1. 概述
本文将探讨如何以可计算的方式表示知识。通过这一过程,我们将推导出一种构建知识图谱的方法。
我们还将讨论知识库、专家系统与知识图谱之间的关系,以及它们如何相互作用。
阅读完本文后,你将熟悉专家系统的理论基础、符号主义AI开发方法,并掌握从知识库构建知识图谱的必要流程。
2. 世界表示的问题
2.1 知识、贝叶斯先验与世界表示
要构建知识图谱,首先要理解“知识”在这里的定义。
在数据标注的文章中我们曾提到,任何AI系统都嵌入了一组关于世界运作方式的假设,这些假设通常是(但并非总是)硬编码的。这些假设构成了系统的贝叶斯先验,使推理成为可能。
从另一个角度看,这些先验就是系统所“知道”的内容。系统必须对世界有所了解,才能在其中运作。最基本的假设之一是:“存在对象”。
这些对象属于我们可以用符号表示的类别。这些类别共同构成了一个本体论或分类体系,从而简化原本过于复杂的环境。
智能体本体的复杂性,也反映了其外部世界的复杂性。更复杂的环境需要更复杂的本体来引导智能体行为,反之亦然。
2.2 没有表示就没有分类
基于这些假设和知识,系统能够处理从环境中接收到的数据并做出决策。例如,系统可以根据预定义的分类体系识别环境中的对象:
机器学习系统中编码的原始知识通常来源于编写该系统的程序员。基于这些知识,系统可以执行进一步操作,扩展其对环境的理解。如果没有这些先验知识,系统将无法学习新内容或执行任何操作:
通常,智能体所拥有的知识集合称为知识库。而知识图谱就是一种用于存储这些知识的结构。我们正是在这一背景下研究知识图谱——作为AI智能体世界表示的数据结构。
3. 知识编码
3.1 命题知识
系统所拥有的知识可以以多种形式存在。本文我们聚焦于一种与符号推理相关的知识,称为命题知识。
命题知识是以逻辑命题形式表达的知识。例如:


这些语句本身是空的,因为尚未为其赋予具体内容。
命题知识的内容是通过符号(如词语)编码的,我们设想这些符号之间通过“主谓宾”关系连接。这种关系是编码知识句子的必要组成部分。这类句子称为陈述句,包含关于世界的事实。
以下是一些不包含知识的句子示例:
- Get over here as soon as possible(命令句,非陈述句)
- Did you visit the museum?(疑问句,非陈述句)
- I'm surprised!(感叹句,非陈述句)
以下是几个命题知识的例子,后续部分将围绕这些例子展开:
- 地球绕着太阳转
- 奶牛产奶
- 柠檬是黄色的
3.2 三元组知识
我们可以进一步拆解这些命题,提取出实体及其关系:
- “地球”和“太阳”之间通过“绕着”连接
- “奶牛”和“牛奶”之间通过“产”连接
- “柠檬”和“黄色”之间通过“是”连接
一些神经网络可以自动完成这一任务。命名实体识别(NER)是一个独立的课题,本文不做深入讨论。我们只需假设存在一种“魔法方式”可以从句子中提取名词并识别它们之间的关系。
如果我们对上述三个命题执行提取操作,可以得到如下结构:
- 地球(主语)绕着(谓语)太阳(宾语)
- 奶牛(主语)产(谓语)牛奶(宾语)
- 柠檬(主语)是(谓语)黄色(宾语)
我们也可以将这些命题表示为三元组,顺序为:主语、宾语、谓语。有些作者使用“主语-谓语-宾语”的顺序,这也合理;关键是保持一致性。我们偏好这种顺序是因为它更符合知识图谱中边的定义。
将上述句子转换为三元组如下:
- (地球, 太阳, 绕着)
- (奶牛, 牛奶, 产)
- (柠檬, 黄色, 是)
这些三元组的信息内容与自然语言句子相同,但此时内容以可计算格式表达,我们可以对其进行操作。
3.3 三元组拼接与推理
我们可以将这些三元组用于推理。通过拼接,可以生成新的三元组,包含原始命题中未包含的知识。
以苏格拉底的死亡为例:
- 苏格拉底是人
- 人是会死的
转换为三元组:
- (苏格拉底, 人, 是)
- (人, 死亡, 是)
注意到第一个三元组的宾语(第二项)是第二个三元组的主语(第一项),因此可以拼接:
- 苏格拉底是人是死亡
这意味着三元组(Socrates, mortal, is)也成立。最终我们扩展了三元组集合:
- (苏格拉底, 人, 是)
- (人, 死亡, 是)
- (苏格拉底, 死亡, 是)
我们通过逻辑操作生成了新知识。注意,这种推理无需理解“苏格拉底”、“人类”或“死亡”的实际含义。
4. 专家系统与知识库
4.1 专家系统
以可计算格式存储知识并对知识进行操作的系统称为专家系统。该名称源于它们像某个领域专家一样运作。
由于缺乏专业知识,开发人员常需咨询领域专家,将他们的知识转换为逻辑命题,这也是“专家系统”名称的由来。
专家系统体现了符号主义AI的发展路径,最早可追溯到1950年代。如今这些系统仍在使用,但由于需要手动编码知识,扩展性较差。
这推动了从非结构化文本中自动提取语义关系技术的发展。这些提取出的关系构成了现代专家系统中的知识图谱。
4.2 知识库
我们可以为知识库下一个定义:知识库是专家系统所持有的知识、信息和数据的总和。
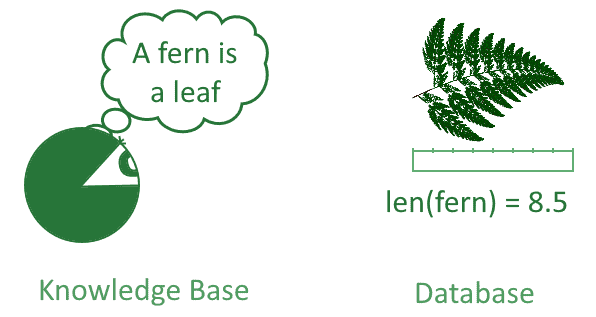
知识库不同于数据库。数据库包含的是测量或观察结果,这些数据仅在产生它们的观察中有意义。而知识库包含的是普遍适用的规则。
从这个意义上说,知识库更像科学家所掌握的理论知识,而非测量数据:
你可以在各种信息管理系统中找到知识库,最著名的可能是Google的知识图谱侧边栏:
这个侧边栏被称为Google知识图谱,但实际上它是一个完整的知识库,而不仅仅是图。目前,Google知识图谱可能是世界上最大的知识库。也有人认为互联网才是最大的知识库,但这会带来一个悖论:世界上最庞大的知识库中大部分内容是猫和表情包。
4.3 知识库的非命题组成部分
最后一点需要注意的是,现实世界中的知识库并不只包含命题知识。它们通常还整合了关系型和层次型数据库,以及分析这些数据的程序。
但为了本文目的,我们假设知识库仅由知识命题构成。这有助于突出图谱边与知识库命题之间的有趣关系。
5. 图结构表示知识
5.1 从三元组到多层图
现在我们来构建一个与知识库中命题知识相对应的知识图谱。
知识图谱是有向多层图,其邻接矩阵对应于知识库中三元组的内容。我们可以通过以下方式从知识库构建知识图谱。
首先,从一个包含三元组集合的知识库开始。本节使用一个小型天文知识库为例:
- (地球, 行星, is_a)
- (太阳, 恒星, is_a)
- (行星, 恒星, 绕着)
- (行星, 圆形, is_a)
该知识库包含四个三元组,映射了两种关系:is_a 和 绕着,涉及五个实体:地球、太阳、行星、恒星和圆形。is_a 是知识库中表示类属关系的常见方式。绕着则无需解释。
5.2 构建知识图谱
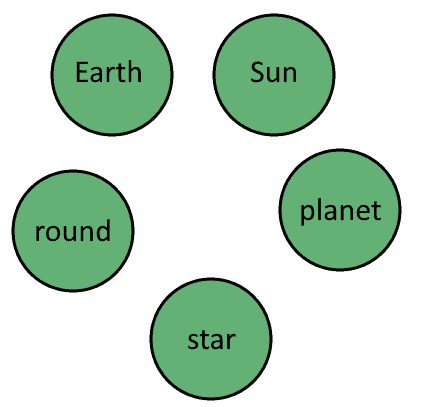
从这些三元组的前两个元素中提取出唯一实体集合,作为图中的顶点标签:
V = {地球, 太阳, 行星, 恒星, 圆形}
注意我们去除了重复项:
接下来提取唯一关系集合,即三元组第三个元素:
D = {is_a, 绕着}
这些关系构成多层图中的不同维度:
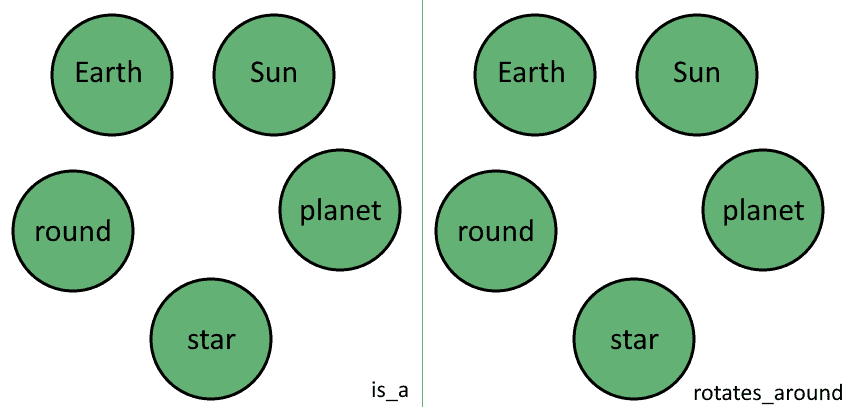
图中的所有顶点存在于所有维度中。这意味着我们有多个图层,每个图层对应不同的关系,但共享相同的顶点。
最后提取边。边与知识库中的三元组一一对应。将三元组转换为边的形式:e = (出点, 入点, 维度),规则如下:
e(u, v, d) = (主语, 宾语, 谓语)
最终得到边集合 E:
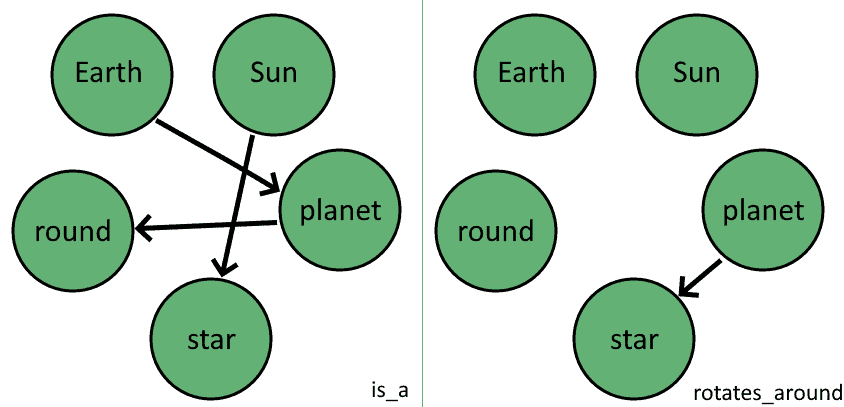
通过此过程,我们可以将任何形式为 (主语, 宾语, 谓语) 的知识库转换为形式为 G(V, E, D) 的多层图。这些多层图就是我们所说的知识图谱。
5.3 前向推理与有向路径
有趣的是,知识图谱的边与知识库中的命题一一对应:E ↔ KB。因此,如果我们能在知识图谱中发现新边,就能向知识库添加新三元组。
一种方法是:如果在某一层中存在从 u 到 v 的有向路径,则认为 u 和 v 之间存在直接边:
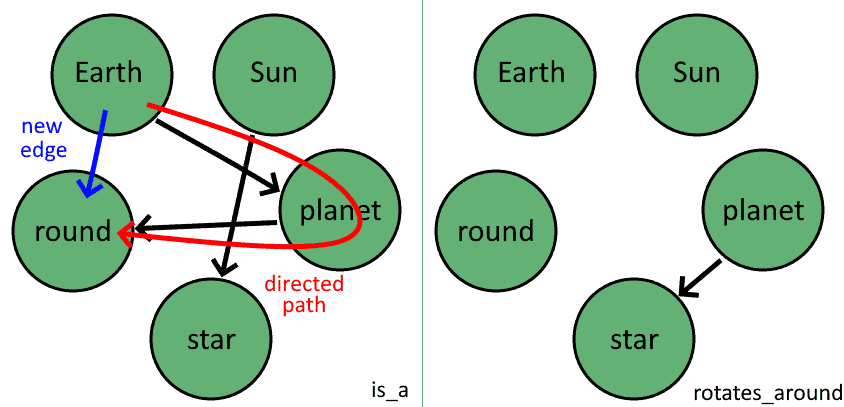
这种方法也称为前向推理。我们可以直接在三元组上应用该方法:
地球 is_a 行星 is_a 圆形 → 地球 is_a 圆形
由于知识图谱的边与知识库的三元组一一对应,因此可以在两者之间自由转换。既然我们发现了地球和圆形之间的新边,就可以向知识库中添加新三元组:
- (地球, 行星, is_a)
- (太阳, 恒星, is_a)
- (行星, 恒星, 绕着)
- (行星, 圆形, is_a)
- (地球, 圆形, is_a)
5.4 多层扩展
如果我们扩展路径定义,允许跨层连接,就可以发现跨维路径。这使得我们可以在图的不同层之间进行推理:
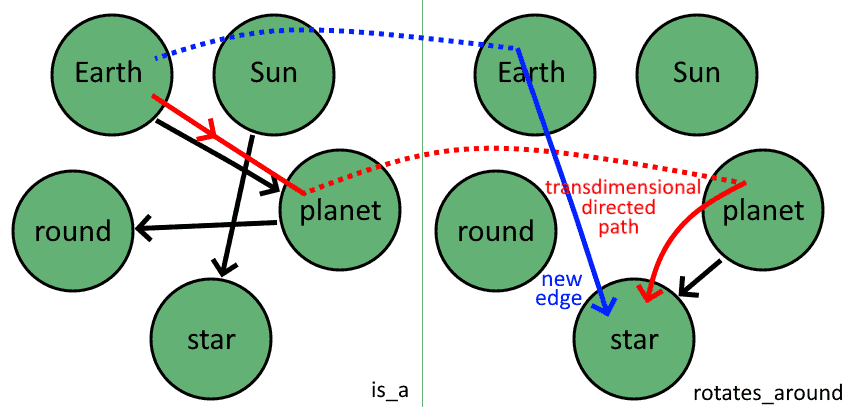
从而向知识库再添加一个三元组:
- (地球, 行星, is_a)
- (太阳, 恒星, is_a)
- (行星, 恒星, 绕着)
- (行星, 圆形, is_a)
- (地球, 圆形, is_a)
- (地球, 恒星, 绕着)
最后注意,这种方法无法学习图中不存在路径的关系。例如 (地球, 太阳, 绕着) 无法通过此方法学习,因为我们只能沿着边的方向进行推理。此时可以使用后向推理递归验证该三元组是否成立。
6. 总结
本文我们探讨了知识库、专家系统及其对应知识图谱的理论基础。
我们还演示了如何从编码命题知识的三元组集合构建知识图谱。
最后,我们学习了如何通过前向推理进行简单推断,并讨论了该方法与图路径之间的关系。