1. 简介
在本文中,我们将探讨 Q-Learning 与 动态规划(Dynamic Programming, DP) 之间的主要区别。两者都属于强化学习中的算法类别,目标是根据给定的环境构建模型,并生成策略(policy),从而决定哪些动作能带来最优结果。
2. 动态规划
要使用动态规划算法,我们需要一个有限马尔可夫决策过程(MDP)来描述环境。也就是说,我们必须知道动作在不同状态之间转移的概率。动态规划的结果是确定性的:我们通过算法得到的策略每次都是一样的。此外,它通常能保证收敛。
为了更好地理解这个抽象的概念,我们来看一个例子。
2.1. 动态规划示例
一个简单的MDP例子是描述婴儿的状态变化:
- 婴儿可能处于:睡眠、平静、哭泣、快乐等状态。
- 在“睡眠”和“平静”状态下,可以选择“唱歌”或“等待”两种动作。
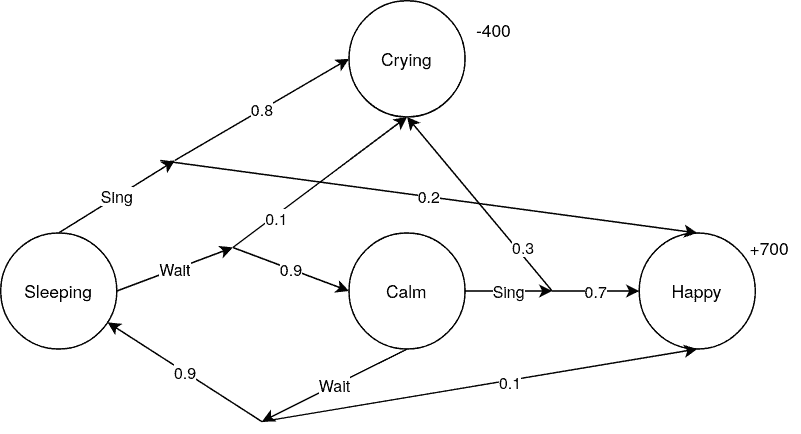
在这个模型中,所有状态转移的概率都是已知的。例如:
- “等待”动作让婴儿开心的概率较低,哭泣的概率也低;
- “唱歌”动作虽然有更高的概率让婴儿开心,但也可能引发哭泣。
我们最终的目标是找到一个策略  ,告诉我们在哪个状态下应该选择哪个动作。为此,我们引入价值函数:
,告诉我们在哪个状态下应该选择哪个动作。为此,我们引入价值函数:
$$ V^\pi(s) = E_{\pi} {G_t \vert s_t = s} $$
这个函数表示:从状态 $ s $ 出发,遵循策略 $ \pi $ 所能获得的期望回报。
2.2. 使用动态规划解决该问题
为了解决这个MDP问题,我们需要得到一个策略 $ \pi $,告诉我们每个状态下该采取什么动作。我们通常使用 值迭代(Value Iteration) 算法来求解。
✅ 值迭代通过迭代优化价值函数 $ V $,从一个初始值开始逐步更新。
动态规划的一个重要特性是:将问题拆解为更小的子问题分别求解。例如,我们可以先找出从“平静”到“快乐”的最优策略,再找出从“睡眠”到“快乐”的最优策略,然后将它们组合起来解决整个问题。
2.3. 动态规划的应用场景
- 渔业管理:在保证鱼类种群可持续的同时最大化捕捞量。我们已知鱼群增长与减少的规律,适合建模为MDP。
- 在线营销:通过分析用户行为(如点击、购买)建模用户从“未感兴趣”到“购买并满意”的状态转移。
- ✅ 金融领域:由于其监管严格、数据透明,动态规划的确定性优势尤为明显。
3. Q-Learning
Q-Learning 不需要完整的MDP模型,它通过试错的方式学习最优策略。它只关注动作带来的奖励,而不是状态转移的概率。
3.1. Q-Learning 示例
我们仍以婴儿的状态为例,但这次我们不知道状态转移的概率,也不知道每个动作会导向哪个状态:
这在现实中更常见:我们往往只知道做了某件事后的结果,但不知道概率分布。
3.2. 使用 Q-Learning 解决该问题
Q-Learning 的核心思想是:将未来的奖励反向传播到前面的步骤上,从而形成一条通往高奖励的路径。我们通过一个 Q-Table 来记录每个状态-动作对的预期奖励值。
初始 Q-Table 示例:
| Sing | Wait | |
|---|---|---|
| Sleeping | 77 | 71 |
| Calm | 70 | 55 |
| Crying | -400 | -400 |
| Happy | 700 | 700 |
我们根据以下公式更新 Q 值:
$$ Q^{new}(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \cdot \left( r_t + \gamma \cdot \max_a Q(s_{t+1}, a) - Q(s_t, a_t) \right) $$
其中:
- $ s_t $:当前状态
- $ a_t $:当前动作
- $ \alpha $:学习率(控制新信息覆盖旧信息的程度)
- $ \gamma $:折扣因子(控制未来奖励对当前状态的影响)
- $ Q(s_{t+1}, a) $:下一状态的预期奖励
在我们的例子中,经过多次尝试后,Q-Table 最终可能变成:
| Sing | Wait | |
|---|---|---|
| Sleeping | -134 | 425 |
| Calm | 590 | -36 |
| Crying | -400 | -400 |
| Happy | 700 | 700 |
由此我们可以看出:
- 在“睡眠”状态应选择“等待”
- 在“平静”状态应选择“唱歌”
3.3. Q-Learning 流程图
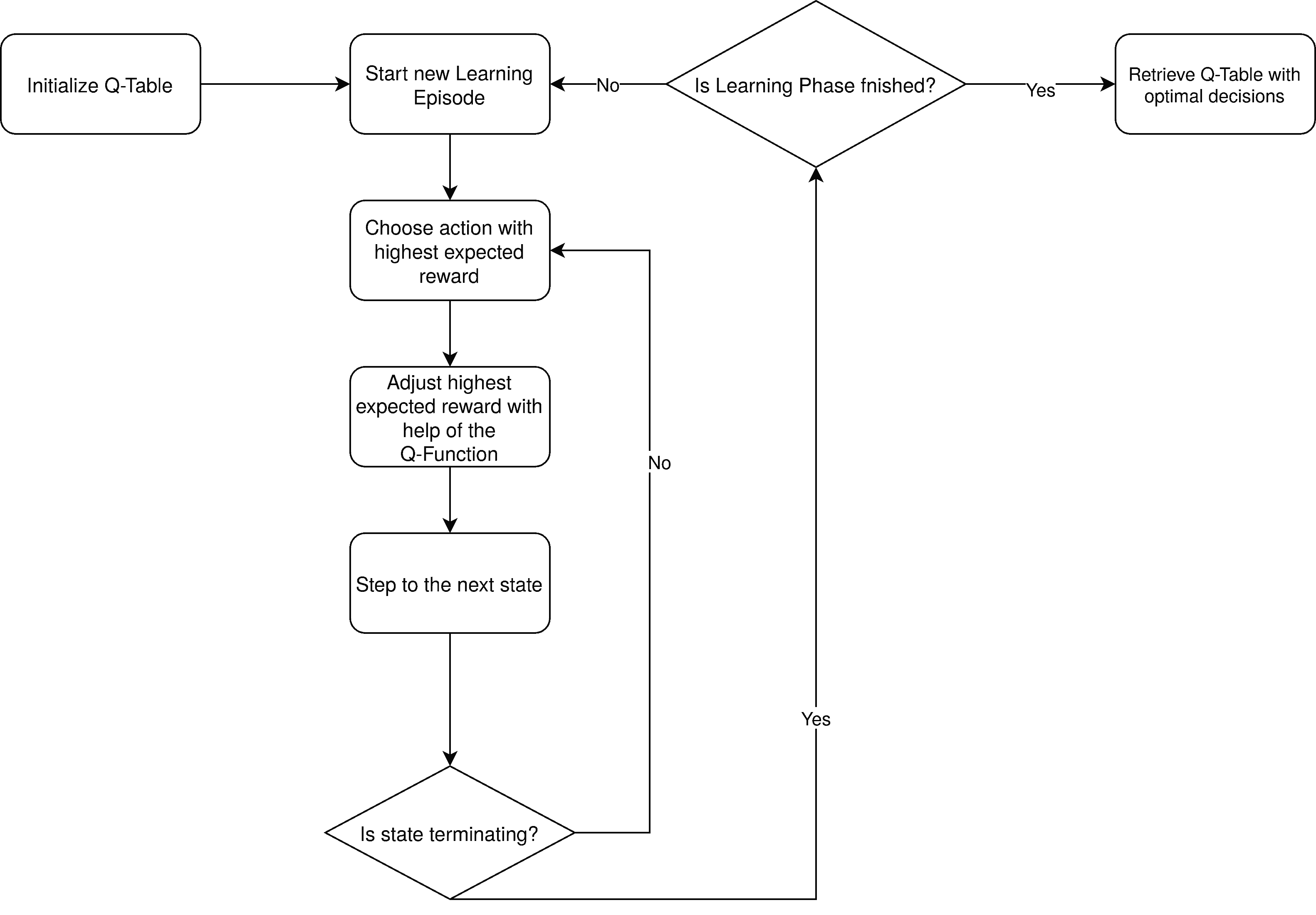
流程如下:
- 初始化 Q-Table
- 开始训练回合(episode)
- 根据当前 Q 值选择动作
- 执行动作并观察奖励与新状态
- 更新 Q 值
- 若进入终止状态,则重置环境,开始下一个回合
- 所有回合结束后,根据 Q-Table 生成策略
3.4. Q-Learning 应用场景
- ✅ 游戏AI:如 AlphaGo、OpenAI Five,通过与环境交互学会下棋或打游戏
- ✅ 机器人学习走路:物理过程复杂,难以建模为MDP,Q-Learning 更适合
- ✅ 资源调度:当状态转移概率未知或变化频繁时,Q-Learning 更灵活
4. 两种方法的对比
| 特性 | 动态规划 | Q-Learning |
|---|---|---|
| 是否需要MDP模型 | ✅ 是 | ❌ 否 |
| 是否需要状态转移概率 | ✅ 是 | ❌ 否 |
| 是否确定性 | ✅ 是 | ❌ 否 |
| 是否依赖环境交互 | ❌ 否 | ✅ 是 |
| 收敛性 | ✅ 是 | ❌ 不一定 |
| 适用场景 | 状态转移已知、确定性强 | 状态转移未知、需试错 |
5. 与其他机器学习算法的对比
DP 和 Q-Learning 都属于强化学习范畴,目标是最大化奖励。与之对比的其他机器学习方法如:
- SVM、神经网络:依赖已有数据集,进行预测或分类
- ✅ Deep Q-Learning:结合Q-Learning与神经网络,解决Q-Table过大问题
⚠️ Q-Table在状态空间巨大时会变得不切实际(如包含时间、位置等连续变量),此时使用神经网络代替Q-Table更为高效。
6. 总结
- ✅ 动态规划适用于已知状态转移概率的环境,结果确定,适合建模清晰的场景。
- ✅ Q-Learning适用于状态转移未知或复杂的情况,通过试错学习,灵活性强。
- ⚠️ Q-Learning 不保证收敛,训练过程可能不稳定。
- ✅ 两者都要求定义状态、动作和奖励,但Q-Learning对环境模型的依赖更低。
在实际项目中,如果你对环境有充分了解,且状态空间不大,可以优先考虑动态规划;如果你面对的是一个复杂、未知或不断变化的系统,Q-Learning 或其变体(如 Deep Q-Learning)会是更合适的选择。