1. 引言
在本教程中,我们将介绍弱监督学习(Weakly Supervised Learning)的基本概念。首先会回顾监督学习的基本定义,然后深入讲解弱监督学习的类型及其主要应用场景。
2. 监督学习简介
在人工智能和机器学习领域,监督学习指的是使用带标签的数据集来训练机器学习或深度学习模型,从而使其能够对新数据做出预测。
模型的性能受多个因素影响,其中最重要的一点是:数据集要足够大,并且标签质量高。这种使用高质量标注数据进行训练的方式被称为强监督学习(Strong Supervision Learning)。
然而在实际中,获取大量高质量标注数据往往成本高昂或难以实现。例如:
- 需要大量领域专家参与标注
- 标注过程耗时长
- 原始数据本身存在噪声或样本有限
在这些情况下,弱监督学习就成为首选方案。
3. 弱监督学习定义
弱监督学习是机器学习的一个分支,用于在以下情况下获取更多标注数据以支持监督训练和建模:
✅ 数据量不足,无法训练出性能良好的模型
✅ 标签噪声大或来自不可靠来源
✅ 缺乏足够专家资源或获取成本过高
✅ 手动标注时间非常有限
简而言之,弱监督学习结合已有标注数据和弱监督手段来扩充训练数据集,从而提升模型表现。
4. 弱监督的类型
弱监督的目标是降低人工标注成本并增加可用标注数据的数量。它主要包括三种类型:
- 不完整监督(Incomplete Supervision)
- 不精确监督(Inexact Supervision)
- 不准确监督(Inaccurate Supervision)
4.1 不完整监督
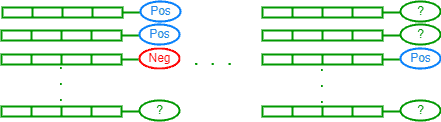
在这种类型中,只有训练数据的一部分被标注了。这部分数据通常标注准确,但不足以支撑训练出一个性能良好的模型。
应对不完整监督的常见方法包括:
- 主动学习(Active Learning)
- 半监督学习(Semi-supervised Learning)
主动学习
主动学习的目标是在最少人工干预下最大化模型性能提升。其核心在于:
- 信息量(Informativeness):使用已有标注数据训练初始模型,选择那些对模型提升最有帮助的未标注样本进行人工标注。
- 代表性(Representativeness):通过聚类等方法识别出具有代表性的未标注样本进行标注。
半监督学习
半监督学习利用未标注数据作为测试集,通过已有模型对其打标签。这种方式不依赖人工标注,但对初始模型质量要求较高。
4.2 不精确监督
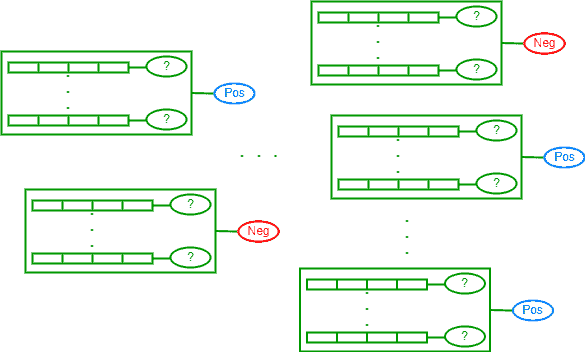
该类型中,标签是模糊的或不精确的,有时甚至存在误导性。例如,一个样本可能适用于多个标签,因为缺乏明确区分特征。
应对方式是使用多实例学习(Multi-instance Learning):
在多实例学习中,一个“包”(bag)中的多个实例共享一个标签。标签通常由“关键实例”或“多数实例”决定。
包的生成方式因任务而异,可以是图像、文本文档、股票记录等。
4.3 不准确监督
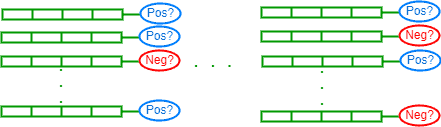
这种监督类型的特点是存在错误或低质量的标签。常见于公开数据集或众包数据。
解决思路是:
- 识别可能的错误标注样本
- 对其进行修正或删除
一种常用技术是数据编辑(Data Editing):
- 构建一个“邻域图”,每个节点代表一个样本
- 若一个节点与不同标签节点连接较多,则标记为可疑节点
- 可疑节点可被删除或重新打标签(如采用多数投票)
在众包场景中,常通过多数投票机制来提高标签准确性。
5. 弱监督的应用场景
弱监督学习不是针对某一类任务的专属方法,而是一种通用策略,适用于以下情况:
- 训练数据标注不完整或不足
- 获取高质量标注成本高
其应用领域包括但不限于:
✅ 图像分类
✅ 物体识别
✅ 文本分类
✅ 垃圾邮件检测
✅ 医疗诊断
✅ 金融预测(如房价预测)
6. 总结
在本教程中,我们介绍了监督学习与弱监督学习的基本概念,重点讲解了弱监督学习的三种主要类型:
- 不完整监督:数据标注不全,需借助主动或半监督学习扩充
- 不精确监督:标签模糊,使用多实例学习处理
- 不准确监督:标签质量差,需清洗或修正
在实际工程中,弱监督学习已成为处理标注困难问题的重要手段。对于资源有限或时间紧迫的项目,它是一个非常值得考虑的解决方案。