1. Overview
In this tutorial, we’ll explore how to prevent, avoid, detect, and ignore deadlock with practical examples.
2. Introduction to Deadlock
A deadlock can occur in almost any situation where processes share resources. It can happen in any computing environment, but it is widespread in distributed systems, where multiple processes operate on different resources.
In this situation, one process may be waiting for a resource already held by another process. Deadlock is similar to a chicken and egg problem.
Let’s see an example of deadlock:
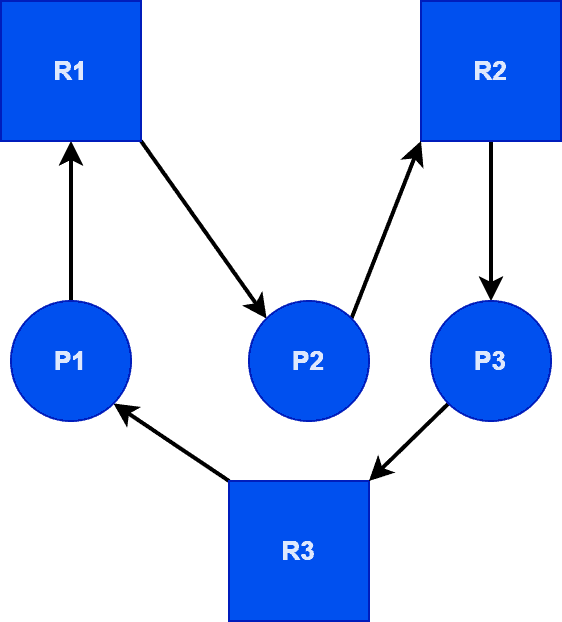
Suppose there are three processes, P1, P2, and P3, and three resources, R1, R2, and R3.
Now, suppose P1 requests a resource R2, which is held by P2. In such a case, P1 won’t proceed without R2 and will wait indefinitely because P2 can’t release resource 2 until it gets R3, which P3 holds. The same is true for P1 and P3. Thus, it’s an ideal example of a deadlock situation in OS.
3. Necessary Conditions for Deadlock
Deadlock can arise if the following four conditions hold simultaneously:
The first condition is mutual exclusion. In this condition, we can’t share a resource among the different processes at the same time.
For example, if two people want to print a paper simultaneously, this process can not be done. One has to wait until the system releases the print (resource). Thus, we can assign a resource to only one process at a time.
The second necessary condition for deadlock is the hold and wait or resource holding. In this condition, a process simultaneously holds at least one resource and waits for another resource at a time. Here, the process is not in the running state. It’s in a waiting state.
The third condition is no preemption. If a process holds a resource, then the resource can not be taken away forcefully from the process until it releases the resource. This statement also holds when the process is in a waiting state.
The final condition for deadlock is the circular wait. Let’s assume the process P1 is waiting for a resource R2. Now that particular resource R2 is already held by a process P2. Process P2 is waiting for the resource, held by the next process. This will continue until the last process is waiting for the resource held by the first process.
The circular wait condition creates a circular chain and puts all the processes in a waiting state.
4. Deadlock Prevention
In the deadlock prevention process, the OS will prevent the deadlock from occurring by avoiding any one of the four conditions that caused the deadlock. If the OS can avoid any of the necessary conditions, a deadlock will not occur.
4.1. No Mutual Exclusion
It means more than one process can have access to a single resource at the same time. It’s impossible because if multiple processes access the same resource simultaneously, there will be chaos. Additionally, no process will be completed. So this is not feasible. Hence, the OS can’t avoid mutual exclusion.
Let’s take a practical example to understand this issue. Jack and Jones share a bowl of soup. Both of them want to drink the soup from the same bowl and use a single spoon simultaneously, which is not feasible.
4.2. No Hold and Wait
To avoid the hold and wait, there are many ways to acquire all the required resources before starting the execution. But this is also not feasible because a process will use a single resource at a time. Here, the resource utilization will be very less.
Before starting the execution, the process does not know how many resources would be required to complete it. In addition to that, the bus time, in which a process will complete and free the resource, is also unknown.
Another way is if a process is holding a resource and wants to have additional resources, then it must free the acquired resources. This way, we can avoid the hold and wait condition, but it can result in starvation.
4.3. Removal of No Preemption
One of the reasons that cause the deadlock is the no preemption. It means the CPU can’t take acquired resources from any process forcefully even though that process is in a waiting state. If we can remove the no preemption and forcefully take resources from a waiting process, we can avoid the deadlock. This is an implementable logic to avoid deadlock.
For example, it’s like taking the bowl from Jones and give it to Jack when he comes to have soup. Let’s assume Jones came first and acquired a resource and went into the waiting state. Now when Jack came, the caterer took the bowl from Jones forcefully and told him not to hold the bowl if you are in a waiting state.
4.4. Removal of Circular Wait
In the circular wait, two processes are stuck in the waiting state for the resources which have been held by each other. To avoid the circular wait, we assign a numerical integer value to all resources, and a process has to access the resource in increasing or decreasing order.
If the process acquires resources in increasing order, it’ll only have access to the new additional resource if that resource has a higher integer value. And if that resource has a lesser integer value, it must free the acquired resource before taking the new resource and vice-versa for decreasing order.
For example, the caterer assigned an integer value to the bowl and the spoon as 1 and 2, respectively, so that one can have access to the resource in increasing order. Now, if Jones has a bowl, then he can have the spoon. But as Jack has a spoon with a greater integer value, he must leave the spoon first and then take the bowl. Thereafter, he will get the spoon to have the soup.
5. Deadlock Avoidance
Deadlock avoidance methods help the OS to avoid the occurrence of deadlock. The OS will maintain a log of the maximum required resources needed for a process in the whole life cycle before starting the execution. The OS will continually check the system’s state before allocating any newly requested resource to any process.
Basically, in the deadlock avoidance, the OS will try not to be in cyclic wait condition. If the OS can allocate all the requested resources to the process without causing the deadlock in the future, that is known as a safe state. And if the OS can’t allocate all the requested resources without causing the deadlock in the future, that is known as an unsafe state.
5.1. Resource Allocation Graph (RAG) Algorithm
Using RAG, it’s possible to predict the occurrence of deadlock in an OS.
The resource allocation graph is the pictorial view of all allocated resources, available resources, and OS’s current state. We can figure out how many resources are allocated to each process and how many resources will be needed in the future. Thus, we can easily avoid the deadlock.
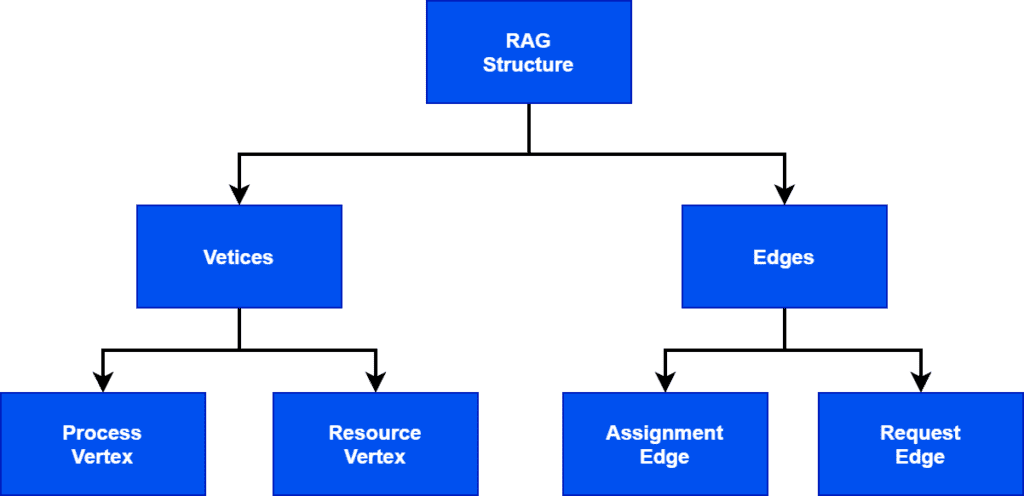
As every graph has vertices and edges, in the same way, RAG also has vertices and edges. RAG has two vertices: process vertex and resource vertex, and two edges: assignment edge and request edge. Mostly, we represent vertices with a rectangular shape and edges with a circular shape:
There is a limitation with the RAG algorithm that it’ll only work if all the resources have a single instance. If there is more than one instance of a resource, it’ll not be certain in determining the deadlock. There will be the possibility of forming the circle, but it may lead to a deadlock. So, in that situation, we use the Banker’s algorithm to determine the deadlock.
For example, let two processes P1, P2, and two resources R1, R2:
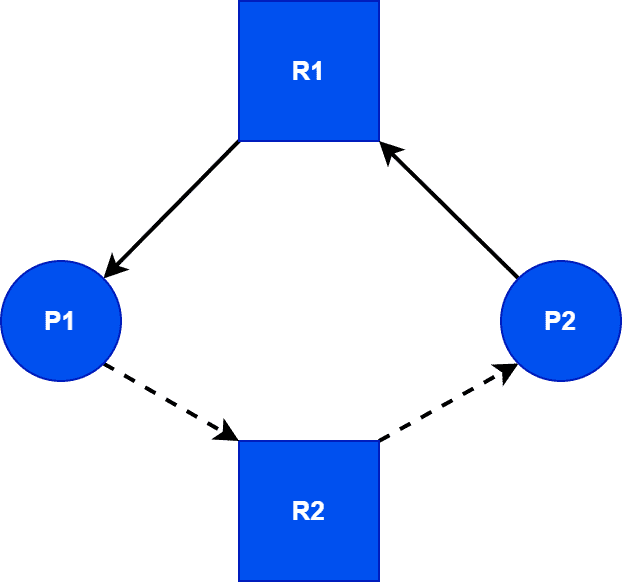
Here, P1 uses R1, and it’ll use R2 in the future, denoted as a dotted line. At the current time, it’s free. P2 is requesting R2, but OS will not allocate that, as it’ll be needed for P1 later. So it’ll avoid the formation of a circle. Thus, it avoids the probability of deadlock occurrence. But from the above solution, R2 will not be in use. Hence, resource utilization will be less.
5.2. Banker’s Algorithm
When resources have multiple instances, we use the Banker’s algorithm. It is known as the Banker’s algorithm because banks follow it to manage the resources in such a manner so that they’ll never be out of resources and avoid getting into an unsafe state. Banks use this algorithm before allocating or sanctioning any loan in the banking system.
In this algorithm, we need some predetermined data, such as the maximum required resources from each process to complete the life cycle and the total available resources in the OS. From that data, it’ll make a safe sequence. If the OS runs all the processes in that sequence, it’ll avoid the occurrence of deadlock.
This algorithm maintains a matrix of total available resources, maximum required resources for each process, total allocated resources to each process, and currently required resources.
6. Deadlock Detection and Avoidance
In this method, the OS assumes that a deadlock will occur in the future. So it runs a deadlock detection mechanism with a certain interval of time, and when it detects the deadlock, it starts a recovery approach.
The main task of the OS is to detect the deadlock. There’re two methods of detection which we’ve already covered before.
Here, we use the same methods with some improvisations:
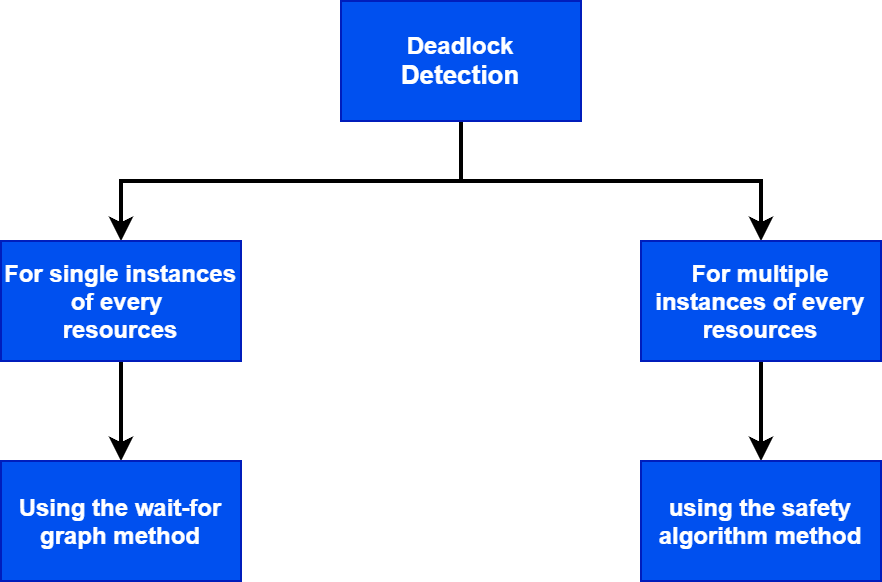
In the wait-for graph method, the OS checks the formation of a circle. It’s somehow the same as the resource allocation graph (RAG) with some differences. Mostly it causes confusion between the RAG and Wait-for graph.
The main difference between a RAG and a wait-for graph is the number of vertices each graph contains. A RAG graph has two vertices: resource and process. A wait-for graph has one vertex: process.
We can also create a wait-for graph using a RAG:
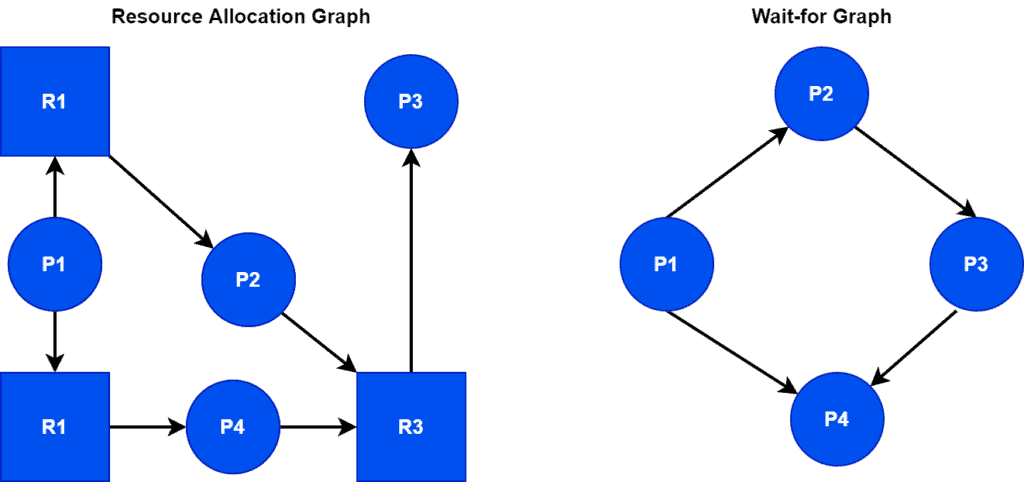
The wait-for graph is not making a circle, which means it’ll not lead the system to a deadlock.
For multiple instance resources, we use the Safety algorithm, which uses the same approach as the Banker’s algorithm. But it doesn’t have a maximum required resource matrix. It has only three matrices: allocated, available, and current requirement matrix.
Now, as soon as the OS detects a deadlock, it’ll start the recovery method. There are two main approaches to recover from a deadlock:
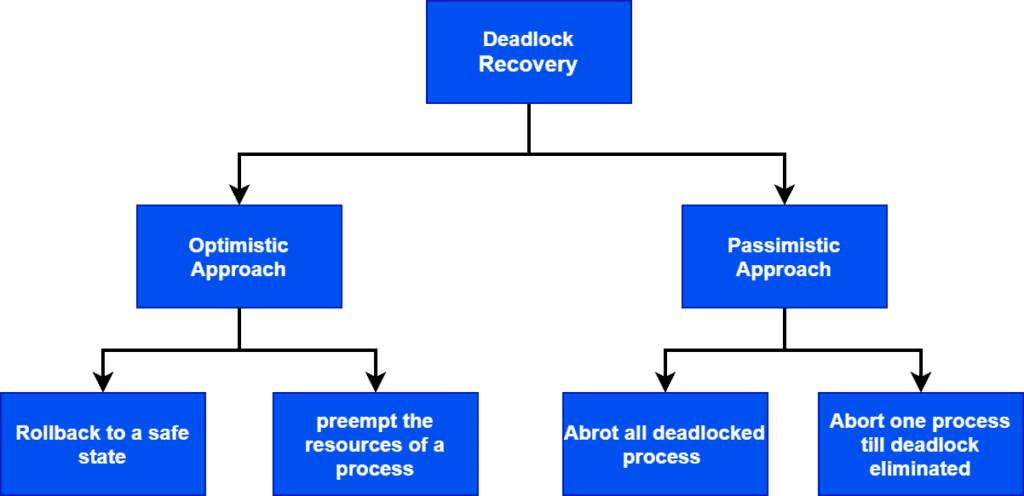
6.1. Optimist Approach
An example of the optimist approach is the resource and process preemption. In this approach, the OS will select some processes and preempt their resources, thereafter allocate them to other processes. Thus, the OS will try to break the circle.
One disadvantage of this approach is there is a possibility that the same process may become the victim of preemption. In this condition, the process will be stuck in starvation.
Another approach in which the OS will roll back to a certain safe state where deadlock hasn’t occurred. But for this, OS has to maintain some logs up to which it was in a safe state.
One of the disadvantages of this method is that there is no decision parameter to select the order of the rollback of the processes.
6.2. Pessimist Approach
One pessimist approach is to abort all the deadlocked processes. This is the simplest way of breaking the cycle to recover from the deadlock, but it’s also the most costly way of handling deadlock. In this method, we kill all the processes, and the OS will either discard them or restart a portion of the processes later as per requirement.
Also, we can abort the one process at a time till we eliminate deadlock from the system.
In this method, the OS kills one process at a time, and it selects the process which has done the least work. After that, it runs the deadlock detection algorithm to verify if the deadlock is recovered. If it is not recovered, then it will keep killing the processes till the deadlock is eliminated.
7. Deadlock Ignorance
This is one of the widely used methods to handle the deadlock. In this method, the OS assumes that deadlock will never occur. If there is a condition of deadlock, the OS will reboot the system. This method is very popular where OS is for the end-users.
Deadlock ignorance approaches are used in Linux and Windows-based OS where users are directly in contact with the system.
8. Conclusion
In this tutorial, we discussed the concept of deadlock in OS thoroughly. We presented an example to illustrate the idea behind deadlock in OS.
Furthermore, we explored various approaches to prevent, avoid, detect, and ignore deadlock.