1. 引言
在本文中,我们将探讨为什么 Prim 算法 和 Kruskal 算法 不能直接用于 有向图(Directed Graph)。这两个算法原本是为 无向图 设计的,用于寻找最小生成树(Minimum Spanning Tree, MST)。但当我们将其应用在有向图上时,会遇到一些根本性的问题。
2. 最小生成树(MST)
Prim 和 Kruskal 算法都用于在 无向图 中找到最小生成树(Minimum Spanning Tree, MST)。MST 是一个子图,它包含图中所有顶点,并且连接这些顶点的边的总权重最小。
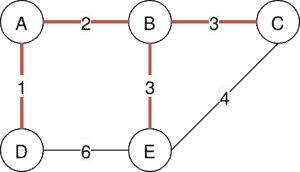
例如,下图展示了总权重为 9 的 MST:
2.1. Kruskal 算法
Kruskal 算法适用于 无向、加权、连通图。其基本思路如下:
✅ 初始化一个空集合 S
✅ 按权重从小到大依次选择边,加入 S,但要确保加入后不形成环
✅ 直到 S 形成一棵生成树
⚠️ 问题在于:在有向图中判断环的逻辑与无向图不同。如果直接使用 Kruskal 算法,可能会漏判环或误判结构,导致无法正确构建最小生成树。
2.2. Prim 算法
Prim 算法从任意一个顶点出发,逐步选择连接当前树的最小权重边。其伪代码如下:
algorithm PrimsAlgorithm:
// INPUT
// G = an undirected, weighted, and connected graph
// OUTPUT
// T = the minimal spanning tree of G
T <- create an empty tree
Set a random node r as the root of T
Q <- initialize a priority queue
// Let cost(u) be the distance of node u to T
// Initially, cost(u) = weight(u, r) for u in the neighbors of r
// and cost(u) = infinity for every other node.
Insert the nodes of G into Q except the root
while Q is not empty:
u <- pop from Q the closest node to T (not already in T)
Add the corresponding edge to T
for v in the neighbors of u:
if v not in T and weight(u, v) < cost(v):
cost(v) <- weight(u, v)
Prim 算法与 Dijkstra 算法有些相似,但它只关注当前边的权重,而不是整条路径。
⚠️ 问题在于:Prim 算法在有向图中可能选择错误的边方向,导致无法形成有效生成树。
2.3. 算法对比
| 特性 | Kruskal 算法 | Prim 算法 |
|---|---|---|
| 适合稀疏图 | ✅ | ❌ |
| 实现难度 | ✅ | ❌ |
| 适合稠密图 | ❌ | ✅ |
3. 问题示例
虽然算法本身不会因为输入是有向图而报错,但在某些情况下会返回错误的结果。
3.1. 有向树(Arborescence)问题
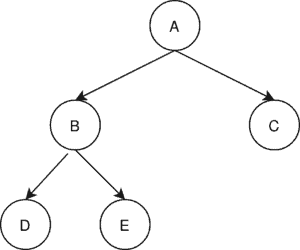
在有向图中,我们通常寻找的是 最小生成有向树(Minimum Spanning Arborescence, MSA),即从一个根节点出发,存在到其他所有节点的路径。
例如,下图是一个 MSA:
3.2. Kruskal 算法失效示例
考虑以下有向图:
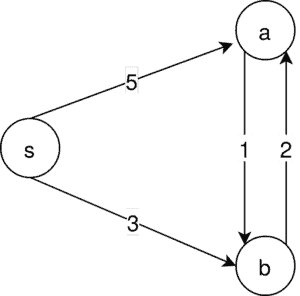
唯一可能的 MSA 是 s → b → a,但 Kruskal 算法会先选 a → b,如下图所示:
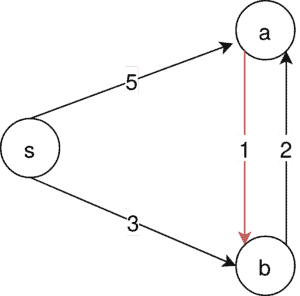
⚠️ 由于 a → b 不在 MSA 中,Kruskal 算法无法构造出正确的生成树。
3.3. Prim 算法失效示例
考虑以下有向图:
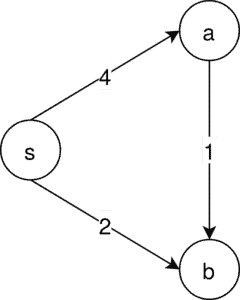
唯一可能的 MSA 是 s → a → b,但 Prim 算法会从 s 出发选择权重最小的 s → b,如下图所示:
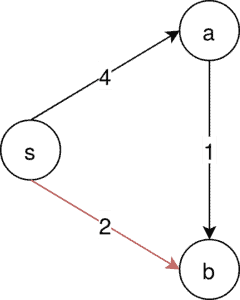
⚠️ 由于 s → b 不在 MSA 中,Prim 算法也无法构造出正确的生成树。
4. 替代方案:Chu–Liu / Edmonds’ 算法
4.1. 算法概述
Chu–Liu / Edmonds’ 算法是专为 有向图 设计的,用于构造 最小生成有向树(MSA)。其核心思想是通过递归地消除图中的环来构造生成树。
流程如下图所示:
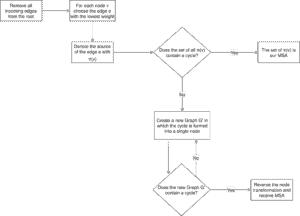
- 删除所有指向根节点的边(因为 MSA 的根节点没有入边)
- 为每个节点选择入边中权重最小的边
- 判断是否已形成 MSA,若未形成则递归消除环
4.2. 消除环的步骤
在图中存在环时,我们可以将环压缩为一个节点,然后递归处理。具体步骤如下:
- 对于边
(u, v),若v在环C中,创建新边(u, v_c),权重为w(u, v) - w(π(v), v),其中π(v)表示v的最小入边来源。 - 若
u在环C中,v不在,则创建新边(v_c, v),权重为w(u, v)。 - 其他边保持不变。
通过不断压缩环,直到图中无环为止,最终得到一个无环图 G',即为 MSA。
最后,将压缩的节点还原为原始节点,即可得到最终的 MSA。
4.3. 时间复杂度分析
- 最坏情况下,每个节点都要遍历所有边,因此时间复杂度为 O(VE)
- 使用更高效的数据结构(如 Fibonacci Heap),可优化为 O(E log V)
5. 总结
- ✅ Prim 和 Kruskal 算法是为无向图设计的,不能直接用于有向图
- ❌ 在有向图中使用它们可能导致无法构造出正确的最小生成树
- ✅ Chu–Liu / Edmonds’ 算法是专门用于有向图的替代方案,能构造出最小生成有向树(MSA)
如果你在项目中遇到需要处理有向图的 MST 问题,记得不要直接套用 Prim 或 Kruskal,而是考虑使用 Chu–Liu / Edmonds' 算法。