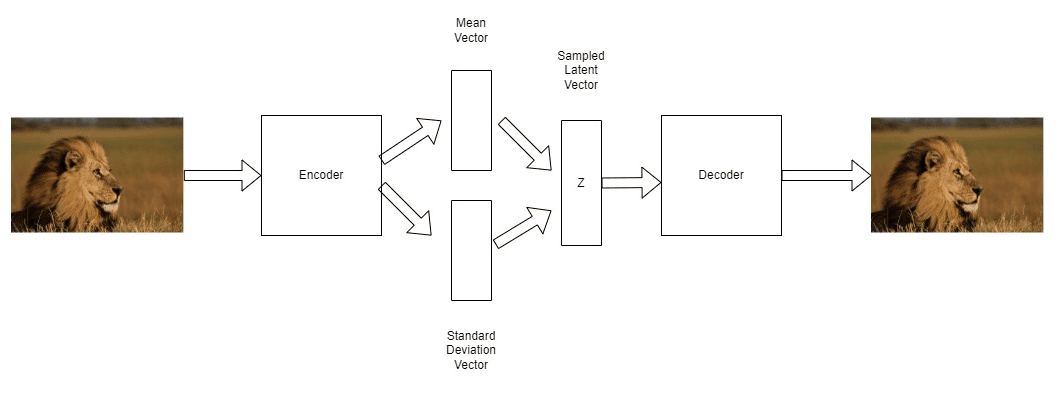
- 编码器输出两个向量:μ 和 σ。
- 根据这两个参数定义一个高斯分布。
- 从中采样得到 z。
- 然后使用解码器将 z 映射回原始数据。
这样做的好处是:学习到的编码空间更连续、更平滑,从而支持更好的插值效果。
2.4 VAE 的问题:采样不可导
VAE 的关键在于从分布中采样 z。但问题来了:这个采样操作本身是随机的,无法通过梯度反向传播来优化。
换句话说,如果我们直接使用采样操作,那么模型无法通过梯度下降来学习 μ 和 σ 的参数。这就需要引入“重参数化技巧”来解决这个问题。
3. 解决方案:重参数化技巧
3.1 什么是重参数化?
重参数化技巧的核心思想是:将采样操作从模型参数中分离出来,使得梯度可以流过模型。
具体来说,我们不再直接从参数化的分布中采样 z,而是:
- 先从标准正态分布中采样一个随机噪声 ε(均值为0,方差为1)。
- 然后通过模型预测的 μ 和 σ 来构造 z:
$$ z = \mu + \sigma \odot \epsilon $$
其中:
- μ 是编码器预测的均值;
- σ 是编码器预测的标准差;
- ε 是从标准正态分布中采样的噪声;
- ⊙ 表示逐元素相乘。
✅ 这样做之后,采样操作就变成了一个确定性操作(加上随机噪声),从而可以反向传播梯度。
3.2 重参数化的作用
- 保留随机性:ε 保证了 z 的随机性;
- 可导性:由于 μ 和 σ 是模型输出,且 ε 是外部输入的噪声,因此 z 的表达式是关于 μ 和 σ 的函数,可以求导;
- 提高训练稳定性:避免了直接对随机采样进行梯度更新带来的不稳定性。
下图展示了重参数化前后的模型结构差异:

- 左边是原始方式,梯度必须通过随机采样节点;
- 右边是重参数化方式,梯度通过确定性节点传播,噪声 ε 独立于模型参数。
4. 实现细节
在代码中实现重参数化非常简单。以下是一个典型的 PyTorch 实现片段:
def reparameterize(mu, log_var):
std = torch.exp(0.5 * log_var) # 从 log(σ²) 得到 σ
eps = torch.randn_like(std) # 从标准正态分布采样 ε
return mu + eps * std # z = μ + ε * σ
其中:
log_var是编码器输出的 log(σ²),这样可以避免 σ 为负数;torch.randn_like(std)生成与std形状相同的正态分布噪声;- 最后返回的
z就是重参数化后的编码。
✅ 这个函数在整个 VAE 的训练过程中被频繁调用,是整个模型可训练的关键。
5. 数学原理:为什么重参数化可行?
为了理解重参数化为何有效,我们需要从数学上推导其背后的原理。
我们希望对以下期望进行梯度计算:
$$ \nabla_{\theta} \mathbb{E}{x \sim p{\theta}(x)}[f(x)] $$
但由于 x 是从一个参数化的分布中采样出来的,直接对其求导是不可行的。
重参数化提供了一个替代方式:
- 引入一个外部的随机变量 ε,它服从一个固定的分布(如标准正态分布);
- 将 x 表示为 ε 的函数:$ x = g_{\theta}(\epsilon) $
- 这样,我们可以将期望重写为:
$$ \mathbb{E}{\epsilon \sim q(\epsilon)}[f(g{\theta}(\epsilon))] $$
然后对这个表达式进行梯度计算:
$$ \nabla_{\theta} \mathbb{E}{\epsilon \sim q(\epsilon)}[f(g{\theta}(\epsilon))] = \mathbb{E}{\epsilon \sim q(\epsilon)}[\nabla{\theta}f(g_{\theta}(\epsilon))] $$
✅ 这样就将随机性从模型参数中剥离出来,使得我们可以对模型参数进行优化。
6. 总结
- VAE 是一种强大的无监督学习模型,特别适用于生成任务;
- 重参数化技巧是 VAE 的核心机制之一,它解决了采样操作不可导的问题;
- 通过将随机性从模型参数中分离出来,我们可以在保持随机性的同时进行梯度反向传播;
- 该技巧不仅适用于 VAE,也可以推广到其他需要从分布中采样的模型中;
- 实现简单但效果显著,是深度生成模型中不可或缺的技术之一。
如果你在实现 VAE 或相关模型时遇到训练不稳定、无法收敛等问题,不妨检查一下是否正确应用了重参数化技巧。
✅ 踩坑提醒:
- 忘记对
log_var求指数会导致标准差为负数; - 使用
torch.randn_like(std)保证噪声维度一致; - 不要直接对
z做 detach,否则会断开梯度路径。
延伸阅读: