1.1. 支持向量机(SVM)简介
支持向量机(Support Vector Machine,SVM)是一种广泛应用于分类和回归任务的机器学习算法。其核心思想是通过寻找一个最优超平面(或决策边界)来最大化不同类别之间的边界(间隔),从而实现分类。
在二维空间中,这个最优边界是一条直线;在更高维空间中,则是一个超平面。SVM 的关键在于“支持向量” —— 那些距离决策边界最近的数据点,它们决定了分类器的形状和方向。
1.2. 支持向量的作用
支持向量是 SVM 分类器的“骨架”。它们是训练过程中保留下来的关键样本,用于定义决策边界。其他样本在分类器训练完成后可以被丢弃。
支持向量的数量对模型的复杂度和泛化能力有直接影响:
- ✅ 支持向量少:模型更简单,训练和预测速度快,但可能泛化能力差
- ✅ 支持向量多:模型更复杂,分类边界更精细,但训练成本高、预测速度慢
1.3. 线性可分情况下的 SVM 表现
如下图所示,这是一个线性可分的问题。此时,SVM 使用线性核可以轻松找到最优分类边界:

在该例子中,所有样本都成为支持向量,准确率达到最大值。这说明:
- ✅ 当数据完全线性可分时,支持向量数量可能等于样本总数
- ⚠️ 但这种情况在实际问题中并不常见
1.4. 样本数量增加时的情况
随着样本数量增加,我们可能不再希望分类边界严格地将所有类别分开:

此时,我们需要在以下两者之间做出权衡:
- ✅ 更复杂的决策边界:使用更多支持向量,提升准确率
- ❌ 更简单的边界:减少支持向量数量,牺牲部分准确率
2. 具体实验分析
2.1. 数据集准备与初步分析
我们以经典的 Iris 数据集为例进行实验。该数据集包含三类鸢尾花,每类有 50 个样本,每个样本包含 4 个特征。
我们选取其中两个特征进行可视化分析:
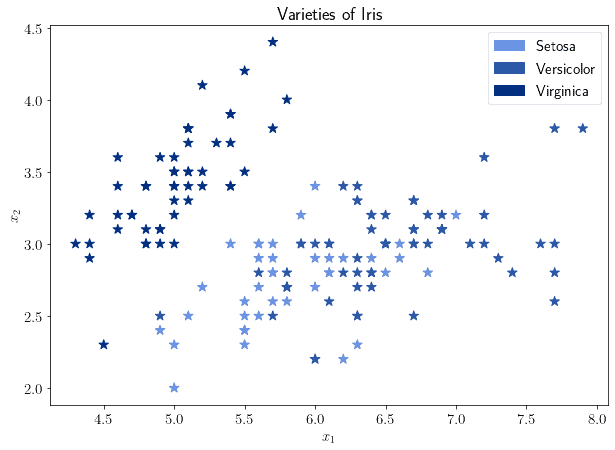
观察发现:
- 一类样本与其他两类明显分离
- 另两类存在重叠区域
这提示我们:使用线性核 SVM 可能无法很好地区分后两类,除非引入软间隔(soft margin)机制。
2.2. 使用线性核 SVM
我们首先尝试使用线性核 SVM,正则化参数设为默认值 C=1:
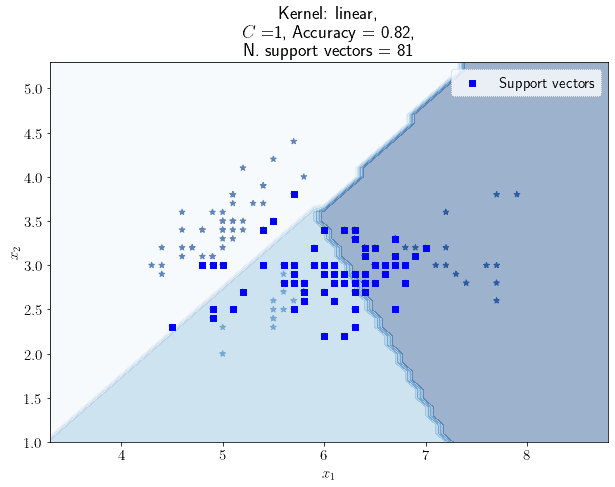
结果如下:
- ✅ 使用了 81 个支持向量
- ✅ 准确率为 0.82(使用 Jaccard 相似度评分)
2.3. 调整正则化参数 C
正则化参数 C 控制模型对误分类的容忍程度:
- ❗
C越小:正则化越强,容忍更多误分类,支持向量数量增加 - ❗
C越大:正则化越弱,要求更严格的分类,支持向量数量减少
情况一:C=0.1
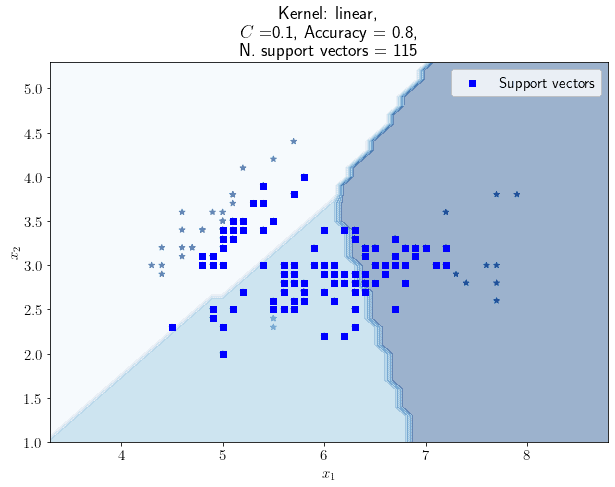
- ✅ 支持向量增加到 115 个
- ❌ 准确率下降到 0.80
情况二:C=10
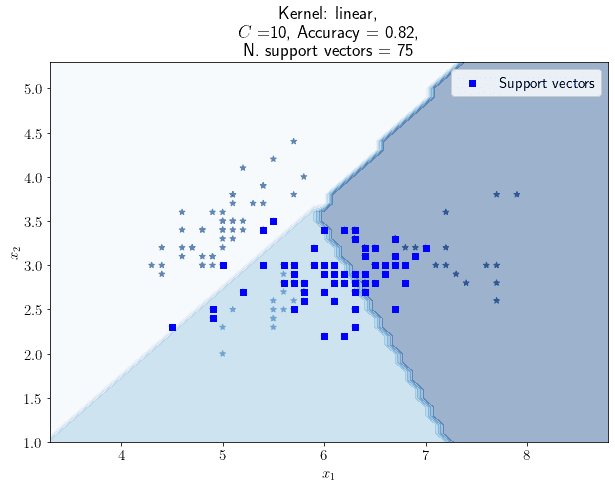
- ✅ 支持向量减少到 75 个
- ✅ 准确率保持为 0.82
2.4. 支持向量数量与准确率的关系
我们测试了 C 在区间 [0.01, 10) 内的所有值,采样步长为 0.01,得到如下趋势图:
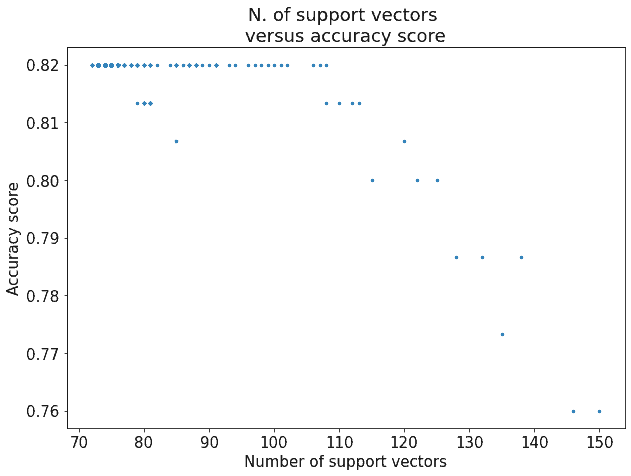
观察发现:
- ✅ 准确率始终无法突破 0.82
- ✅ 支持向量超过约 110 个后,准确率不再显著提升
这说明:
- ❗ 当问题本身非线性可分时,增加支持向量数量并不能持续提升准确率
2.5. 使用非线性核 SVM
考虑到数据存在重叠区域,我们改用多项式核(degree=3)SVM:
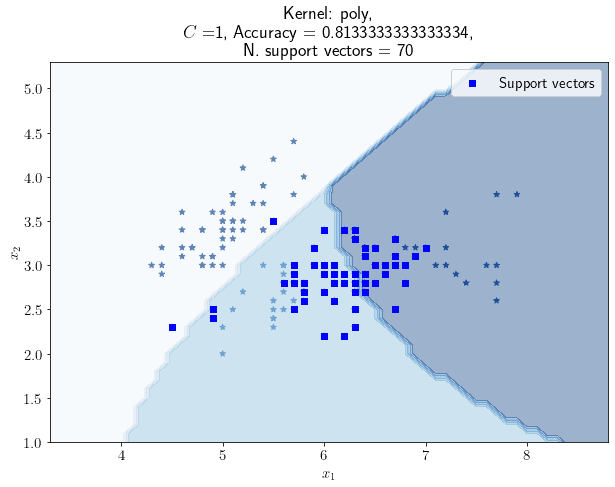
测试不同 C 值后得到如下趋势图:
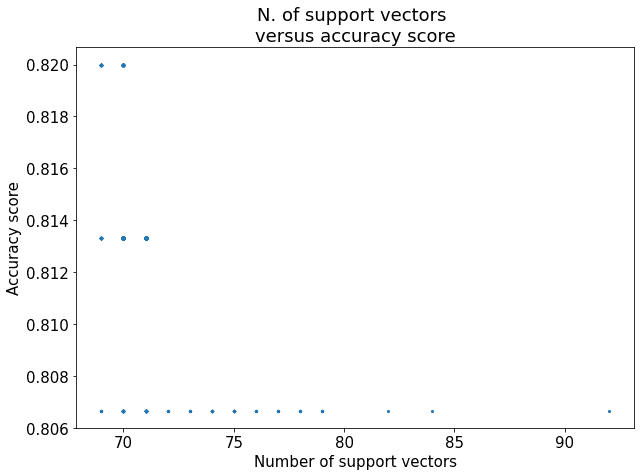
观察发现:
- ✅ 非线性核最低准确率高于线性核
- ✅ 非线性核总体表现更优
2.6. 支持向量最少时的准确率表现
我们进一步分析非线性核在支持向量数量最少时的表现:
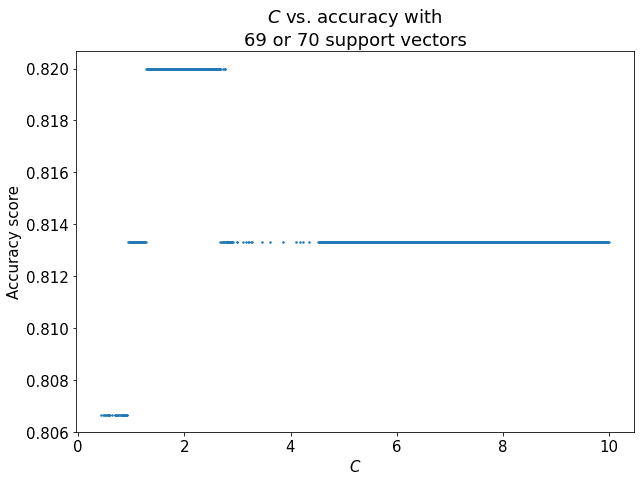
观察发现:
- ✅ 当支持向量数量为 69 或 70 时,准确率达到最大值 0.82
- ✅ 此时
C ≈ 2为最佳参数配置
2.7. 线性核 vs 非线性核对比
将线性核与非线性核的结果进行对比:
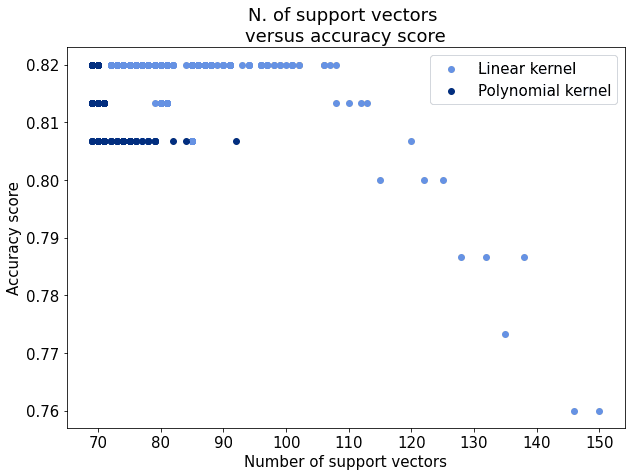
总结如下:
- ✅ 非线性核整体更准确
- ✅ 非线性核所需支持向量更少
- ✅ 非线性核更适合该数据集
2.8. 方法的通用性
上述分析方法不仅适用于 Iris 数据集,也适用于其他分类问题。核心步骤如下:
- ✅ 选择合适的核函数(线性 or 非线性)
- ✅ 调整正则化参数
C - ✅ 分析支持向量数量与准确率的关系
- ✅ 找到最佳权衡点
对于更复杂的问题,建议使用自动化超参数调优方法,如网格搜索(Grid Search)等。
3. 结论
本文探讨了支持向量数量与 SVM 分类器性能之间的关系:
- ✅ 支持向量是决定分类边界的关键样本
- ✅ 支持向量数量与准确率之间存在权衡关系
- ✅ 当问题非线性可分时,非线性核 SVM 表现更优
- ✅ 通过调整正则化参数
C可控制支持向量数量 - ✅ 最佳参数配置应兼顾准确率与模型复杂度
在实际应用中,建议根据具体问题特性选择合适的核函数和正则化参数,以达到最优性能与效率的平衡。