1. 概述
在本篇文章中,我们将介绍“离线并发控制(Offline Concurrency Control)”的概念,并讨论两种主要实现方式:悲观离线锁(Pessimistic Offline Locking) 和 乐观离线锁(Optimistic Offline Locking) 的优缺点。
2. 背景动机
在设计应用程序时,我们通常需要允许多个用户并发访问共享数据。这种并发访问如果不加控制,就容易引发诸如 数据丢失更新(Lost Updates) 和 不一致读取(Inconsistent Reads) 等问题。
数据丢失更新
当一个事务在读取数据之后、提交更新之前,另一个事务也修改了该数据,那么前一个事务的更新就会覆盖后一个事务的更改,造成数据丢失。
例如下图中,Process A 和 Process B 同时读取了某个数据项,各自进行了修改,最终 Process B 的更新覆盖了 Process A 的修改:
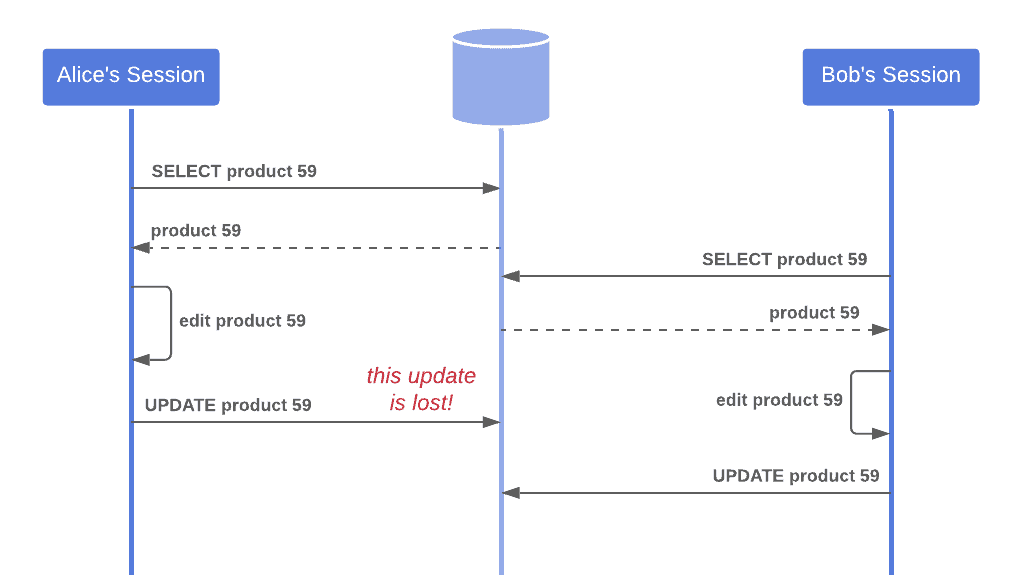
不一致读取
如果一个事务读取到了另一个事务正在修改但尚未完成的数据,就可能导致读取结果不一致。
例如下图中,Process B 正在更新数据,Process A 在此期间读取到了中间状态的数据,后续操作可能会基于这个错误的状态进行:
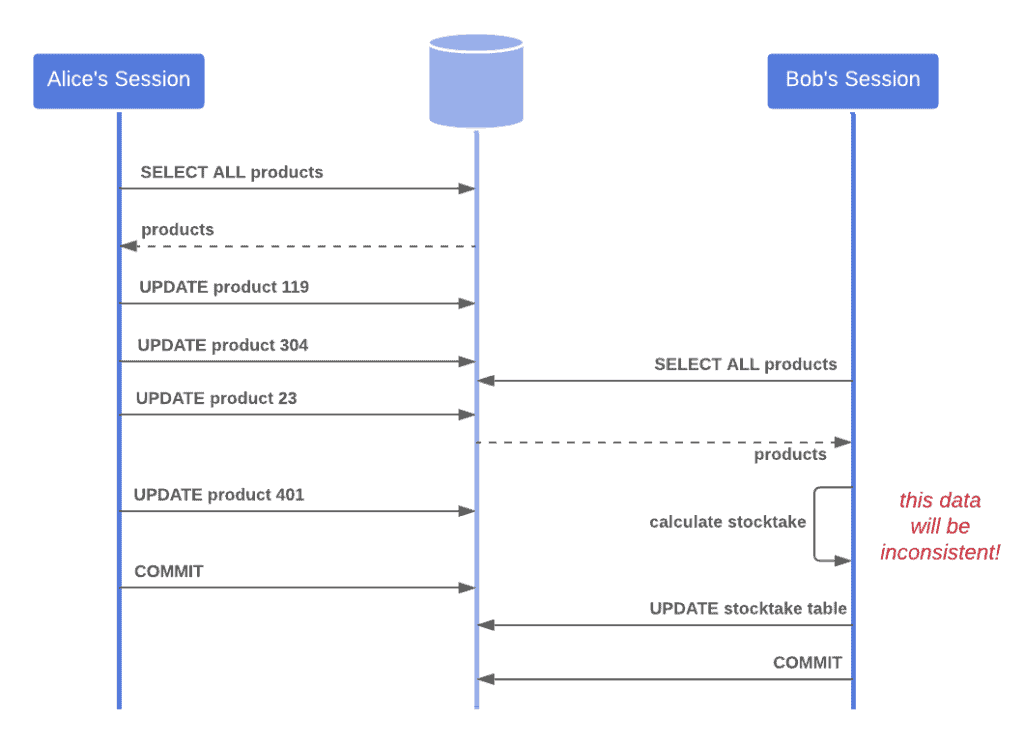
在数据库层面,通常通过事务隔离机制来处理这些问题。但在更上层的业务逻辑中,如果一个业务操作跨越多个数据库事务,传统的事务边界就无法覆盖全部范围:
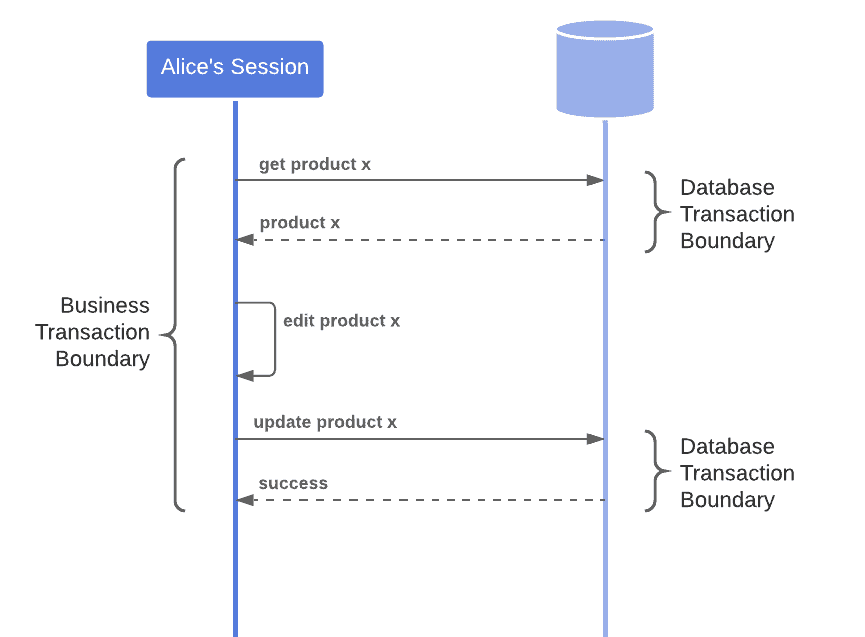
此时,我们就需要引入更高层次的并发控制机制,比如离线并发控制。
3. 什么是离线并发控制?
离线并发控制是一种用于管理跨越多个数据库事务的业务操作中并发访问数据的策略。它适用于那些业务逻辑复杂、操作周期较长、可能涉及多个数据库操作的场景。
4. 乐观离线锁(Optimistic Offline Locking)
4.1. 原理
乐观离线锁的基本思想是:允许并发操作,但在提交时检查是否发生冲突。如果发现冲突,就回滚当前事务,避免数据覆盖。
它通常通过版本号(Version Number)或时间戳(Timestamp)来实现。事务在读取数据时记录当前版本,在提交前再次检查版本是否一致,不一致则说明数据已被其他事务修改过。
✅ 优点:
- 事务提交前才加锁,减少资源阻塞
- 更适合并发度高、冲突少的场景
❌ 缺点:
- 冲突检测在提交时才进行,可能导致用户工作丢失
- 不适用于冲突频繁或操作代价高的业务流程
4.2. 实现方式
一种常见做法是在数据库表中增加一个 version 字段。例如:
ALTER TABLE orders ADD COLUMN version INT NOT NULL DEFAULT 0;
在 Java 中使用 JPA 时,可以通过 @Version 注解来启用乐观锁:
@Entity
public class Order {
@Id
private Long id;
private String status;
@Version
private int version;
// getters and setters
}
当两个事务同时尝试更新同一个 Order 实体时,只有第一个提交的事务会成功,第二个事务会抛出 OptimisticLockException。
流程图如下:
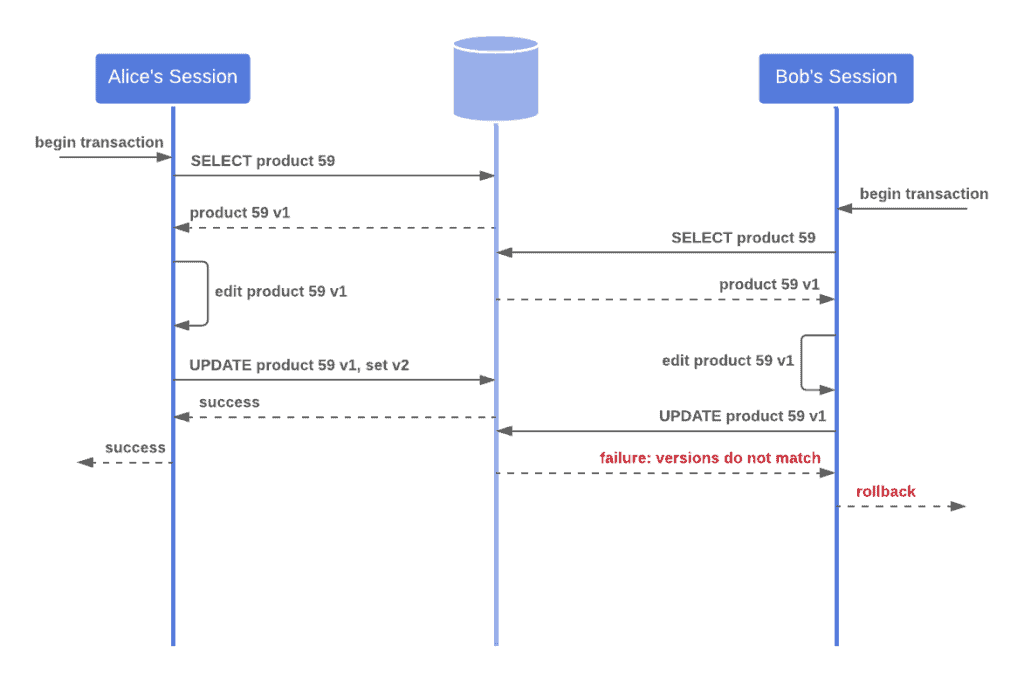
如需完整实现,可参考 使用 JPA 和 Hibernate 实现乐观锁
4.3. 使用场景
✅ 推荐在以下情况下使用:
- 业务流程较短,冲突概率低
- 系统追求高并发和低锁竞争
- 用户操作可以容忍偶尔的失败重试
⚠️ 不推荐在以下情况下使用:
- 操作流程复杂,重试代价高
- 数据冲突频繁,失败率高
- 用户体验要求严格,不能容忍中途失败
5. 悲观离线锁(Pessimistic Offline Locking)
5.1. 原理
悲观离线锁的基本思想是:在事务开始时就对数据加锁,防止其他事务修改。这种方式避免了冲突的发生,而不是在冲突发生后处理。
它适用于业务流程长、数据修改频繁、且冲突代价高的场景。
✅ 优点:
- 提前加锁,避免事务失败
- 适用于数据修改频繁、冲突概率高的场景
❌ 缺点:
- 阻塞其他事务,影响系统并发性能
- 实现复杂,需额外管理锁状态
5.2. 实现方式
要实现悲观离线锁,通常需要以下几个关键点:
锁类型选择:
- 独占读锁(Exclusive Read Lock):读写都需要加锁
- 独占写锁(Exclusive Write Lock):只写需要加锁
- 读写锁(Read/Write Lock):允许多个读锁,写锁互斥
锁管理器(Lock Manager):需要一个组件来管理锁的申请和释放,比如使用数据库表、内存结构或分布式锁服务。
示例实现流程如下图所示:
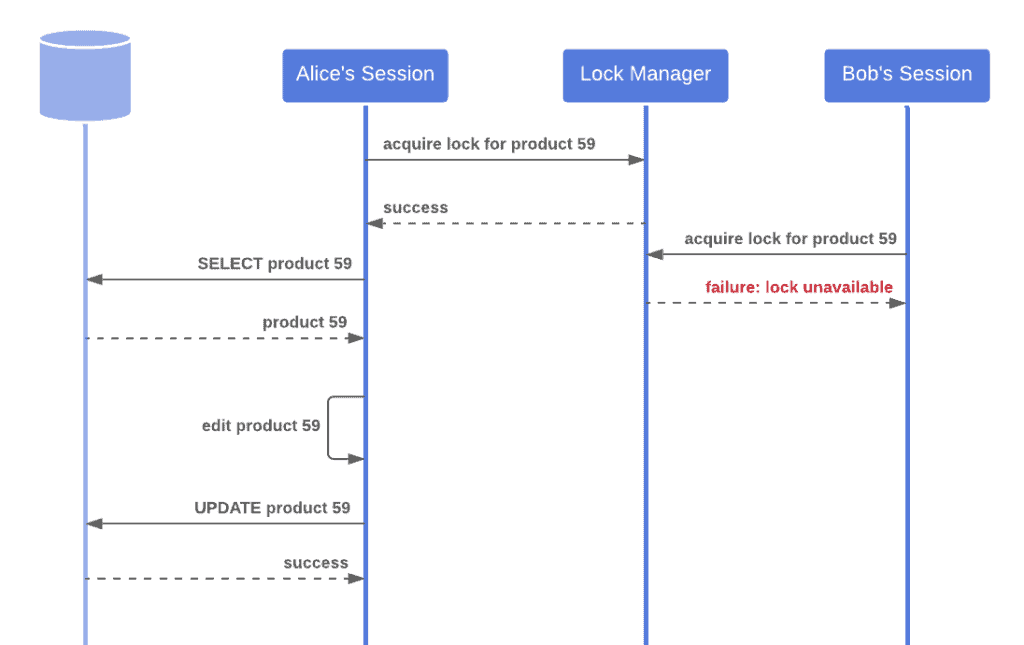
在 Java 中使用 JPA 和 Hibernate 实现悲观锁,可以使用 LockModeType.PESSIMISTIC_WRITE 或 PESSIMISTIC_READ:
Order order = entityManager.find(Order.class, orderId, LockModeType.PESSIMISTIC_WRITE);
如需完整实现,可参考 使用 JPA 和 Hibernate 实现悲观锁
5.3. 使用场景
✅ 推荐在以下情况下使用:
- 业务流程复杂,操作步骤多
- 数据冲突频繁,冲突代价高
- 用户不能容忍操作中途失败
⚠️ 不推荐在以下情况下使用:
- 系统并发要求高,锁竞争激烈
- 锁实现复杂,维护成本高
- 冲突概率低,乐观锁更合适
6. 总结
离线并发控制是处理跨越多个数据库事务的并发访问问题的重要手段。两种主要策略各有优劣:
| 特性 | 乐观离线锁 | 悲观离线锁 |
|---|---|---|
| 加锁时机 | 提交时检查冲突 | 事务开始时加锁 |
| 并发性 | 高 | 低 |
| 数据一致性 | 仅防止丢失更新 | 可防止不一致读和丢失更新 |
| 实现复杂度 | 简单 | 复杂 |
| 适用场景 | 冲突少、流程短 | 冲突多、流程长 |
在实际项目中,应根据业务需求、数据变更频率和用户体验来选择合适的策略。如果你的业务操作周期长、步骤多,且数据冲突代价高,悲观锁是更好的选择;反之,如果冲突较少,乐观锁则更轻量、高效。
✅ 踩坑提醒:不要盲目选择乐观锁,尤其在用户操作耗时较长、数据频繁变更的业务场景中,乐观锁可能导致大量事务回滚,反而影响用户体验。