1. 概述
在网络通信中,网络质量的保障一直是运维人员关注的重点。为了评估和优化网络性能,通常会通过监控多种指标来分析网络状况,包括吞吐量、丢包率、抖动和 Round Trip Time(RTT)。
本文将重点讲解 Round Trip Time(往返时延) 的概念、影响因素以及优化策略。我们会先介绍一个与 RTT 密切相关的概念 —— 传播时延(Propagation Time),然后深入解析 RTT 的定义、组成以及与 ping 的区别。最后会给出一些优化 RTT 的建议。
2. 传播时延(Propagation Time)
传播时延是 RTT 中最核心的组成部分之一。
在网络通信中,传播时延指的是信号从发送端传输到接收端所需的时间,也可以称为单向时延(one-way delay)或延迟(latency)。
一个关键点是:即使同一个数据包从同一发送端发往同一接收端,传播时延也可能不一致。这是由于网络路径、设备处理、拥塞情况等因素造成的。
下图展示了传播时延的基本概念:
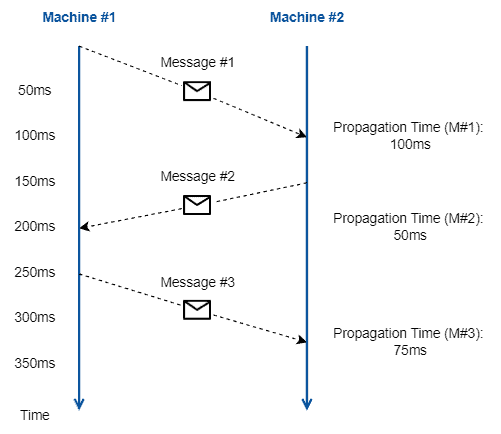
如图所示,A 到 B 的传播时延和 B 到 A 的传播时延可能不同,因此 RTT 不能简单地认为是单向传播时延的两倍。
3. Round Trip Time(RTT)
Round Trip Time(RTT)指的是从发送端发送一个数据包到接收端,并从接收端收到确认(acknowledgment)所需的时间。也可以称为 Round Trip Delay(RTD)。
在某些情况下,接收端在收到数据包后会立即返回确认,此时接收端的处理时间可以忽略不计。这时 RTT 就等于:
RTT = PT_m(从发送端到接收端) + PT_a(从接收端返回发送端)
很多人误以为 RTT 是单向传播时延的两倍,但实际情况中,返回路径可能不同,例如:
- 网络瓶颈导致返回路径延迟增加
- 返回路径经过不同的路由节点
因此,RTT 通常不等于两倍的 PT。
此外,RTT 的测量通常是在最高层协议中进行的。例如,使用 HTTPS 协议时,接收端在收到数据后可能需要先解密,然后才发送确认信息。这段额外的处理时间也会被计入 RTT。
下图展示了 RTT 的构成:
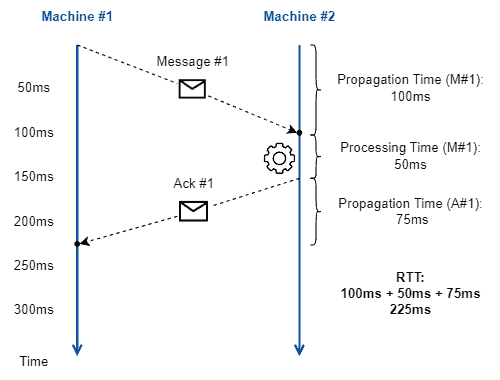
注意:RTT 是从发送端的角度测量的。因此,它对于评估服务质量(QoS)和用户体验具有重要意义。
3.1. RTT 的影响因素与优化建议
影响 RTT 的主要因素包括:
✅ 网络瓶颈:网络拥塞会增加排队、传输和处理时间,从而提高 RTT
✅ 物理距离:距离越远,信号传输路径越长,RTT 越高
✅ 传输技术:光纤、铜缆、无线等不同介质的传输速度和特性不同,会影响 RTT
为了降低 RTT,可以采取以下策略:
- 持续监控 RTT:通过监控工具了解 RTT 的变化趋势,优化路由路径和数据交换逻辑
- 系统重构:减少 DNS 请求次数(如合并域名)、保持系统更新、避免加载无效资源
- 资源本地化:使用 CDN 缩短物理距离;对于网页,启用浏览器缓存可显著减少 RTT
⚠️ 注意:由于用户地理位置和网络路径的差异,RTT 的优化需要因地制宜。系统管理员应尽可能优化连接建立和响应速度,并在用户密集区域部署资源节点。
4. RTT 与 Ping 的区别
Ping 是一个常用的网络测试工具,全称为 Packet Internet Groper。它通过 ICMP 协议向目标主机发送“Echo Request”并等待“Echo Reply”,从而测试网络连通性。
Ping 可以提供以下信息:
- 目标是否可达
- 包丢失情况
- 最小、平均、最大 RTT 值
那么问题来了:是否可以使用 ping 来准确测量任意系统的 RTT?
❌ 答案是否定的。
Ping 是基于 ICMP 的(网络层协议),而 RTT 通常是在应用层或传输层测量的。例如,HTTPS 协议中,RTT 包括了解密、处理请求等额外步骤,这些在 ICMP 中是不存在的。
✅ 但如果你对精度要求不高,ping 提供的 RTT 值可以作为一个粗略参考。
5. 总结
本文深入解析了 Round Trip Time(RTT)的概念、组成及其影响因素,并介绍了如何优化 RTT 以提升网络性能。
总结如下:
- ✅ RTT 是网络监控中非常关键的指标
- ✅ 它由两个方向的传播时延组成,不一定等于单向传播时延的两倍
- ✅ RTT 受网络拥塞、距离、传输技术等多方面影响
- ✅ 使用 CDN、减少 DNS 请求、启用缓存等手段可有效优化 RTT
- ✅ Ping 提供的 RTT 值可用于粗略估计,但不能完全替代应用层 RTT 测量
掌握 RTT 的原理和优化方法,有助于提升系统性能、改善用户体验,是每一个后端开发和运维人员都应掌握的基础能力。